
ICLR 2022|唯快不破!面向极限压缩的全二值化BiBERT
证明了BERT模型全二值化可行性
作者 秦浩桐
量子位 转载 | 公众号 QbitAI
近年来,预训练语言模型在自然语言处理上表现出色,但其庞大的参数量阻碍了它在真实世界的硬件设备上的部署。
近日,机器学习顶会ICLR 2022接收论文结果已经正式公布,至少有9项工作展示了神经网络量化方向的相关进展。
本文将介绍首个用于自然语言任务的全二值量化BERT模型——BiBERT,具有高达56.3倍和31.2倍的FLOPs和模型尺寸的节省。
这项研究工作由北京航空航天大学刘祥龙教授团队、南洋理工大学和百度公司共同完成。

预训练语言模型在自然语言处理上表现出色,但其庞大的参数量阻碍了它在真实世界的硬件设备上的部署。
现有的模型压缩方法包括参数量化、蒸馏、剪枝、参数共享等等。
其中,参数量化方法高效地通过将浮点参数转换为定点数表示,使模型变得紧凑。
研究者们提出了许多方案例如Q-BERT[1]、Q8BERT[2]、GOBO[3]等,但量化模型仍旧面临严重的表达能力有限和优化困难的问题。
幸运的是,知识蒸馏作为一种惯用的辅助优化的手段,令量化模型模仿全精度教师模型的特征表达,从而较好地解决精度损失问题。
在本文中,来自北航、NTU、百度的研究人员提出了BiBERT,将权重、激活和嵌入均量化到1比特(而不仅仅是将权重量化到1比特,而激活维持在4比特或更高)。
这样能使模型在推理时使用逐位运算操作,大大加快了模型部署到真实硬件时的推理速度。
我们研究了BERT模型在二值化过程中的性能损失,作者在信息理论的基础上引入了一个高效的Bi-Attention(二值注意力)机制,解决前向传播中二值化后的注意力机制的信息退化问题;提出方向匹配蒸馏(Direction-Matching Distillation)方法,解决后向传播中蒸馏的优化方向不匹配问题。
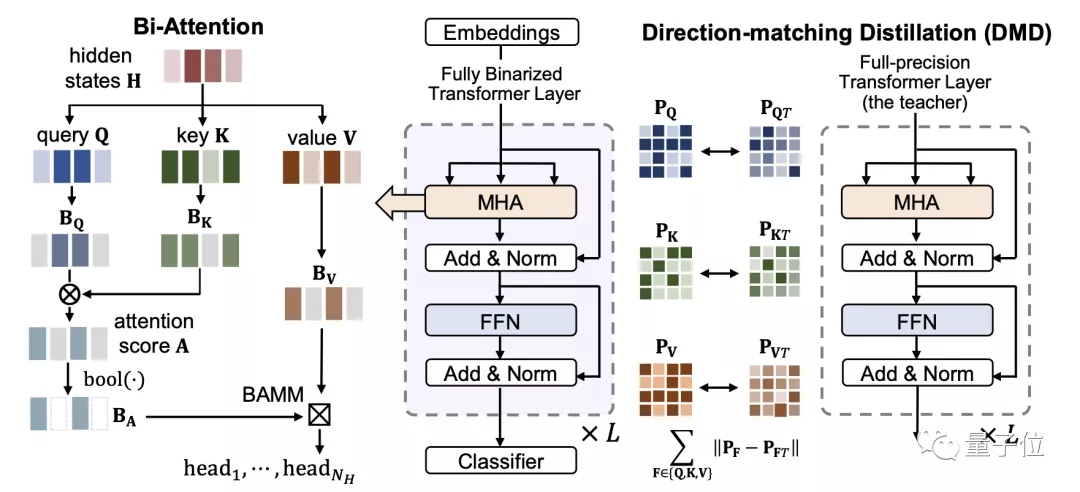
△图 1 BiBERT的整体框架图
BiBERT首次证明了BERT模型全二值化的可行性,在GLUE数据集上的准确性极大地超越了现有的BERT模型二值化算法,甚至超过了更高比特表示的模型。
