o1/Claude集体翻车!陶哲轩等60+顶尖数学家合力提出新数学基准
陶哲轩看了也说难
让大模型集体吃瘪,数学题正确率通通不到2%!
获大神卡帕西力荐,大模型新数学基准来势汹汹——
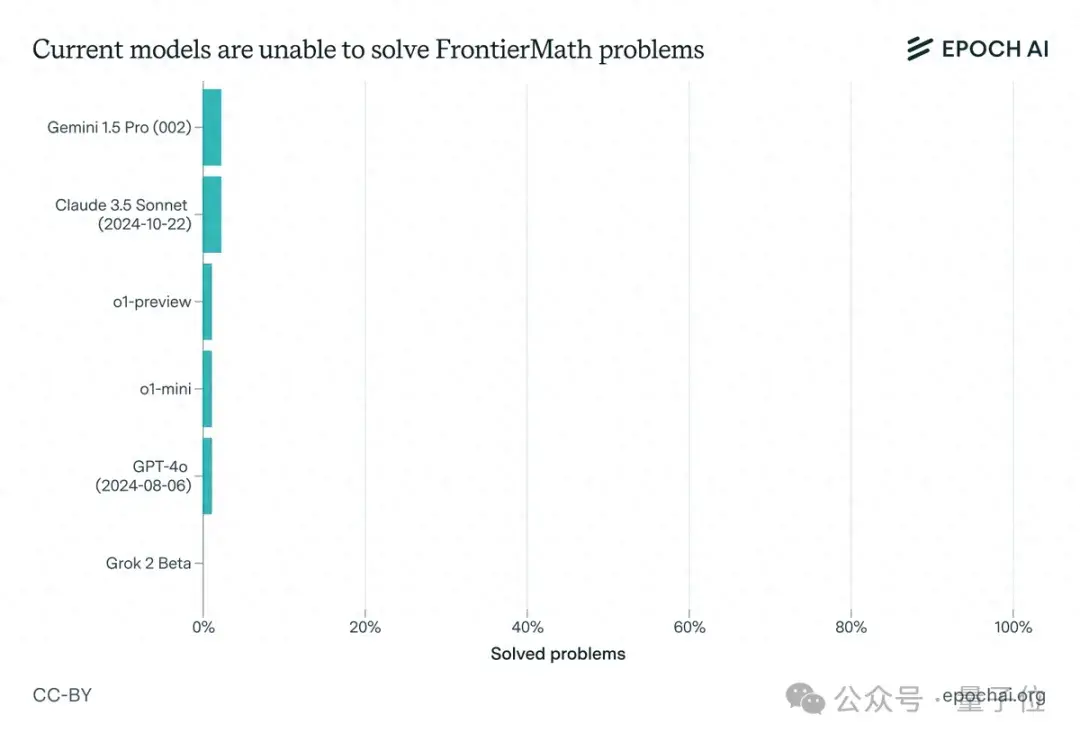
一出手,曾在国际数学奥赛中拿下83%解题率的o1模型就败下阵来,并且Claude 3.5 Sonnet、GPT-4o、Gemini 1.5 Pro等全都未攻破2%这一防线。
所以,新挑战者到底啥来头??
