Qwen版o1发布即开源!32B参数比肩OpenAI o1-mini,一手实测在此
抱抱脸和魔搭社区可在线试玩
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
通义千问版o1来了,还是开源的!
深夜,通义团队突然上线推理模型QwQ,参数量只有32B,在GPQA上击败了o1-mini。

目前,QwQ的模型权重已在HuggingFace和魔搭社区上发布,还可以直接在线试玩。
Ollama、Together.ai等大模型平台也迅速跟进,第一时间宣布支持QwQ运行。
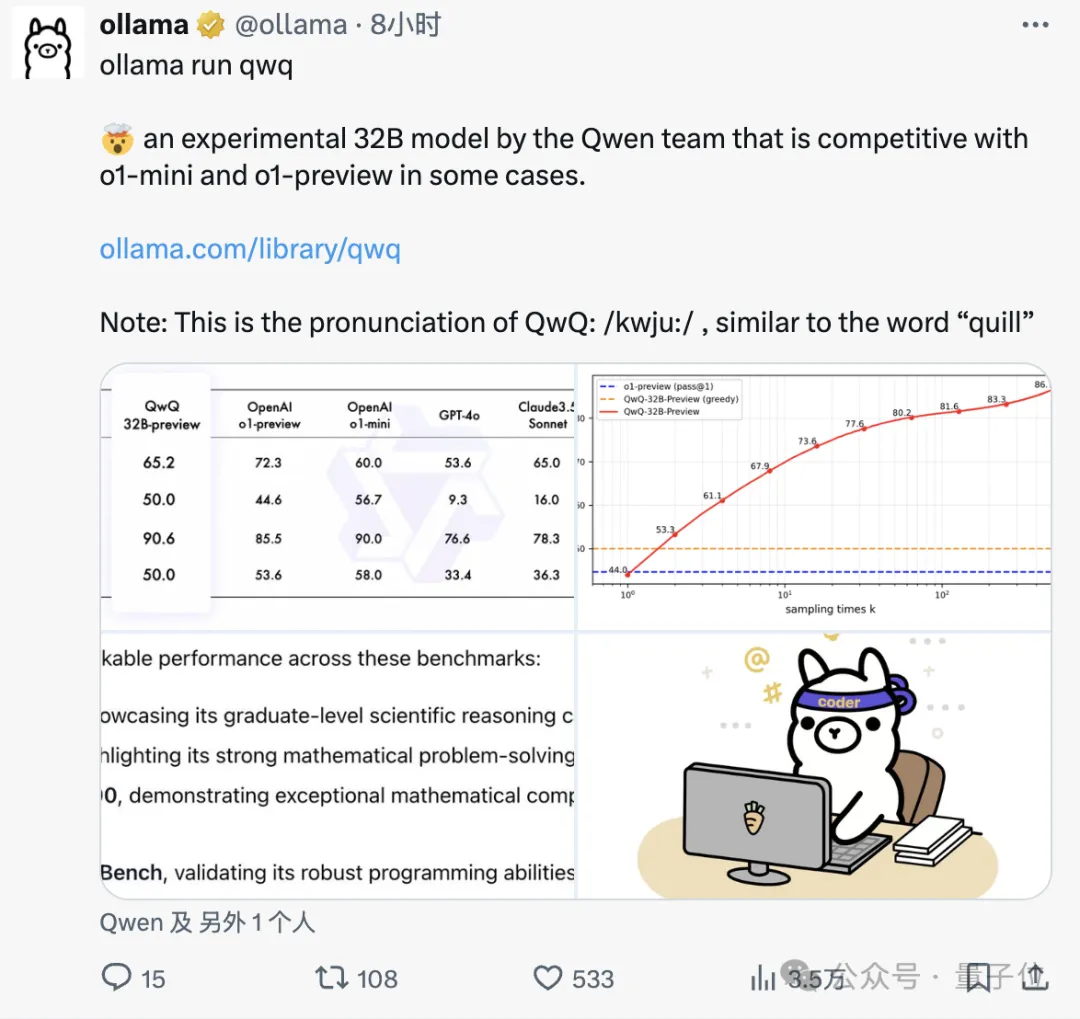
还有网友实测发现,对于自己手中的一道化学计算题,QwQ是除了o1之外唯一能答对的。
