推理效率提升超200%,易用性对齐vLLM,这款国产加速框架啥来头?
运营成本最高降低 64%
2022 年 10 月,ChatGPT 的问世引爆了以大语言模型为代表的的 AI 浪潮,全球科技企业纷纷加入大语言模型的军备竞赛,大语言模型的数量、参数规模及计算需求呈指数级提升。
大语言模型(Large Language Model,简称 LLM 大模型)指使用大量文本数据训练的深度学习模型,可以生成自然语言文本或理解语言文本的含义。大模型通常包含百亿至万亿个参数,训练时需要处理数万亿个 Token,这对显卡等算力提出了极高的要求,也带来了能源消耗的激增。
据斯坦福人工智能研究所发布的《2023 年 AI 指数报告》,大语言模型 GPT-3 一次训练的耗电量为 1287 兆瓦时,相当于排放了 552 吨二氧化碳。随着 AI 的进一步普及,预测到 2025 年,AI 相关业务在全球数据中心用电量中的占比将从 2% 增加至 10%。到 2030 年,智能计算年耗电量将达到 5000 亿千瓦时,占全球发电总量的 5%。
除了算力与能耗,当大模型进入行业落地阶段,定制化和运营成本也成为新的核心矛盾。以最新发布的 Llama 3.1 405B 为例,需要 450GB 显存;0.6B pixart 在 A800 上生成 4096 px 的图片需要 3 分钟,对业务提出了极高的要求。
如何在更多的业务上应用大模型,同时降低成本,提高效率,成为行业普遍需要解决的问题。
业内推理引擎方案
在大语言模型的和用户的交互过程中,推理框架是 AI 的核心引擎,负责接收用户的请求,并且将其进行处理和回应。整个 AI 行业都在探索如何高效利用计算资源,并行处理更多的推理请求,从而针对现有的推理构架做优化,推出新的异构算力的解决方案。
vLLM 是伯克利大学组织开源了大语言模型高速推理框架,使用 PagedAttention 高效管理注意力键和值内存,支持连续批处理和快速模型执行,通过引入操作系统的虚拟内存分页思想,提高语言模型服务在实时场景下的吞吐与内存使用效率。
除 vLLM 外,众多大模型上下游厂商也纷纷给出了自己的方案:
Text Generation Inference(TGI)是 Hugging Face 推出的支持 Hugging Face Inference API 和 Hugging Chat 上的 LLM 推理的工具,旨在支持大型语言模型的优化推理。
TensorRT-LLM 是由 NVIDIA 推出的在 TensorRT 推理引擎基础上针对 Transformer 类大模型推理优化的工具,支持多种优化技术,如 kernel 融合、矩阵乘优化、量化感知训练等,以提升推理性能。
DeepSpeed 是由微软开发的分布式训练工具,旨在支持更大规模的模型,并提供了更多的优化策略和工具,如 zero、offload 等。支持多种并行策略,如数据并行、模型并行、流水线并行以及它们的组合(3D 并行),可以在多个维度上优化模型的训练和推理。
LightLLM 是一个基于 Python 的 LLM 推理和服务框架,以轻量级设计、易于扩展和高速性能而闻名。LightLLM 利用许多备受好评的开源实现优势,包括 Faster Transformer、TGI、vLLM 和 Flash Attention 等。
这些框架有着不同的技术特点,具体性能和优势也会因不同的应用场景、模型配置和硬件环境而有所差异,但依然没有解决核心的成本问题。为此,腾讯推出了 TACO-LLM 大模型推理加速框架,为定制化、自建、上云、私有化提供完整部署方案和极致性价比。
TACO-LLM 如何实现降本增效?
