扫码关注量子位
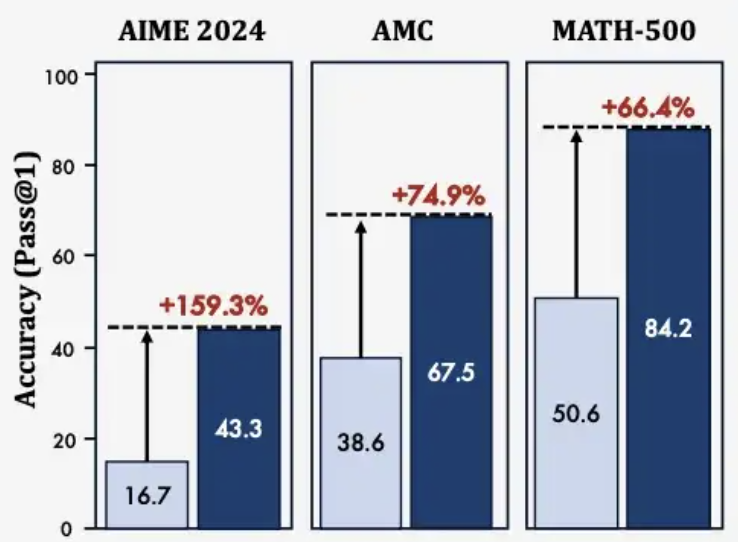
AIME 2024准确率提升159%
将强化学习训练扩展到医学、化学、法律、心理学、经济学等多学科
基于动态强化学习
准确率提升31%
大模型数学推理任务面临”三重门”困局。
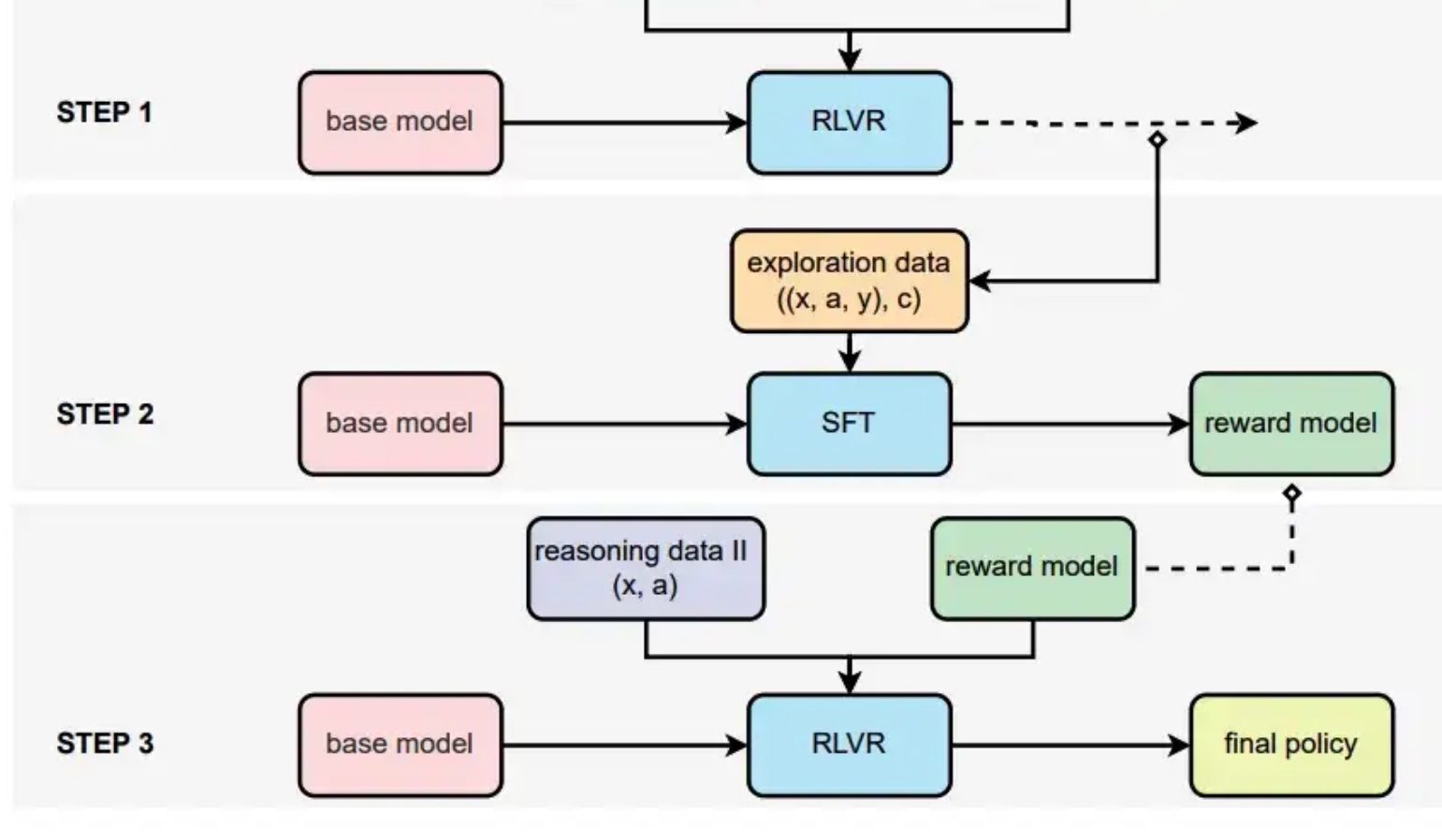
新的结合过程奖励的强化学习方法
灵初智能将从2B服务业切入
全程无需人类反馈
舍弃强化学习
有“情感”会卖萌,还能应对偷袭
空中F1
最高可取得人类5倍成绩
新成员AlphaDev登场
来自RoseTTAFold团队
不靠攻略和“外挂”
还打算给它看100万小时视频
说起来你可能不信,训练AI司机跟驯猫是一个道理……
用的机械狗还是中国牌子的(doge)
程序员:跟不上AI步伐了