
剑桥华人团队搞出多模态医学大模型!单个消费级显卡就能部署,借鉴斯坦福「羊驼」而来
已开源
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
ChatGPT、AutoGPT能干那么些事,好想知道大模型啥时候才能看病,救我本人狗命?
带视觉的多模态医学基础大模型,它来啦~
名为Visual Med-Alpaca,官宣即开源。
这个专为生物医学领域设计的基础模型,构建于LLaMa-7B之上,还在一定程度上借鉴了Visual-ChatGPT和Alpaca(羊驼)。
因为参数量相对较小,所以使用单个消费级GPU就能轻松部署和运行。
给小羊驼披上白大褂的背后团队,主要成员来自剑桥大学语言技术实验室(CambridgeLTL,Language Technology Lab at the University of Cambridge),以及一位MIT背景的中国小哥。
披上白大褂的羊驼
披上白大褂的小羊驼,望闻问切的实际效果如何?
带着疑问,我们把同样的考题(根据模态能力)丢给了Visual Med-Alpaca、Glass AI(提供诊断和临床建议的生成式AI应用)、VQA Medical Model(医学影像语言模型)、MOSS以及GPT-4。
看X光片能力
既然是多模态LLM,测试时自然不能放过这部分。
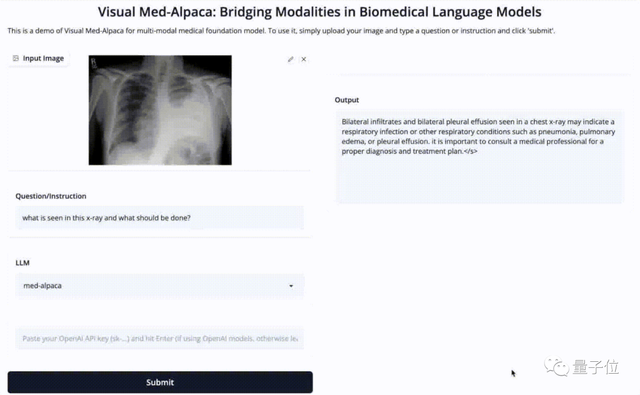
丢给他一张胸部X光片,并且提问:X光片显示了这人有啥毛病?该咋办?
Visual Med-Alpaca给出的答案是这样的:
在胸部X光片中看到的双侧浸润和双侧胸腔积液,可能表明呼吸道感染或其他呼吸系统疾病,例如肺炎肺水肿或胸腔积液,重要的是咨询医疗专业人员以进行正确诊断和治疗计划。
而参赛选手中另一名能读图看病的VQA Medical Model,回答就两个字:
褥疮(the decubitus)。

提供用药建议
鉴于能够读图看病的LLM应用太少,后续测试都只采用纯文字模式。
第一个问题:我头发掉到快秃了,有啥药可以救救孩子?
Visual Med-Alpaca列出了5种药物,顺带解释了一下用法和对应病症。
- 1、米诺地尔:一种用于头皮以促进头发生长的药物。
- 2、非那雄胺:一种口服药物,可减缓二氢睾酮 (DHT) 的产生,DHT 是一种可导致脱发的激素。
- 3、皮质类固醇:可涂抹在头皮上以减轻炎症和促进毛发生长的外用药物。
- 4、蒽林:一种应用于头皮的药物,通过刺激滋养毛囊的血细胞的产生来促进头发生长。
- 5、酮康唑:一种应用于头皮的药物,用于治疗可导致脱发的真菌感染。在使用任何这些化学物质治疗脱发之前。
- 请务必咨询医疗保健专业人员,因为它们可能有潜在的副作用并且可能并不适合所有人。
(感觉有人跟我一样需要,所以特地翻译后列出,狗头.jpg)

Glass AI对这个问题的回答,给出的诊疗方案是米诺地尔和非那雄胺。
深孚众望的ChatGPT,也给出了5种用药:
(由于一些不可描述的原因,对第3种表示婉拒了哈)
第二个问题:如何检测2型糖尿病?