一打听,这个新数学基准名为FrontierMath,由Epoch AI这家非营利研究机构号召陶哲轩在内的60多位顶尖数学家提出。

这群人这次铁了心要给AI上难度,直接原创了数百道极具挑战性的数学问题——
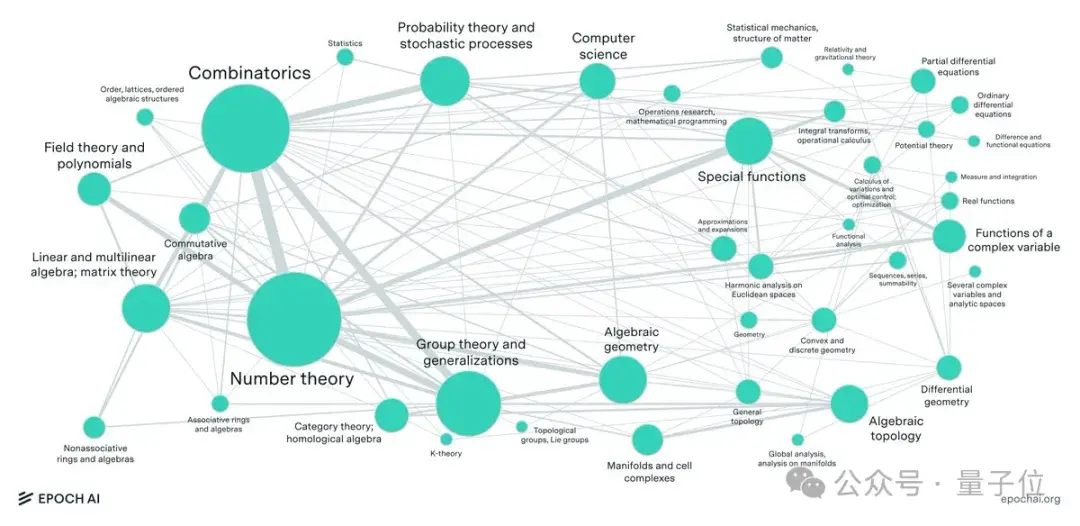
从数论中计算密集型问题到代数几何和范畴论中的抽象问题,涵盖了现代数学的大多数主要分支。
这些题有多难呢?按数学大佬陶哲轩对这项研究的评价说:
大模型们,至少需要再战个几年吧。

同时,卡帕西也表示非常喜欢这一新基准,甚至乐于见到大模型们“吃瘪”:
之所以引入这个基准,是因为大模型越来越多地碾压现有的数学基准
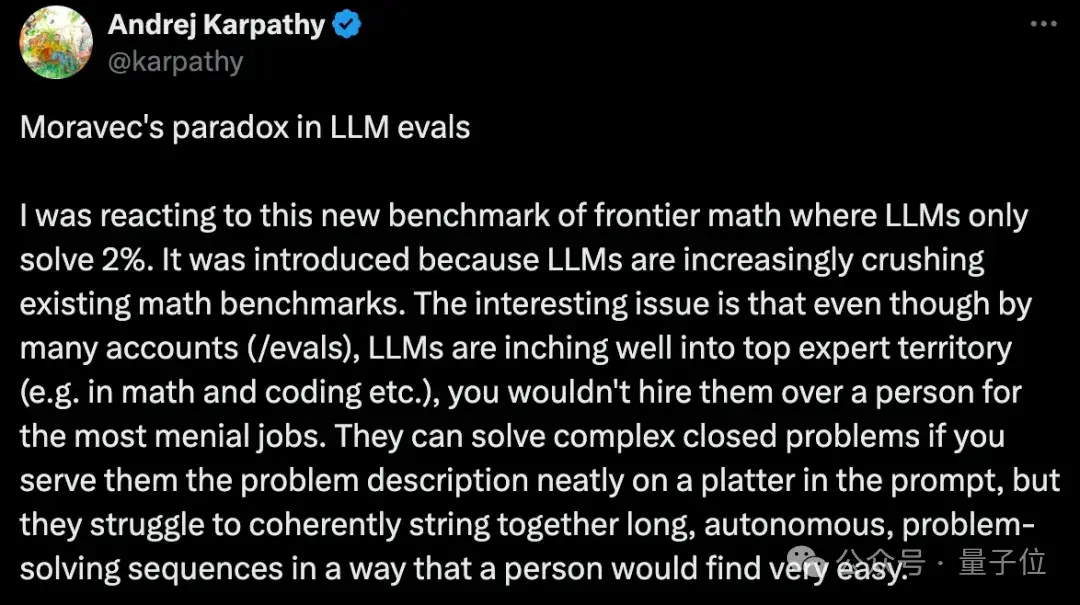
FrontierMath:评估AI高级数学推理能力的新基准
今年以来,大语言模型(LLM)开始在各种数学benchmark上疯狂刷分,而且正确率动辄90%以上。
宣传看多了,人也麻了,于是纷纷反思——
一定是现在的基准测试“被污染了”(比如让AI在训练阶段提前学习基准测试中的问题)。
对此,非营利研究机构Epoch AI看不下去了,于是直接联合60多位顶尖数学家(共获得了14枚IMO金牌)推出FrontierMath。
