
车圈最大AI「黑马」吉利:自研语音大模型登顶,性能超SOTA 10%
车端8亿参数,复刻仅需3秒样本
贾浩楠 发自 凹非寺
量子位 | 公众号 QbitAI
语音合成大模型赛道,王者一夜易主。
最新HAM-TTS大模型,在发音准确性、自然度和说话人相似度上对比之前SOTA成果VALL-E,有了大幅提升。

背后的主要科研团队却是LLM赛道今年最令人意外的一匹“黑马”:
吉利汽车。
没错,不是AI原生公司,不是传统的科技巨头,是以汽车知名但正在不断展现硬科技实力的吉利。
吉利星睿AI大模型,有什么用?
吉利自研语音大模型HAM-TTS的全称是:
Hierarchical Acoustic Modeling for Token-Based Zero-Shot Text-to-Speech,直译是基于token的零样本文字转语音分层声学建模,是星睿AI大模型体系下的重要一员。
顾名思义,对于智能座舱体验来说,这项技术作用在最关键的交互环节:“发音”。
语音助手说的好不好,通常有这么几个评价指标:
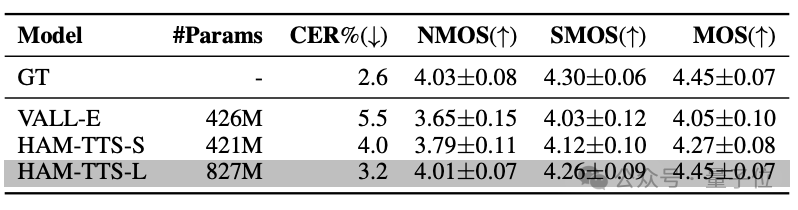
发音准确度,通过Character Error Rate(CER)来评判,具体由知名端到端语音模型平台ESPNet来打分。
说话风格的一致性NMOS、音调一致性SMOS,以及整体分数MOS,是由研究团队招募的60人团队进行主观判断评分。
总体来看,同样在4亿参数左右的规模下,HAM-TTS模型相比SOTA的VALL-E模型,字符错误率下降1.5%左右。
完全体8亿参数的HAM-TTS模型,相比VALL-E,字符错误率直接下降2.3%。
在风格一致性、音调一致性以及整体得分上,HAM-TTS模型有10%左右的提升。

在智能座舱的交互场景中,比如联动虚拟形象、自定义人设、语音导航、新闻播报、绘本朗读、说书、直播等等,背后都离不开星睿语音大模型提供强大的技术支持能力。
星睿语音大模型有了更好的辨识能力,知道该如何更好地维持说话人声音的音色稳定性和连贯性,不会出现音色突变。
无论是新闻播报的专业场景讲段子的轻松氛围,还是读绘本的温馨时刻,还能够根据特定场景需求,智能调节语气、语调、停顿和情感等多维度参数。用户都能拥有更沉浸、自然、生动的个性化语音交互体验。
其次是跨语种无缝切换,不管用户提供哪个语种哪种方言,都能在保持音色一致的条件下,流畅使用中文或英文进行语音合成。
你说方言输入,系统能直接转换成普通话输出,甚至是其他不同的方言输出。
现在已经支持四川话、粤语、东北话等多种方言合成,甚至还支持日韩及东南亚跨语种语音合成。
而且最重要的是,星睿语音模型在声音复刻能力上,最短仅需要3秒钟的样本输入,相比行业普遍的10s样本需求有了重大提升。
这其实是在用户体验层面,星睿语音大模型最大的学术价值——通过创新声音合成技术和数据增强策略,改善了TTS模型的性能和训练成本。
吉利怎么做到的?