在模型计算量和体积上,BiBERT理论上能够带来56.3倍和31.2倍的FLOPs和模型尺寸的减少。
方法
Bi-Attention:二值化注意力机制
我们的研究表明,在BERT模型的注意力机制中,softmax函数得到的归一化注意力权重被视为遵循一个概率分布,而直接对其进行二值化会导致完全的信息丧失,其信息熵退化为0(见图2)。
△图 2 直接对softmax函数应用二值化导致完全的信息丧失
一个缓解这种信息退化的常用措施是,在应用sign函数之前对输入张量的分布进行移位,可以表示为:
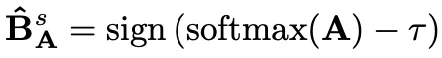
其中,移位参数也被认为是二值化的阈值,希望能使二值化后的熵达到最大。
我们注意到,softmax函数是保序的,这意味着存在一个固定的阈值使二值化表示的信息熵最大化。
受到Hard Attention的启发[4],作者用bool函数来二值化注意力权重A:
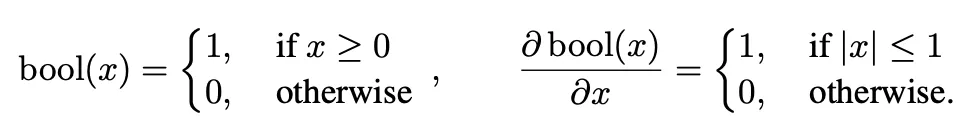
通过应用bool函数,注意权重中值较低的元素被二值化为0,因此得到的熵值最大的注意权重可以过滤出关键部分的元素。
最终二值注意力机制可以被表示为:
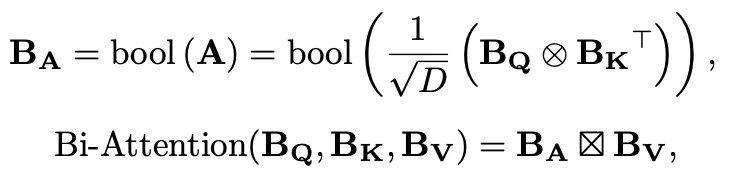
其中,BV是通过sign函数二值化得到的value值,BA是二值化注意力权重,是一个精心设计的Bitwise-Affine矩阵乘法 (BAMM)运算器,由和位移组成,用于对齐训练和推理表征并进行有效的位计算。
DMD: 方向匹配蒸馏
作者发现,由于注意力权重是两个二值化的激活直接相乘而得。
因此,处于决策边缘的值很容易被二值化到相反一侧,从而直接优化注意力权重常常在训练过程中发生优化方向失配问题。(见图3)
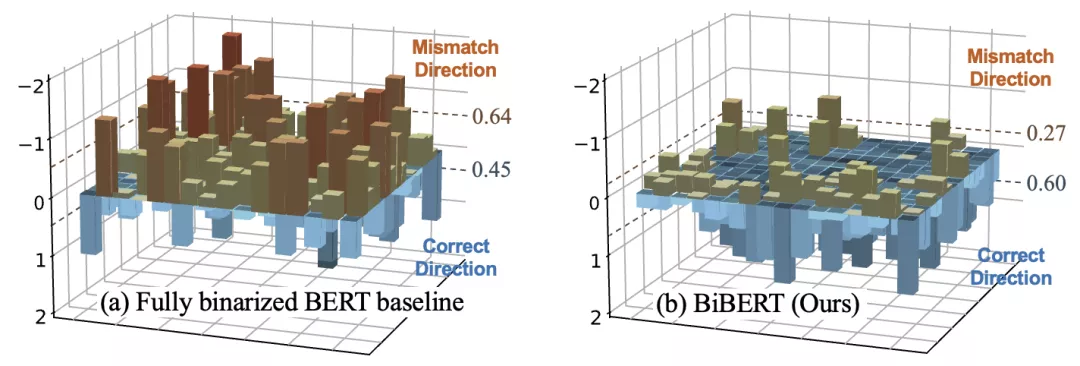
△图 3 优化方向失配
因此,作者设计了新的蒸馏方案,即针对上游的Query、Key和Value矩阵,构建相似性矩阵进行对激活的蒸馏:
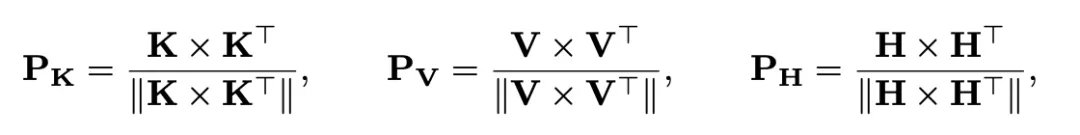
其中,||·||表示L2正则化。之前的研究工作表明,以这种方式构建的矩阵被认为能够反映网络对于特定模式的语义理解,并无视尺度和数值大小影响,能够更加稳定地表示特征之间的内生相关性,更适合二值和全精度网络之间的知识传递。