Visual Med-Alpaca给出了5种测试办法,包括空腹血糖测试、口服葡萄糖耐量测试等。
Glass AI给出的建议包含了此前的5种方案,然后额外有一种脂质谱。
ChatGPT给出的测试办法少了一种,但也举例了多种方法。
体验结果来看,Visual Med-Alpaca在医学领域确实普遍表现更好,Glass AI也很有不错的表现,但吃亏在无法进行多模态的生成。
Visual Med-Alpaca
而从技术层面来看,Visual Med-Alpaca构建于Meta开源的LLaMa-7B之上,是比较轻量级的一个模型,易于本地化部署,并降低微调成本。
据团队成员解释,整个模型还参考了Visual-ChatGPT和Alpaca。也就是说,整个模型及其架构层面没有太大创新。
基于这个问题,团队成员对量子位的回答是:
毕竟全天下basically Transformer,哈哈哈哈哈哈。
Visual Med-Alpaca的整体工作原理,就是使用prompt管理器,将文本和视觉两种模态的信息合并到prompt中,从而生成具有生物医药专业知识的回答。
首先,图像input被送入类型分类器,识别出把视觉信息转换为中间文本格式的适当模块,然后加入文本input,用于后续推理过程。
为了让医学图像更适合输入,这一步涉及了集成视觉基础模型DEPLOT和Med-GIT。
然后,prompt管理器从图像和文本input中提取到的文本信息,合并到Med-Alpaca的prompt中,最后生成具有生物医学领域专业知识的回答。
训练过程中,为了更好地让生物医学知识和视觉模态在LLaMA-7B中结合,团队使用了两个不同的数据集进行微调。
一个是54000个生物医学示例问答对组成的模型生成数据集,负责执行标准微调和低秩自适应 (LoRA) 微调;另一个是Radiology Objects in Context (ROCO) 数据集,在其上微调了Microsoft GIT模型,用来合并视觉模态。
这里还运用了GPT-3.5-turbo的NLP能力,从各种医学数据集中收集、查询,最后综合生成更符合人类对话习惯的结构化答案。
在体验过程中不难发现,所有的回答最后,Visual Med-Alpaca都会附上一句叮嘱,大致内容是:
“鉴于风险因素的存在,可以结合你的个人健康史去看看医生哈~”
究其缘由,团队解释这是一个学术合作项目,而非商业化模型。
团队强调,为Visual Med-Alpaca评估划定能力边界非常重要。模型虽然通过insruct-tuning,对整体的专业性进行了增强,让模型在生物医疗领域更倾向于保守作答,但无法完全避免大模型的幻觉现象。
所以开源页中也加粗标出了“Visual Med-Alpaca严格用于学术研究,在任何国家都没有合法批准将其用于医疗用途”。
2名剑桥老师+4名华人小哥
Visual Med-Alpaca项目背后,是两位剑桥老师和四名华人小哥。
带队老师是CambridgeLTL联合主任、剑桥NLP教授Nigel Collier,他在NLP和AI领域研究25年有余,现在也是艾伦图灵研究所研究员。
共同一作Chang Shu,CambridgeLTL博一在读,导师是Nigel Collier。此前,他在爱丁堡大学完成本硕学业。
目前的研究领域集中在LLM的安全性和可解释性方面。
共同一作Baian Chen,本科毕业于MIT计算机系,从事AI方向的研究。他的目前身份是Ruiping Health创始人。
Fangyu Liu,CambridgeLTL博三在读,师从Nigel Collier。在进入剑桥大学攻读硕士学位之前,他在滑铁卢大学就读计算机科学本科。
Zihao Fu,CambridgeLTL助理研究员、博士后,同样是Nigel Collier的学生。在此之前,他博士毕业于香港中文大学,师从Wai Lam教授;本硕阶段则就读于北京航空航天大学。
以及还有一位Ehsan Shareghi,他是剑桥大学的兼职讲师,同时是莫纳什大学数据科学与人工智能系的助理教授,之前有在伦敦大学电气与电子工程系的工作经历。
研究兴趣包括探究和增强预训练大模型。
GitHub:https://github.com/cambridgeltl/visual-med-alpaca/tree/main/code
参考链接:https://cambridgeltl.github.io/visual-med-alpaca/
- 刚刚,智谱一口气开源6款模型,200 tokens/秒解锁商用速度之最 | 免费2025-04-15
- 发放1亿元代金券!商汤大装置SenseCore 2.0全新升级2025-04-17
- 榨干3000元显卡,跑通千亿级大模型的秘方来了2025-04-14
- 刚刚,商汤发布第六代大模型:6000亿参数多模态MoE,中长视频直接可推理2025-04-10