TTS模型一直广泛应用在文字转语音的各种交互应用中,常规模式是“文本处理——提取声学特征——语音合成”三个步骤。
前两步都有标准可循的规则算法,一般都在最后语音合成这一步应用神经网络,通常模型也不大。比如语音合成模型的开山之作VALL-E,从16块V100 GPU的训练配置上看,规模并不算大,4亿参数左右。

但输入文本直接和语音token进行拼接作为大模型的输入,缺乏足够的语义信息来约束模型,或者说文本和语音没有做好“对齐”。这也就造成传统TTS模型存在发音准确率低、说话风格和音色不一致的问题。
这个问题可以通过大量多样化训练数据来解决,但这样一来研发周期和成本就会升高。
吉利的解决方法是在传统TTS模型结构中,引入分层声学建模方法:
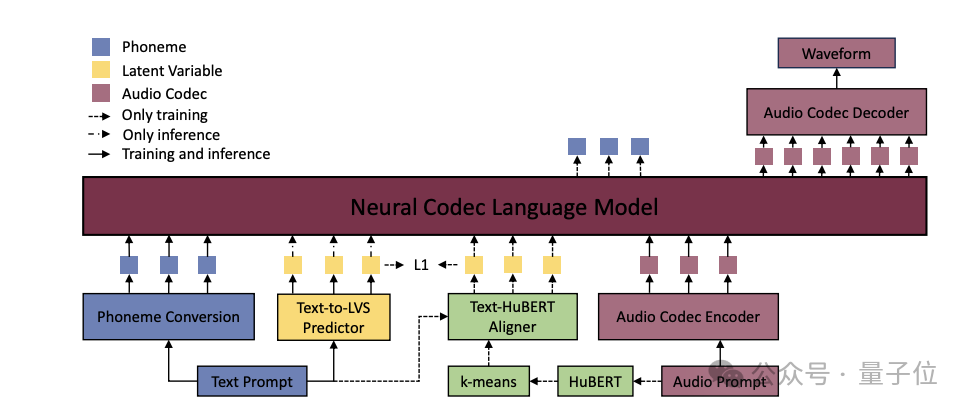
具体来说引入了一个Text-to-LVS predictor(文本到隐空间变量序列预测器),即由文本预测出蕴含重要的声学信息和语义信息的隐变量,作为补充信息。在推理阶段,这些隐变量信息与文本prompt信息一起,作为大模型的输入。
这样一来能够显著改善了合成语音中的发音错误和风格突变的问题。并且在训练过程中,还会替换和复制数据段,以提高音色的均匀性。
在训练阶段,模型中还引入一个对齐器*(Text-HuBERT Aligner)来生成监督LVS,用于辅助Text-to-LVS predictor的训练。它把文本(音素)序列与语音的HuBERT特征对齐,生成与音素序列长度相同的监督LVS序列。
在提取音频特征后,还引入了K-means聚类处理,目的是为了去除原始音频特征中的说话人个性化信息,使得模型更加关注于语音的共性特征,从而提高模型的泛化能力,以及合成语音的音色一致性。
提高语音合成准确性的同时,团队还采用了基于UNet架构的声音转换预训练模型,生成大量具有不同音色但内容相同的合成语音数据,以此来增加训练数据的多样性和数量,从而提高TTS模型的性能和泛化能力。
首先,从语音数据中提取HuBERT特征和基频(F0),然后将这些特征输入到一个ResNet模型中进行处理。随后,数据经过编码下采样和解码上采用过程,最终还原成音频信号。在解码器上采样阶段的每一步,引入目标说话人embedding特征,实现改变说话音色但不改变说话内容的效果。