这一新基准拥有数百道大模型们之前没见过的数学题,而且难度颇高。
通常需要专业数学家花费数小时甚至数天的努力
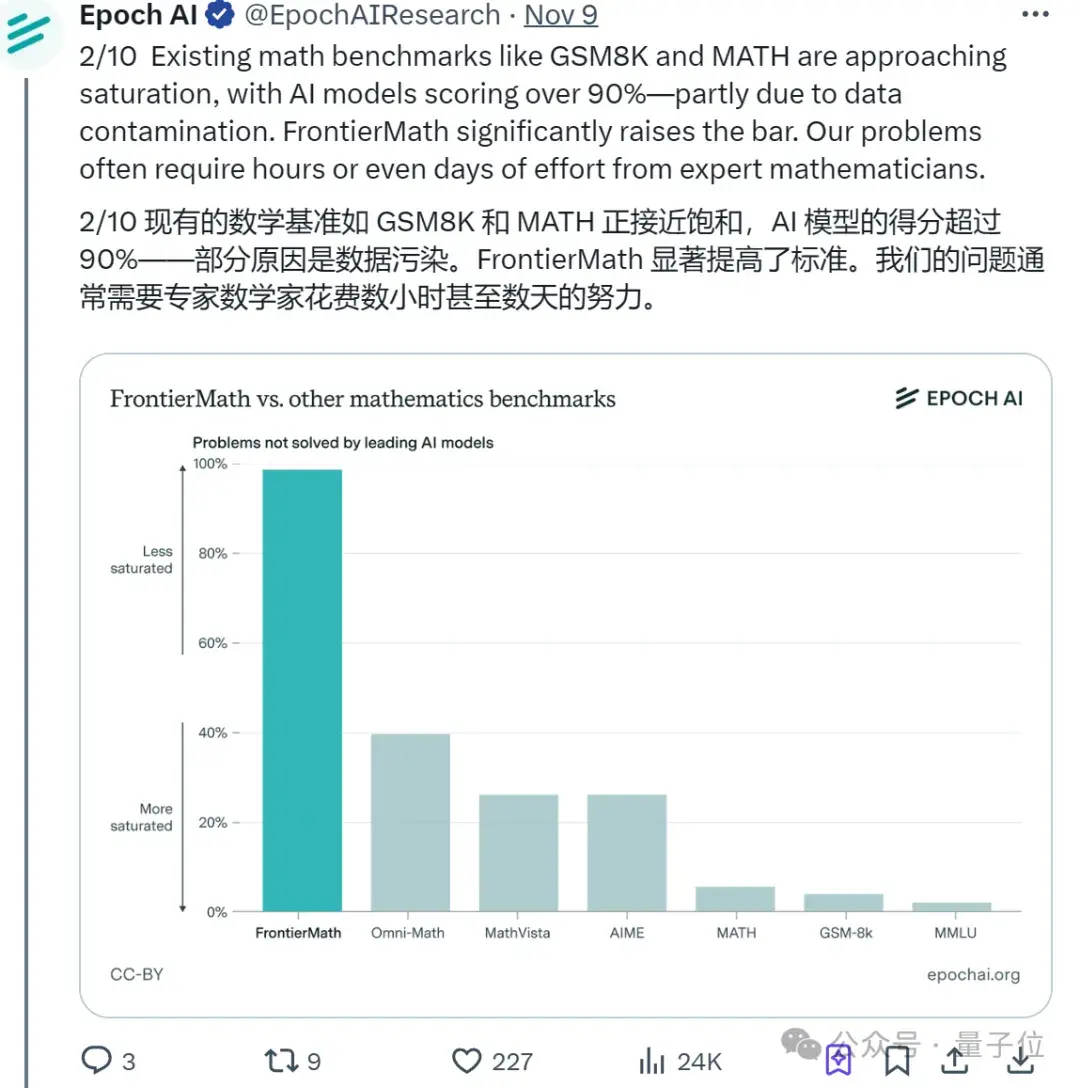
一番实践检验下,果不其然,一众顶尖大模型纷纷折戟(包括Claude 3.5 Sonnet、GPT-4o和Gemini 1.5 Pro等),解题率均不足2%。
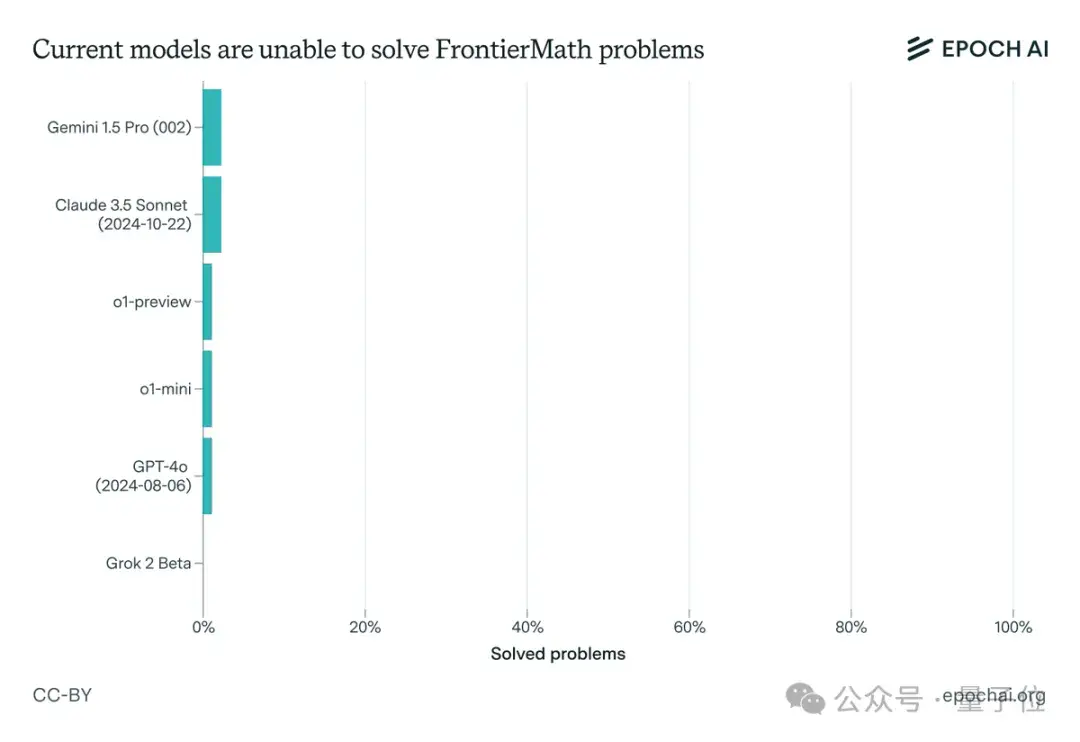
而且即使有延长的思考时间(10,000个token)、Python访问权限以及运行实验的能力,相关成功率仍然低于2%。

下面,我们具体介绍下FrontierMath。这第一关主要解决数学题的原创性。
这群数学家们被要求按照3个关键原则设计题目:
- 所有问题都是新的且未发表的,以防止数据污染;
- 解决方案是自动可验证的,从而实现高效的评估;
- 问题是“防猜测”的,在没有正确推理的情况下解决的可能性很低;

除了出新题,为了防止数据污染,机构还采取了其他措施。
比如为了最大限度地降低问题和解决方案在网上传播的风险,机构鼓励所有提交都通过安全、加密的渠道进行。
具体来说,机构采用加密通信平台与投稿人协调,并要求对在线存储的任何书面材料进行加密(如加密文档)。
