扫码关注量子位
大模型最佳表现不及人类一半
提升AIGC内容生成尤其是声音生成方面的质量和智能化水平
开启多模态AI新范式
Llama含金量还在上升
大模型重构一切,出海电商已经率先感受到了
CLIP改造而来
从“A股AI视觉第一股“到”多模态落地先行者”
期待后续多模态大模型的研究和发展更加关注多语种场景
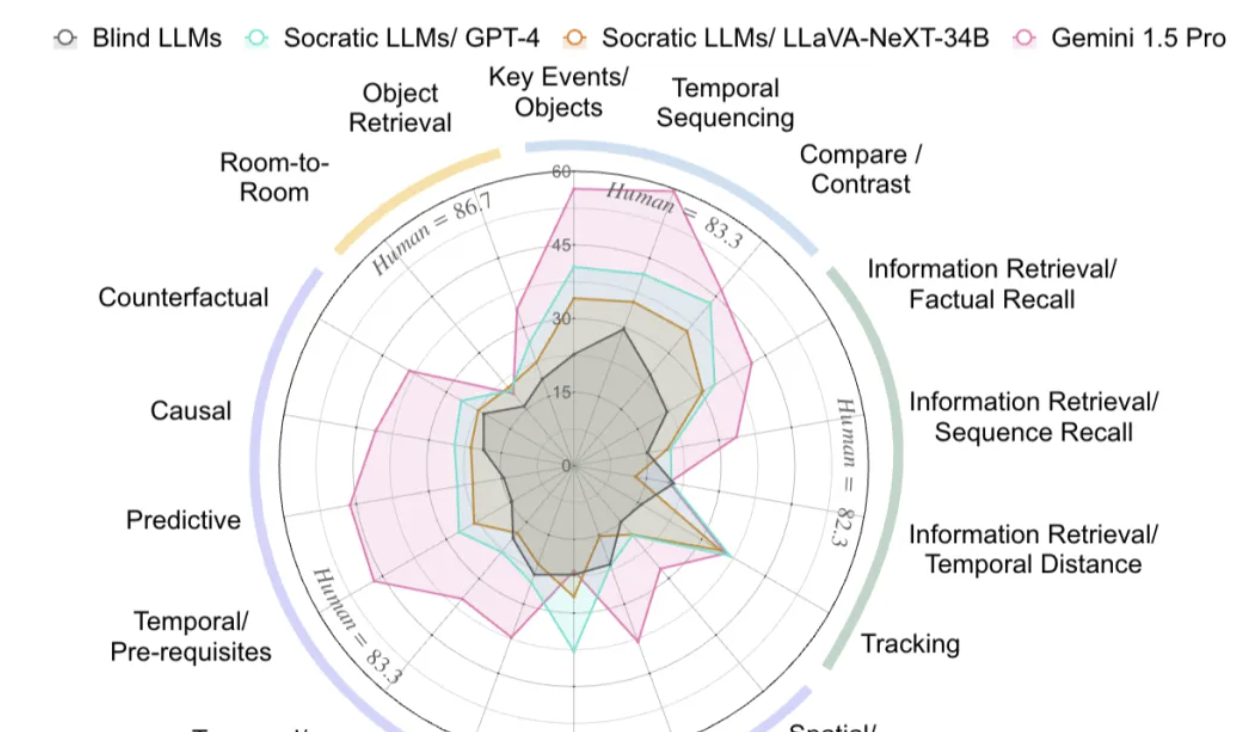
全面评估多模态大模型的综合视频理解能力
全程无需人类反馈
“一图胜千言”—— one image token >> one text token。
无需额外训练,性能大幅提升
在线可玩
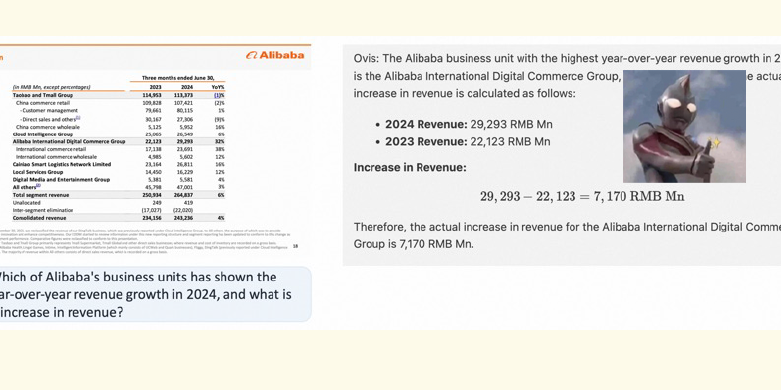
接近商业闭源模型水平
“技术驱动的多模态交互Native产品将形成新的产品习惯”
长文本、多模态、工作流,钉钉AI上大分
甚至部分指标比13B的模型还要好
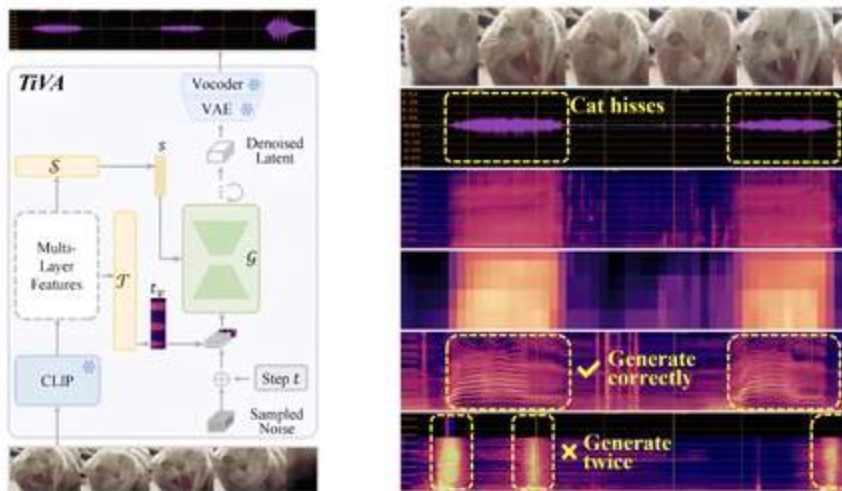
首创基于多模态大模型的音乐理解与生成框架
自动驾驶新解法
视觉+音频双模态相辅相成