谷歌第四代TPU性能实测来了!每秒10万万亿次运算,今年将向谷歌云用户提供服务
256块芯片训练BERT只需不到2分钟
明敏 发自 凹非寺
量子位 报道 | 公众号 QbitAI
一个TPU v4 pod就能达到1 exaflop级的算力,实现每秒10的18次方浮点运算。
缺席一年后的谷歌I/O大会,真的不负众望。

除了让谷歌AI掌门人Jeff Dean都直呼“魔镜”的Starline的3D视频通话技术,第四代TPU也是备受瞩目。
谷歌介绍,TPU v4将主要以pod形式应用,一个pod由4096个TPU v4单芯片组成,可以达到1 exaflop级的算力,这相当于1000万台笔记本电脑之和。
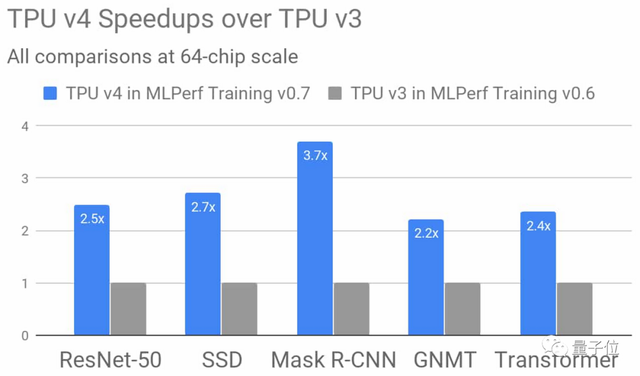
与上一代TPU v3相比,在64个芯片的规模下,TPU v4的性能平均提升了2.7倍。
除此之外,TPU v4 pod的性能较TPU v3 pod提升了10倍。将主要以无碳能源运行,不仅计算更快,而且更加节能。
谷歌CEO桑达尔·皮查伊(Sundar Pichai)透露,TPU v4 pod将会应用在谷歌的数据中心,并在今年内向谷歌云用户提供服务。
两分钟跑完BERT训练
虽然刚刚才正式发布,但早在一年前,谷歌就提前透露了TPU v4的性能。
在去年7月发布的人工智能权威“跑分”MLPerf训练v0.7榜单中,我们可以看到TPU v4与各家芯片的性能对比。
在MLPerf训练测试中,其基准包括图像分类、翻译、推荐系统和围棋等8个机器学习任务中,最终结果是这8项任务的训练时间,速度越快则性能越强。
具体的8项任务内容如下:
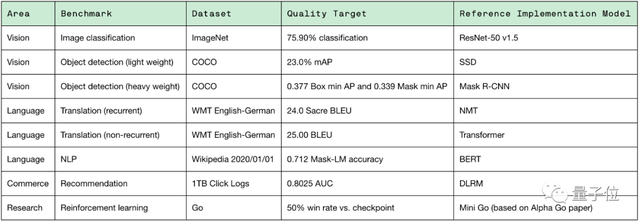
具体训练模型为:ResNet-50、SSD、Mask R-CNN、BERT、NMT、Transformer、DLRM和Mini Go。
TPU v4的表现情况如下,每个系统都以TPU v4加速器的数量来区分,分别为8、64、256.

从对比中可以看到:
在ResNet训练中,256块TPU v4将时长缩短到1.82分钟;
但是Nvidia A100A100-SXM4-40GB想要达到这一水平,至少需要768块加速。
在BERT的训练中,256块TPU v4也将时长缩短到1.82分钟;
同样256块Nvidia A100-SXM4-40GB,仅能把训练时长缩短到3.36分钟。
并且从公布的数据来看,4096块第三代TPU组成的TPU v3 pod就可以将BERT训练压缩到只有23秒!
关于TPU
简单来说,TPU就是谷歌开发的一种可以加速机器学习的芯片。
不同于GPU,TPU是一种ASIC芯片,即应用型专用集成电路(Application-Specific Integrated Circuit),是一种专为某种特定应用需求而定制的芯片。

为什么要研发TPU呢?
其实是因为谷歌自身的许多产品和服务,比如谷歌图像搜索、谷歌翻译,都需要运用深度学习神经网络。
这就对算力有了更高的需求,一般的GPU、CPU很难维持。
所以,TPU应运而生。
第一代TPU被应用到了大名鼎鼎的AlphaGo上,在2015年和李世英对战时,就是部署了48个TPU。
到了第二代TPU,它被引入了Google Cloud,应用在谷歌计算引擎(Google Compute Engine ,简称GCE)中,也称为Cloud TPU。
配置了TPU v2的AlphaGo,仅用了4块TPUv2,便击败当时的世界围棋冠军柯洁。
2018年,谷歌发布第三代TPU,性能提升到第二代的2倍。
每个Pod的性能提高了8倍,且每个pod最多可含1024个芯片。
而第四代TPU,直到2021年才正式和大家见面。
参考链接:
[1]https://spectrum.ieee.org/tech-talk/computing/hardware/heres-how-googles-tpu-v4-ai-chip-stacked-up-in-training-tests
[2]https://mlcommons.org/en/training-normal-07/
[3]https://cloud.google.com/blog/products/ai-machine-learning/google-breaks-ai-performance-records-in-mlperf-with-worlds-fastest-training-supercomputer
- 谷歌Gemini突发试验版模型,重回竞技榜第一!GPT-4o只领先了1天2024-11-22
- 2499,AI浓度爆表!戴上这副眼镜,一句话点咖啡/实时翻译/AR导航全搞定2024-11-19
- 最强开源CodeLLM模型深夜来袭!320亿参数,Qwen2.5-Coder新模型超越GPT-4o2024-11-12
- ¥9.99租英伟达H800!双十一算力羊毛真香,闲置卡也能挂机变现2024-11-04