同时,机构依赖于核心数学家团队专家评审这一原创验证性方法,以识别自动化系统可能错过的潜在相似性(专家比机器更熟悉这些研究细节)。
当然也不完全依靠人力,为了进一步保证原创性,机构还通过抄袭检测工具Quetext和Copyscape对问题进行测试。
最终,数学家们提出了数百道原创题目,涵盖了现代数学的大多数主要分支,从数论中计算密集型问题到代数几何和范畴论中的抽象问题。
其中数论和组合学最多,合计约占所有MSC2020(数学学科分类系统2020版本)的34%。

接下来,为了评估大模型在FrontierMath问题上的表现,研究开发了一个框架。
简单说,这一框架具体执行任务的过程如下:
- 分析问题:模型首先分析给定的数学问题;
- 提出策略:模型提出可能的解决方案策略;
- 实施并执行代码:将这些策略转化为可执行的Python代码并自动执行;
- 接收反馈:从代码执行的结果中接收反馈,包括输出和错误消息;
- 改进方法:根据实验结果,模型会验证中间结果,测试猜想,并可能改进其推理过程以修正潜在的错误;
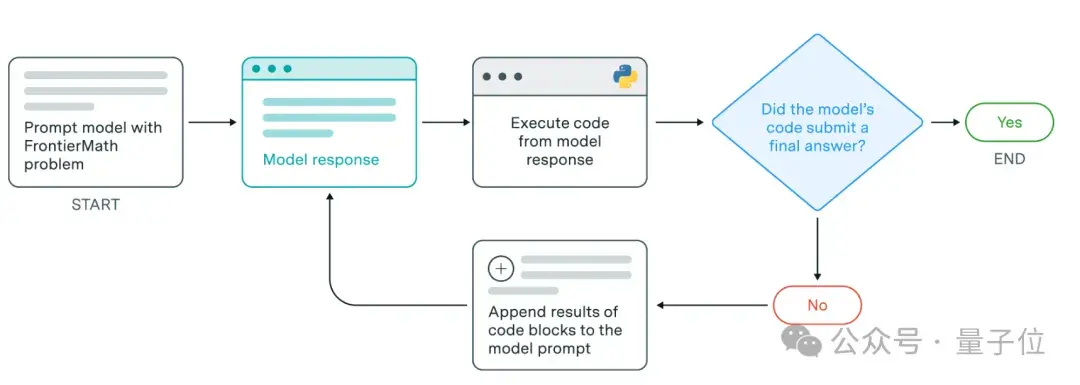
该框架支持两种提交方式:一种是模型可以直接给出问题的最终答案;另一种是,在提交最终答案之前,模型可以先通过代码执行进行实验,以验证其解决方案的有效性。