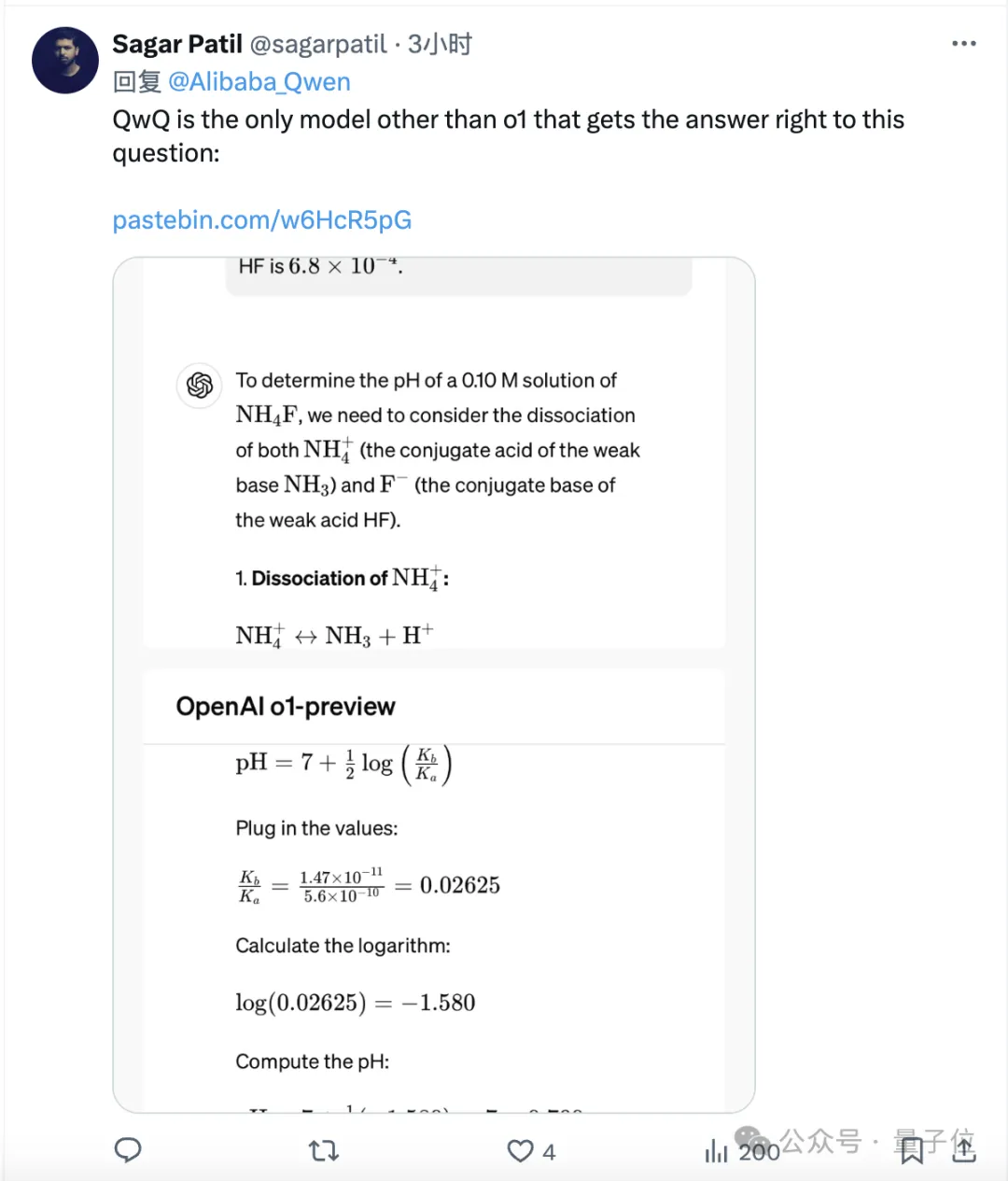
此外有网友指出,QwQ预览版参数量只有32B,这意味着o1水平的推理模型,在本地就能运行了。
推理能力尚可,但简洁度需加强
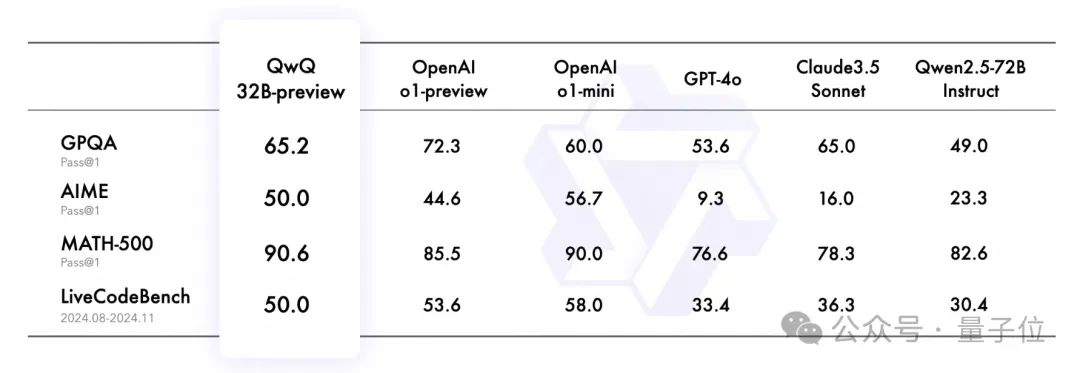
按照官方放出的成绩,QwQ、o1-preview和o1-mini在GPQA(科学推理)、AIME、MATH-500(数学)以及LiveCodeBench(代码)四个数据集中各有胜负,但整体水平比较接近。
而相比GPT-4o、Claude 3.5 Sonnet和自家的Qwen2.5,领先优势就比较明显了。
至于QwQ的实际推理能力到底如何,我们就拿o1-mini对比着测试一下~
首先是官方展示的一道逻辑推理题目:

对于这个问题,QwQ用了足足两千多字进行了分析,这是其中的核心思路:

之后,QwQ开始了近乎列举式的分析方式,一张一张牌地来判断,但好在最终得到的结果是正确的。
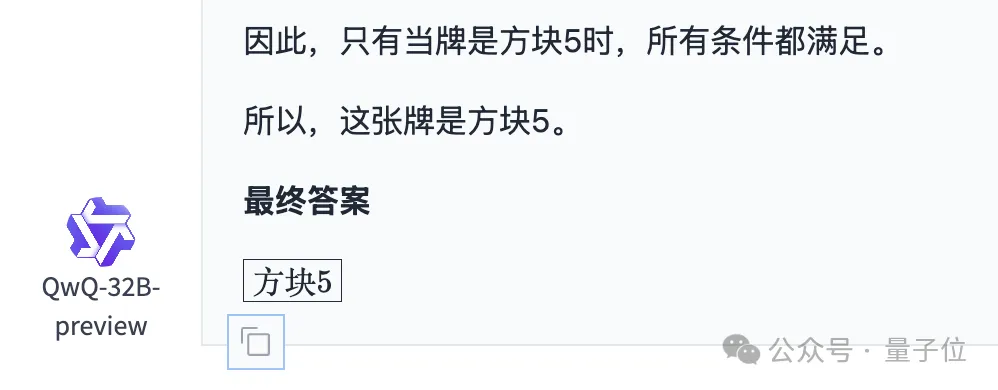
相比之下,o1-mini的回答就显得十分简洁了。