因此,蒸馏损失可以表示为对隐藏层、预测结果和上述激活相似性矩阵的损失之和:
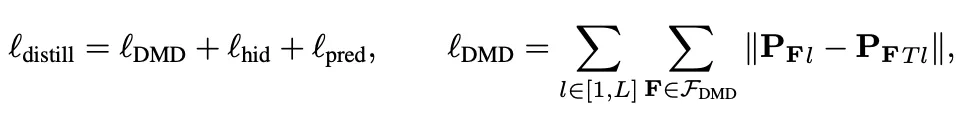
其中L表示transformer的层数,
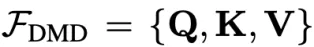
。
实验
作者的实验证明了所提出的BiBERT能够出色地解决二值化BERT模型在GLUE基准数据集的部分任务上精度崩溃的问题,使模型能够稳定优化。
表1表明所提出的Bi-Attention和DMD均可以显著提升模型在二值化后的表现。
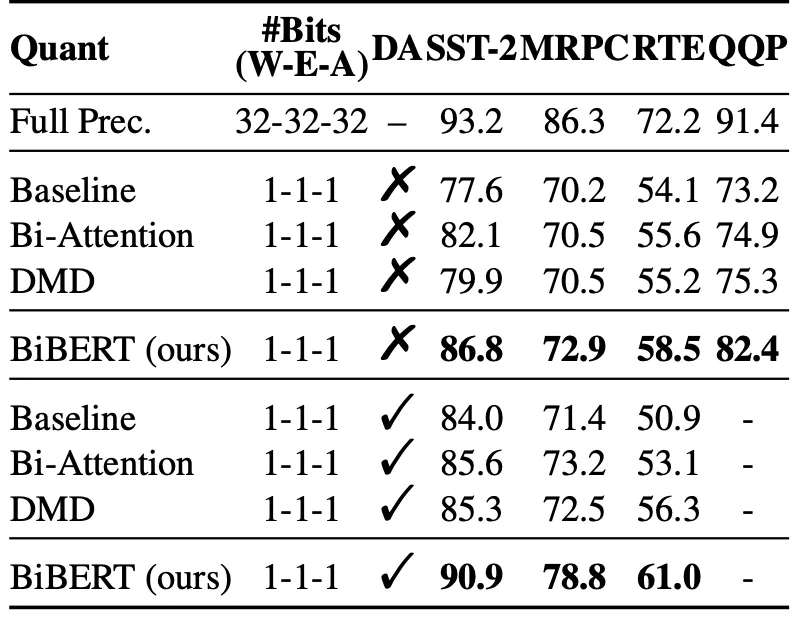
△表 1 消融实验
表2和表3中,作者展示了BiBERT优于其他BERT二值化方法,甚至优于更高比特的量化方案:
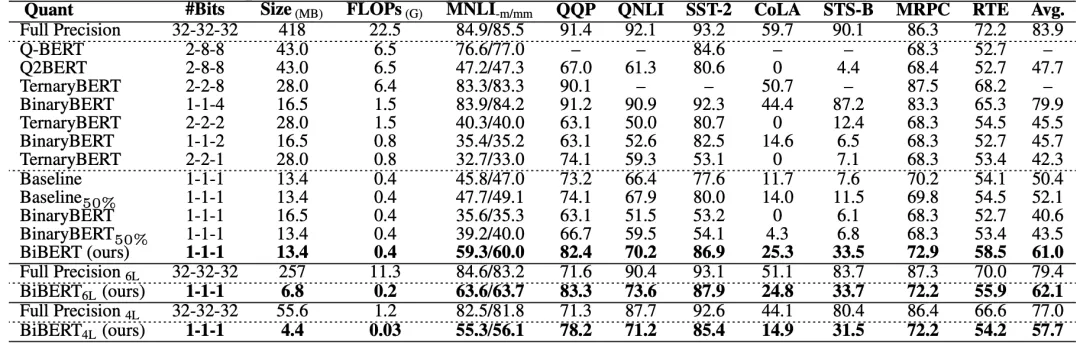
△表 2 基于BERT的二值化方法对比(无数据增强)
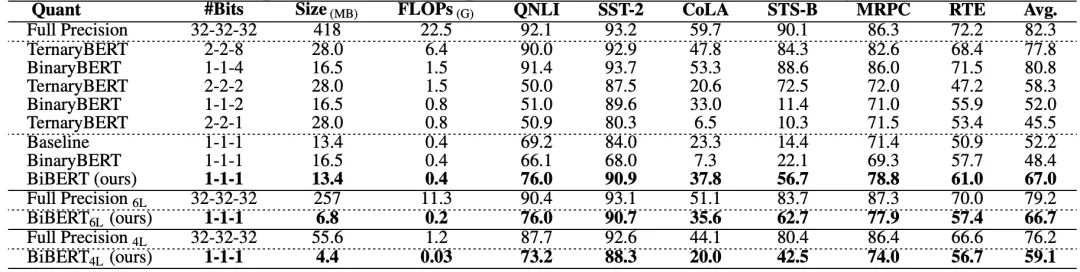
△表 3 基于BERT的二值化方法对比(有数据增强)
其中,50%表示要求二值化后有一半的注意力权重为0,且表中无特殊说明均采用12层的BERT模型进行量化。
此外,作者测量了在训练过程中的信息熵(见图4),作者提出的方法有效地恢复了注意力机制中完全损失的信息熵。
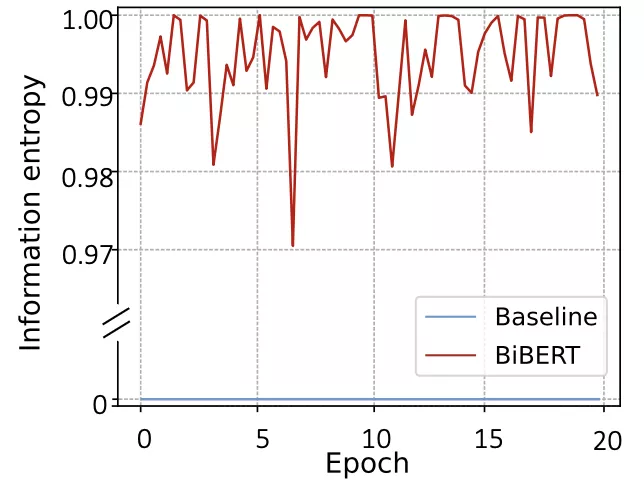
△图 4 训练过程中的信息熵
同时,作者绘制了训练时的loss下降曲线和准确率,BiBERT相比于基线明显更快收敛、准确性更高。
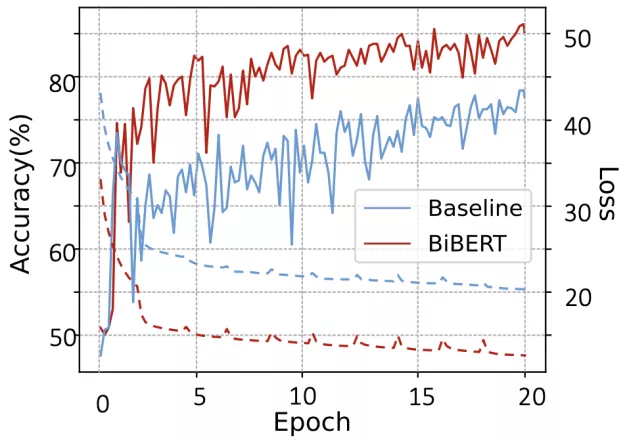
△图 5 训练时的Loss和准确率曲线
总结
作者提出的BiBERT作为第一个BERT模型的全二值化方法,为之后研究BERT二值化建立了理论基础,并分析了其性能下降的原因,针对性地提出了Bi-Attention和DMD方法,有效提高模型的性能表现。
BiBERT超过了现有的BERT模型二值化方法,甚至优于采用更多比特的量化方案,理论上BiBERT能够带来56.3倍的FLOPs减少和31.2倍的模型存储节省。