TACO-LLM (TencentCloud Accelerated Computing Optimization LLM)是基于腾讯云异构计算产品推出的大语言模型推理加速引擎,通过充分利用计算资源的并行计算能力,可同时处理更多的用户请求,提高语言模型的推理效能,为客户提供兼顾高吞吐和低时延的优化方案,帮助客户实现降本增效。
针对各个应用场景,Taco-LLM 的优化大致分为四类:Generation 优化、Prefill 优化、长序列优化与高性能量化算子。接下来对这四个场景进行详细介绍:
使用并行解码进行 Generation 优化
Generation 优化是自回归式 LLM 最重要的优化之一,几乎覆盖所有 LLM 应用场景。例如:文案创作、智能客服、聊天机器人、代码生成、咨询系统、AI 助手等; 这里 Taco-LLM 用到并行解码,高性能算子等技术。Taco-LLM 使用并行解码的主要优势有:
1、并行解码突破自 Transformer-Decoder 架构下的回归限制,缓解 Generation 过程bandwidth bound 问题。
2、与单纯增加 Generation 过程的 batch-size 相比,并行解码是通过降低每一条请求的延时来增加吞吐,可以保证更低的 TPOT。
3、与增加 memory bandwidth 的异构方案相比,并行解码不需要异构化集群,部署成本更低,系统更加简单易维护。
Taco-LLM 在并行解码上的主要尝试是自预测方案,一是它解决了小模型从哪里来的问题,只需要使用大模型的部分层或者量化后的大模型当作小模型即可,用户不用感知 draft model 的存在,二是该方案相比其他方案有较高的命中率,较小的冗余计算,主要用于 70B+ 的大模型推理加速。除自预测方案之外,Taco-LLM 也支持 RawLookaheadCache 和 TurboLookaheadCache 两种 cache 方案,减少冗余计算,提高性能与整体命中率。
使用 Prefix Cache 技术降低 TTFT
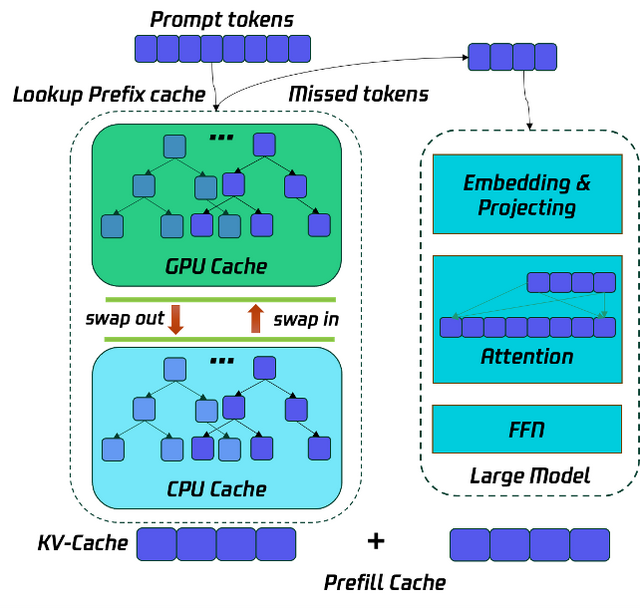
Prefill 优化的主要目标是降低 TTFT,优化用户使用体验,这里常用的优化是多卡并行,例如 TP 和 SP,来降低 TTFT,Taco-LLM 在此基础上使用 GPU & CPU 结合多级缓存的 Prefix Cache 技术,让一部分的 prompt token 通过查找历史的 kv-cache 获得,而不用参与 Prefill 阶段的计算,减少计算量,从而降低 TTFT。这项技术在代码助手场景尤其有效。
为了节省 Prefill 的运行时间,将历史的请求的 prefill cache 按照前缀树的方式保存在 GPU & CPU 中,从而将 Prefill 的计算过程转化为 KV-Cache 的查询过程,并将没有命中的 Tokens 参入 Prefill 的计算,从而降低计算开销,降低 TTFT。如下图所示:
长序列推理优化中的 TurboAttention
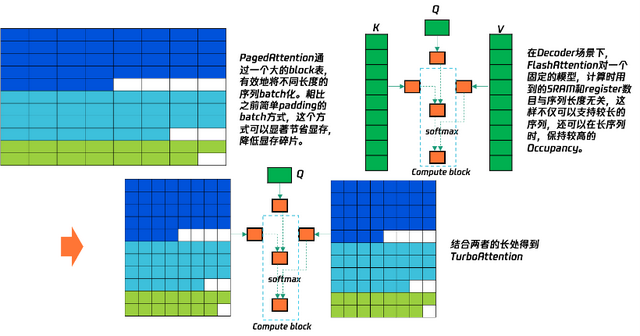
长序列优化分为 Prefill 阶段的长序列,例如文本摘要,信息检索等,和 Generation 阶段的长序列,例如长文本创作等。前者用到 Prefix Cache 和多卡并行推理技术,对于后者我们自研了 Turbo Attention 系列算子和一些优化后的量化算子。
Taco-LLM 长序列能力主要体现在 TurboAttention、Prefix Cache、和序列并行上,这里主要介绍 TurboAttention。TurboAttention 结合了 Page 管理机制和Flash机制,专门为长序列下Lookahead实现的Kernel,如下图所示:
通过 LLM 量化技术降低推理成本
随着 LLM 模型参数迅速增加,LLM 的推理延时和推理成本也急剧上升。LLM 量化技术成为优化 LLM 推理性能,降低推理成本的一种重要手段。高性能量化算子对于一些对精度要求不高的场景,像文本分类,文本异常检测,文本润色等,量化往往有较好的效果,可以有效减少 GPU 内存占用,提升推理速度。