不过需要提醒,在提交最终答案时,模型必须遵循一些标准化格式。
比如,在答案中需包含#This is the final answer这一标记注释,且将结果保存在Python的pickle模块中,同时需确保提交的代码必须是自包含的,不依赖于先前的计算。
总之,这一评估过程将持续进行,直到模型提交了正确格式化的最终答案,或者达到了预设的标记限制(研究设置为10,000个token)。
如果模型在达到标记限制之前没有提交最终答案,它将收到一个最终提示,要求立即提交最终答案;
如果在收到该提示后模型仍然无法提供正确格式化的最终答案,则该尝试被标记为不正确。
陶哲轩看了都说难
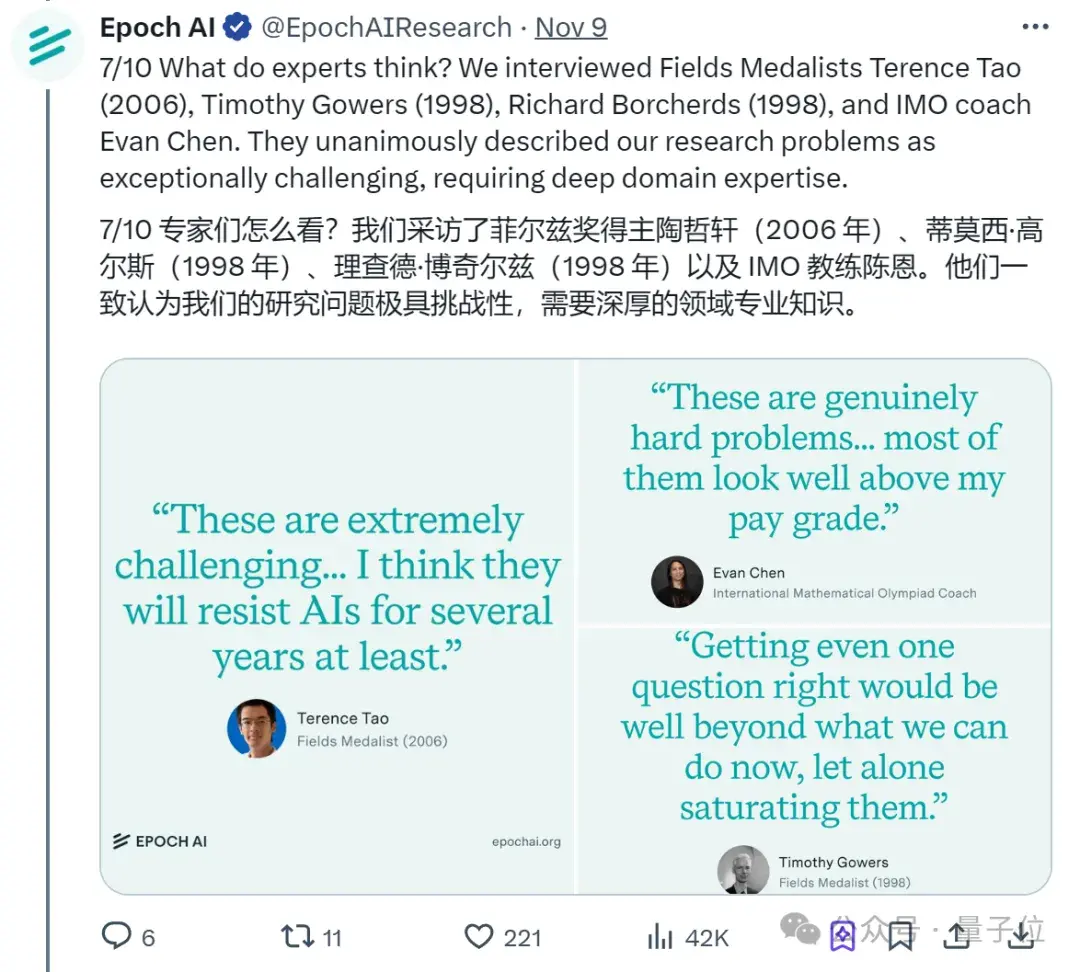
为了进一步验证FrontierMath的难度,该机构还特意采访了4位数学大佬。
包括菲尔兹奖得主陶哲轩 (2006)、蒂莫西·高尔斯 (1998)、理查德·博赫兹 (1998),以及国际数学奥林匹克竞赛 (IMO) 教练陈谊廷 (Evan Chen)在内,他们一致认为这些题非常具有挑战性。
下一步Epoch AI也计划从四个方面持续推进:
- 定期评估这些领先的大模型,并观察高级数学推理能力随时间推移和规模扩大而提高的情况;