一举三得,首先是解决真实数据不足的问题,其次是规避了版权、隐私风险,以及有效解决数据稀疏(如罕见的发音、特定的口音或语调)的问题。
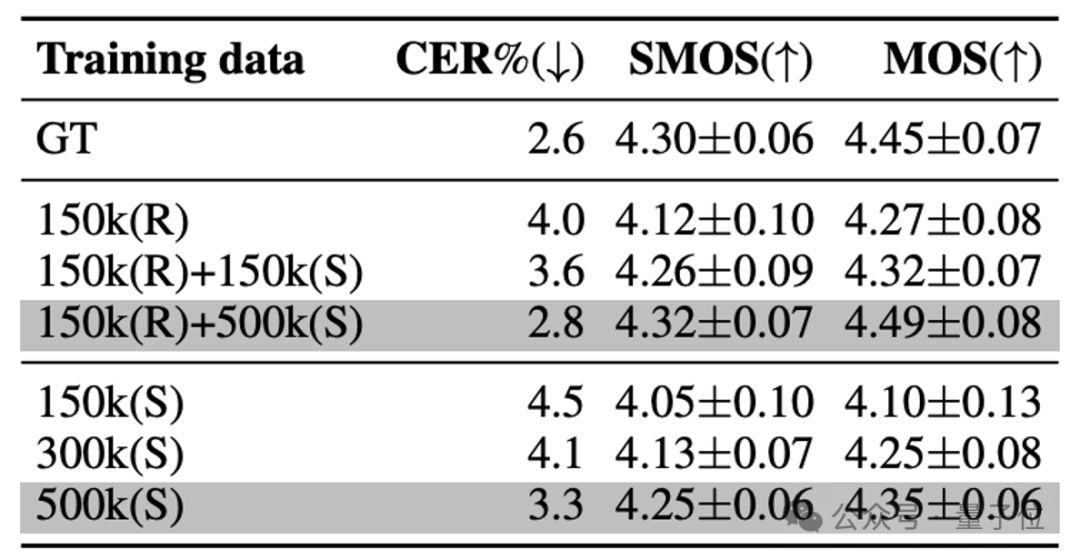
使用不同组合和规模的真实(Real)和合成(Synthetic)数据训练HAM-TTS型,结果显示,真实和合成数据综合进行训练,模型性能效果提升最明显。
吉利的语音大模型SOTA了,怎么解读?
之前不被各个厂家重视的智能座舱corner case,吉利正在用算法能力提出解决方案,完成的是智能汽车“最后一公里”的体验提升。
这部分研发最耗时费力,对技术能力的要求也最高:
不但要明白最先进的模型好在哪,还要搞清楚它哪里不足,并且针对性提出改进。
AI大模型这本书,大部分汽车厂家只翻开了“前言”就已经大呼头疼,但吉利不但吃透,还做起了“批注”。

而且是实打实的论文一作,团队绝大部分成员也都是吉利的科学家——星睿语音大模型的“归属权”没有争议。
“自研”反复被重新定义的车圈,吉利是一股清流。
按照这个思路追踪,发现这样的例子还有更多。
比如吉利星睿AI大模型体系,包括语言大模型、多模态大模型、数字孪生大模型3大基础模型,并由此衍生出NLP语言大模型、NPDS研发大模型、多模态感知大模型、多模态生成大模型、AI DRIVE大模型、数字生命大模型等等,构建起了整个智能汽车的AI技术底座。
再比如算力方面,睿智算中心的云端总算力已由去年的81亿亿次/秒,扩容到102亿亿次/秒。
星睿语音大模型背后体现出来的,是吉利“技术爆炸”:算法能力、大模型的体系化能力、数据能力领先行业,也给行业提供了新方案选择。
这是在电动化旗开得胜之后,吉利在智能化领域的一鸣惊人。
但对于吉利而言,整体开拓还不止于此,这几年不光是汽车业务相关的核心技术投入,在更广泛的底层科技层面,吉利也不断展现着龙头角色,在卫星、芯片、操作系统等最核心科技突破上,吉利之力,都越来越藏不住了。
是时候重新认知吉利了。
论文地址:https://arxiv.org/abs/2403.05989
- 理想:自研热管理技术第一梯队,冬季纯电续航提升15%2024-12-18
- 大疆自动驾驶,获中国销量TOP 2车企同时入股2024-12-17
- 比亚迪三十年庆,王传福:1000亿投入智能化2024-11-29
- 华为智驾首次上车比亚迪!38万元硬派越野车标配端到端2024-11-12