再来一道经典的逻辑题,果不其然QwQ又写起了小作文,而且这次更甚,有4千多字,而且依然是主打一个“试”。

经过对列出情况的逐个尝试和检查,一段时间后得到了最后的正确答案。

再看看o1-mini,用很简单的文字就把问题解释了,推理效率要高得多。

虽然QwQ解释得详细些不是坏事,但中间的错误尝试对于提问者而言就显得有些多余了。
除了基础逻辑,再来看看QwQ的数学水平如何,先来几道考研数学题试试。
第一题关于微分方程,题目是这样的,我们稍作了改动,要求模型以x=_的形式输出:

QwQ依然采用了长篇大论的作答方式,整串回答有将近1400字。
不过仔细看会发现,QwQ的中间过程出现了失败,然后又改用了其他的方式。

折腾了一番之后,结果倒也没有错。

而o1-mini的回答依然保持简洁。
即使把o1-mini默认不显示的“思考过程”展示出来,依然是没有QwQ的回答那么长。

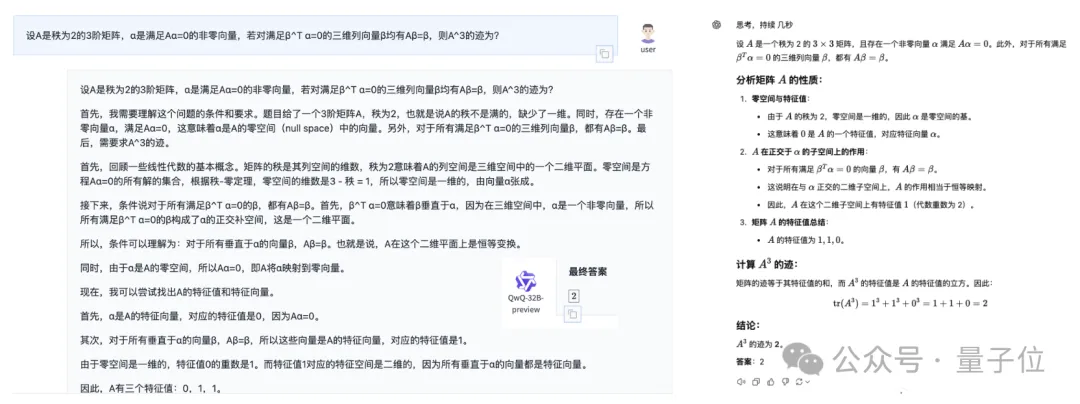
第二道题目是线性代数题,这道题我们也做了修改,从选择题改成了直接求A³的迹:

这次相比之前,QwQ的回答要简洁一些,但还是有上千字,当然结果依然是对的,o1-mini也依然保持简洁。
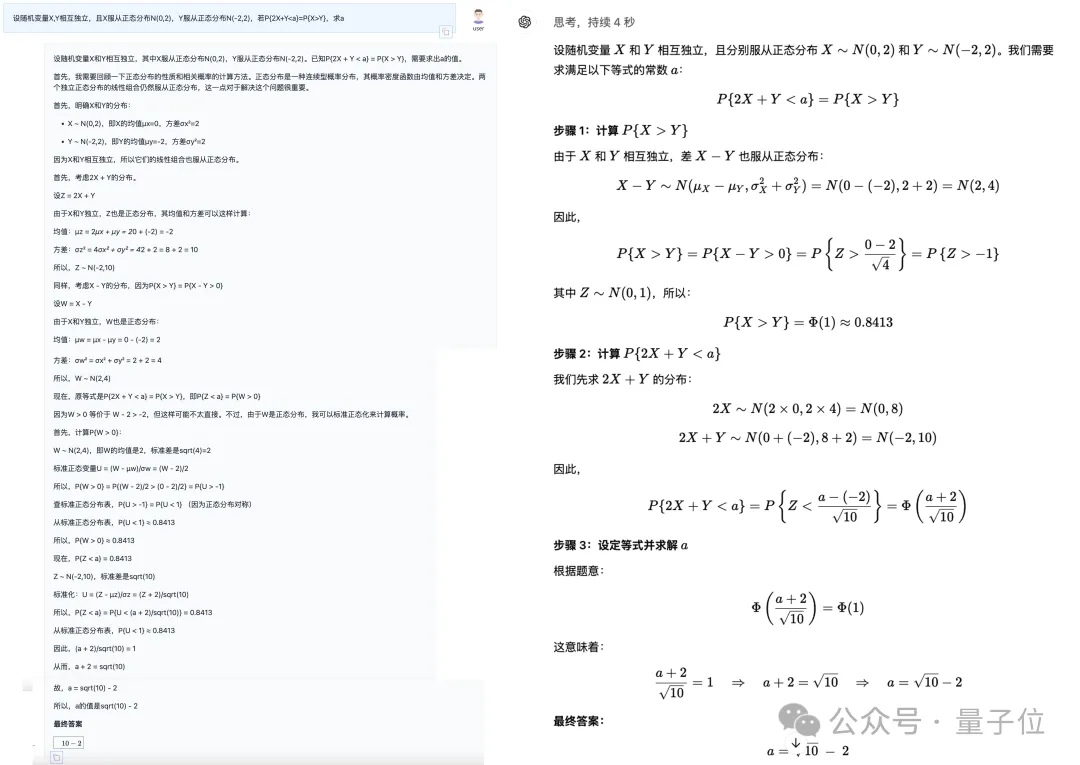
第三道题关于概率论,情况大致和前面两道类似,这里就直接上图:
(QwQ方框中的答案把根号漏了,不过这里是显示问题,从正文看答案是正确的)
除了这样的纯数学题目,情景式的数学问题也是考察模型能力的一项重要标准。
所以这里我们选择了一道数学竞赛AIME的题目:

翻译过来是这样的,测试中我们也是用的这段中文翻译版本:

o1-mini的解法是一种正常思路,最后结果也对了,而QwQ这边上来先是一大通的枚举,然后试图从中寻找规律。
当发现没找到规律时,还会进行更多的枚举,但是最后找出的规律并不正确,结果自然也就错了(不过方向上确实和5的模相关)。
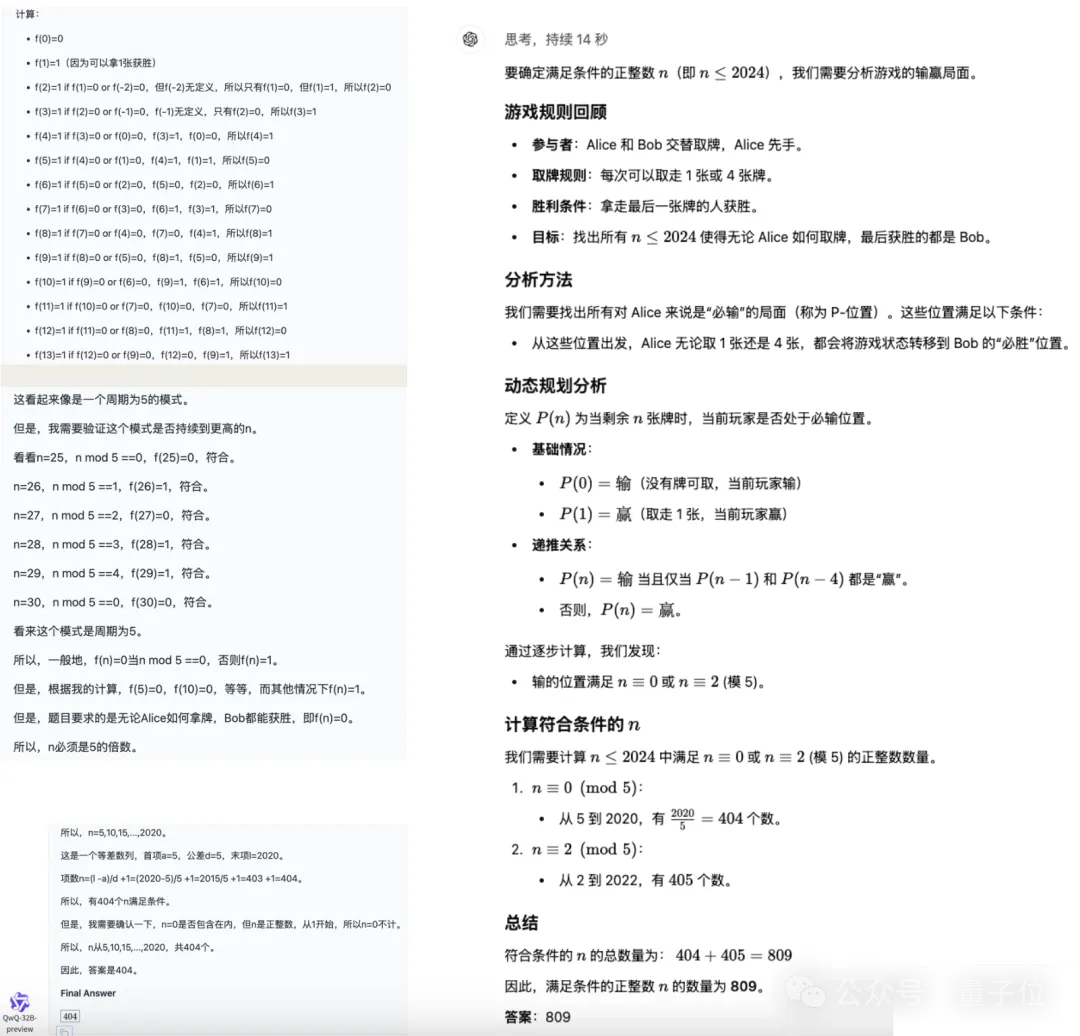
从以上的案例当中可以看到,如果单看正确率,QwQ的表现确实可以和o1-mini同台较量。
但从过程中看,QwQ想一步到位还存在一定难度,还要经历列举、试错等步骤,甚至有时会陷入死循环。
这导致了其结果对于人类的的易读性和o1-mini还存在差距,QwQ需要在这一点上再多改进。
好在QwQ是个开源模型,如果是按token计费的商用模型,这样的输出长度恐怕也会让人望而却步。
当然对于这样的问题,千问团队自身也十分坦然,表示处于测试阶段的QwQ,确实存在冗长而不够聚焦的现象,将会在未来做出改进。
One More Thing
除了这些正经题目,我们也试了试陷阱问题,看下QwQ能不能看出其中的破绽。
问题是这样的,注意是不需要:

遗憾的是,QwQ并没有发现这个关键点,而且当做一道正常的农夫过河问题进行了回答。

不过这也算是大模型的一个通病了,OpenAI的o1在这样的文字游戏面前照样招架不住。

实际上这个问题最早被关注是在几个月之前了,当时还没有o1这样的推理模型,大模型几乎在这个问题上全军覆没。
现在看来,推理能力增强后,也依然没改掉不认真读题的毛病啊(手动狗头)。
参考链接:
https://qwenlm.github.io/blog/qwq-32b-preview/
体验地址(Hugging Face):
https://huggingface.co/spaces/Qwen/QwQ-32B-preview
体验地址(魔搭社区):
https://modelscope.cn/studios/Qwen/QwQ-32B-preview
- Claude网页版接入MCP!10款应用一键调用,开发者30分钟可创建新集成2025-05-02
- 1450亿!马斯克xAI与X合并后再寻资金,将成史上第二大初创企业单轮融资2025-04-27
- 挤爆字节服务器的Agent到底啥水平?一手实测来了2025-04-23
- 电视装了智能体,只凭台词就能找到剧集了2025-04-24