- 保持难度的同时,向FrontierMath添加更多问题;
- 在未来几个月内发布更多代表性问题,供大家研究讨论;
- 扩大专家审查、增加错误数量和改进同行评审流程来加强质量控制;
这也合了卡帕西的心意,他认为这样的新基准应该更多,尤其是为那些看似“容易”的事情创建评估。
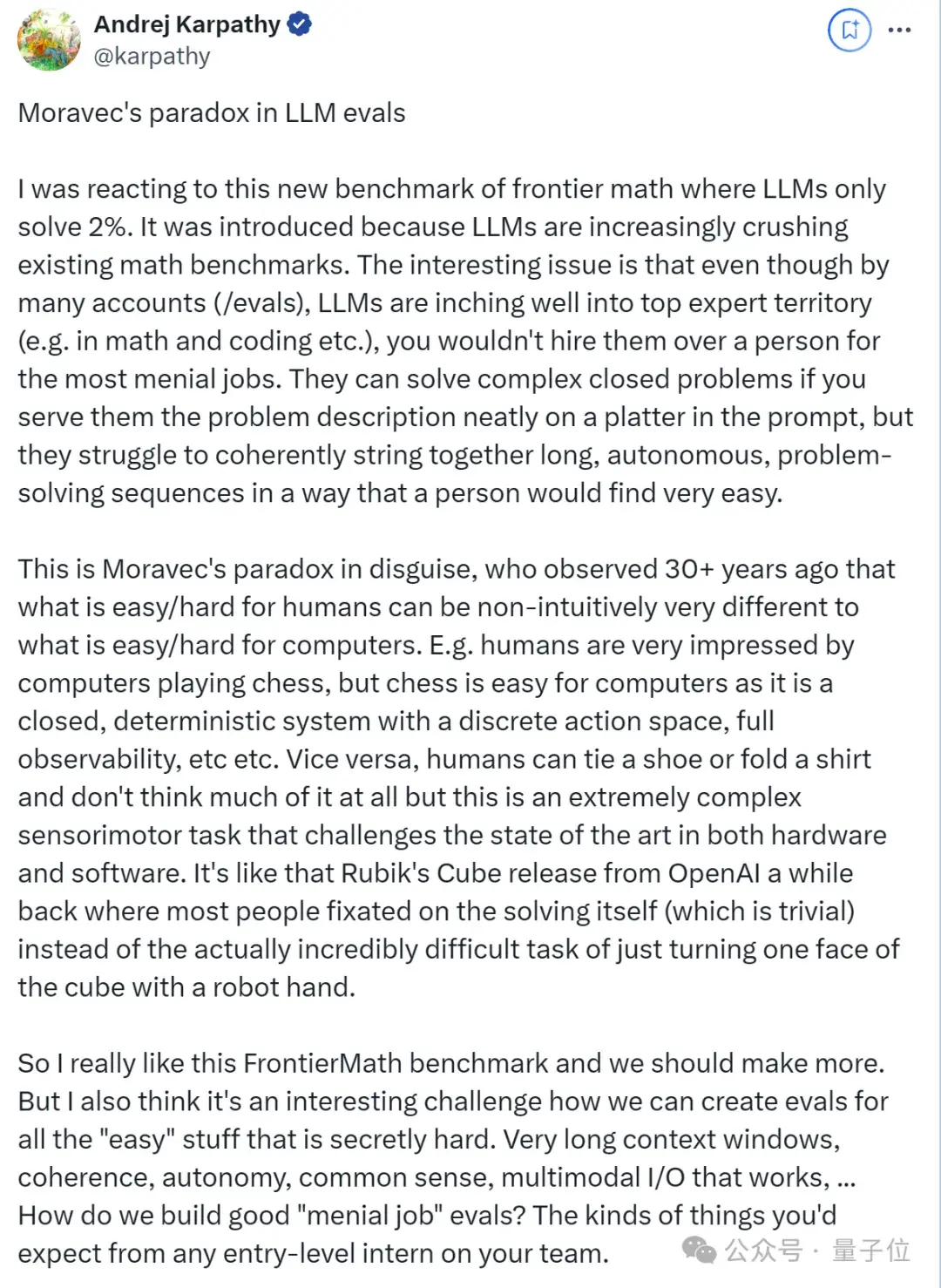
之所以引入这个基准,是因为大模型越来越多地碾压现有的数学基准。有趣的问题是,尽管从许多方面(/evals)来看,大模型正逐步跻身顶级专家行列(如数学和编码等),但你不会雇用他们而不是让他们从事最琐碎的工作。
如果你把问题描述整齐地放在盘子里,他们就能解决复杂的封闭式问题,但他们很难连贯地把长长的、自主的、解决问题的序列串联起来,而人却会觉得非常容易。
这是莫拉维克悖论的变相,他在30多年前就观察到,对人类来说容易/困难的事情,与对计算机来说容易/困难的事情,在非直觉上可能大相径庭。
例如,人类对计算机下国际象棋印象深刻,但国际象棋对计算机来说却很容易,因为它是一个封闭的、确定性的系统,具有离散的行动空间、完全的可观测性等等。
反之亦然,人类可以系好鞋带或叠好衬衫,而且根本不需要考虑太多,但这是一项极其复杂的传感运动任务,对硬件和软件的技术水平都是挑战。