希望该的工作能够为未来的研究打下坚实的基础。
BiBERT即将基于百度飞桨开源深度学习模型压缩工具PaddleSlim开源,尽情期待。
PaddleSlim:https://github.com/PaddlePaddle/PaddleSlim
传送门
会议论文:https://openreview.net/forum?id=5xEgrl_5FAJ
Reference
[1] Sheng Shen, Zhen Dong, Jiayu Ye, Linjian Ma, Zhewei Yao, Amir Gholami, Michael W. Mahoney, and Kurt Keutzer. Q-BERT: hessian based ultra low precision quantization of BERT. In AAAI, 2020.
[2] Ofir Zafrir, Guy Boudoukh, Peter Izsak, and Moshe Wasserblat. Q8BERT: quantized 8bit BERT. In NeurIPS, 2019.
[3] Ali Hadi Zadeh, Isak Edo, Omar Mohamed Awad, and Andreas Moshovos. GOBO: quantizing attention-based NLP models for low latency and energy efficient inference. In MICRO, 2020.
[4] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. In ICML, 2015.
*本文系量子位获授权刊载,观点仅为作者所有
— 完 —
- 从骁龙8至尊版,我看到了AI手机的未来 | 智在终端2024-12-17
- o1被曝“心机深”:逃避监督还会撒谎,骗人能力一骑绝尘2024-12-09
- 低成本机器人“皮肤”登上Nature子刊:实现三维力的自解耦,来自法国国家科学研究中心&香港大学2024-11-23
- OpenAI重夺竞技场第一,但这波靠的是4o2024-11-21