为了达到量化预期的目标,高效的量化算子实现是必不可少的,Taco-LLM 针对 GEMM 和 Attention 两类算子,开发了权重计算感知重排、任务调度和同步策略、快速反量化、Integer Scale 技术等多个高效的量化算子技术。
总的来说,Taco-LLM 的优化包括:通过并行解码进行投机采样和 LookaheadCache;Prefix Cache 的 GPU & CPU 的多级缓存技术以及内存管理技术;长序列主要包括自研的 TurboAttention 系列算子、Prefix Cache 和序列并行等;高性能量化算子包括 Taco-LLM 对 W4A8,W4A16,W8A16,W8A8 等量化算子的高效实现。
TACO-LLM 实际效果与应用案例
通过各项优化技术,TACO- LLM 在性能以及成本,相较于现有的开源和厂商框架,有了明显的优势,且在易用性上完全对齐 vLLM。
TACO 的性能优势直观体现在帮助大模型服务提高吞吐和降低延迟。在 TACO 加速引擎的支持下,相同的硬件设备上能够处理的 Token 数量显著增加,原本每秒能处理 100 个 Token,TACO 加持后每秒能处理 200 甚至 300 个Token。吞吐的提升没有以牺牲延迟为代价,相反每个 Token 的平均处理时间大大降低,代表响应效率和用户体验的提升,LLM 部署的成本也随之大幅降低。
以 Llama – 3.1 70B 模型为例,在使用 4 张 Ampere 实例,输入序列长度为 1 K 左右,输出 为 400 左右,Bs = 1,2,4,8 的测试场景中,相较于业内主流的 vLLM,TACO – LLM 的吞吐性能相对于社区 SOTA 提升 1.8~2.5 倍;营运成本降低 44~64%,且使用方式、调用接口保持一致,支持无缝切换。
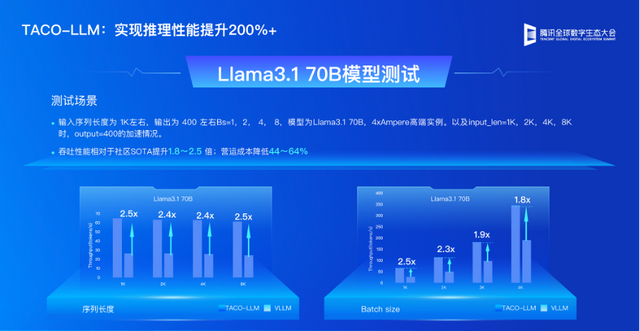
同样以 Llama-3.1 70B 为例,使用 TACO-LLM 部署的成本低至 <$0.5/1M tokens,相比直接调用 MaaS API 的成本节约超过 60%+,且使用方式、调用接口保持一致,支持无缝切换。TACO – LLM 卓越的能效比显著降低了 LLM 业务成本,在广泛的实际场景中实现了降本增效:
在微信某文本处理业务中,TACO – LLM 吞吐性能相对于竞品提升 2.8 倍,营运成本降低 64%,超时失败降低约 95%,进一步扩大支持文本的最大长度。
在某头部视频平台业务中,客户希望在自建高端实例上部署推理服务,要求相对厂商官方推理框架性能提升 50% 以上。最终,TACO-LLM 在不同 bs 下相对竞品性能提升 1.7~2.5 倍。
在顺丰某业务中,TACO – LLM 在短输出场景,在不同 bs 下,加速幅度为 2~3 倍;在长输出场景,在不同 bs 下,加速幅度为 1.4 到 1.99 倍。
TACO – LLM 的出现打破了以往高昂成本对人们使用 AI 的限制,不仅能够满足用户对高吞吐和低时延的需求,还能帮助企业降本增效,为大语言模型的应用提供了一种更高效、更经济的解决方案,
在未来,随着技术的不断迭代,TACO – LLM 有望在更多领域得到广泛应用,推动行业的发展和创新,让 AI 真正走进了人们的生活,成为人们学习和生活的得力助手。
- 当购物用上大模型!阿里妈妈首发世界知识大模型,破解推荐难题2025-05-01
- 人人可用的超级智能体!100+MCP工具随便选,爬虫小红书效果惊艳2025-04-29
- OceanBase全员信:全面拥抱AI,打造AI时代的数据底座2025-04-27
- 网易有道张艺:AI教育的规模化落地,以C端应用反推大模型发展2025-04-27

相关阅读




腾讯云发起“优才计划”,携手中软协构建数字化人才培养新生态
腾讯云宣布发起“优才计划”并率先与中国软件行业协会达成合作,携手打造“人才培养”到“人才输出”闭环新模式,构建数字化人才培养新生态,为新基建下的产业互联网发展提供人才支撑。