这就像不久前OpenAI发布的魔方一样,大多数人都把注意力集中在解魔方本身(这是微不足道的),而不是用机器人的手转动魔方的一个面这一实际难度极高的任务。
因此,我非常喜欢这个FrontierMath基准,我们应该制作更多的基准。但我也认为,如何为所有 “容易 “但其实很难的东西创建评估是一个有趣的挑战。
很长的语境窗口、连贯性、自主性、常识、有效的多模态输入/输出…… 我们如何建立良好的 “初级工作 “评估?就像你对团队中任何初级实习生的期望。
网友也表示,能在这种基准测试中取得高分的大模型将大有裨益。
陶哲轩梦想的就是这样的东西,可以连接到LEAN(微软研究院推出的一款定理证明器),让数学家成为编辑、顾问,偶尔处理一些真正困难的部分,而其余部分则自动化且可证明正确。
很难说一个在这次基准测试中能够达到80%的LLM对数学家来说没有用处。

对此,你怎么看?
- 数学家们仍在追赶天才拉马努金2025-04-27
- Qwen3真香!通义App满血接入,一手实测在此2025-04-30
- 不到2年,AI PPT赛道第一!像素绽放CEO赵充:今年是AI应用创业最佳时期 | 中国AIGC产业峰会2025-04-27
- 一手实测!文心X1/4.5 Turbo推理和多模态双双变强,还把模型成本降了6成?!2025-04-25