
MiniMax不藏了,大秀视频/语音/文本全模态模型家族,“每天与世界交互30亿次”
Intelligence with Everyone
明敏 衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
终于,MiniMax不藏了。
首次正式公开亮相,最强大模型、最亮眼产品战绩,全部对外展示。

模型全家桶最新版齐上阵,从文本、语音到视频覆盖全模态——达成如此丰富模态且同步开放,属实是国产创业公司中首位。
尤其是视频模型如期发布,兑现了7月WAIC上创始人兼CEO闫俊杰放出的承诺。
旗下产品最新战绩也正式公开:
每天30亿次交互量。
其中生成文本量3万亿文本tokens,生成图片2000万张、生成语音7万小时。
什么概念?
- 30亿次文本交互=3000人一辈子的文本处理量;
- 2000万张图片=400座故宫的画作收藏量;
- 7万小时语音=读完7000本书。
而3万亿文本tokens这个数据处理量,在第一梯队其它友商披露出5千到1万亿tokens日处理量的当下,也有断层优势。
需要注意的是,这些数据,都是1天时间内在MiniMax产品上产生的。

一直以来,无论技术、产品还是融资,MiniMax一有风吹草动,都会引发海内外各界关注。但他们始终保持着闷声搞事的路线。模型发布、产品上线总是让人猝不及防,公开的大型活动更是几乎没有。
成立近1000天,MiniMax到底想做什么?外界的好奇,早已呼之欲出。
终于,带着最能证明实力的技术和产品,闫俊杰站在自家聚光灯下给出回答。
Intelligence with Everyone
这是MiniMax的愿景,更是路径。
初创公司中首先拿下全模态
MiniMax想要做什么?
先来看最新技术进展——
本次活动上一共发布了4种模态大模型,分别是:
- 视频模型,abab-video-1
- 音乐模型,abab-music-1
- 语音模型,abab-speech-1
- 文本万亿多模态模型,abab-7
这些模型,支撑起了全国最大的AI交互量,在一年前的今天,当时的交互时长大约只有ChatGPT的3%;到了今天,交互时长已经超过了其50%。
也构筑起了MiniMax的坚实壁垒——放眼国内AI大模型初创公司,MiniMax率先完成了全模态模型的研发和开放。
实力不可谓不雄厚。
其中最值得说道说道的,是MiniMax视频模型abab-video-1以及语音大模型abab-speech-1。
视频模型abab-video-1
视频模型是今年自Sora发布以来最热门的模型选手。
从文生图时代一路传承下来的宇航员骑马,也成为了各家视频模型小试牛刀的必考题。
我们自然也没放过MiniMax家的abab-video-1(手动狗头):

不只是我们,哪怕是在X上,网友们也已经玩疯了!
AI电影人迫不及待用abab-video-1做出了超越自己前作的电影《地狱之地》。

还有些网友脑洞大开,想出的提示词都别具一格:
一位留着长胡子的标志性亚洲美女,身穿比基尼,沿着海岸线向镜头跑去。夕阳透过云层在背景中闪烁,所有这些都以慢动作捕捉。
但abab-video-1压根没在怕的:

据了解,abab-video-1画质方面最高支持1280*720的25fps,“拥有电影感镜头移动”,并且支持带文字元素。
目前AI视频时长最高6秒,未来或支持10秒。
除了现有的文生视频功能,未来还将推出图生视频和文图结合生成视频的能力。
综合官方demo和人肉测试,MiniMax视频模型有两个非常显著的特点,一个是一致性连贯性方面,视频中所有的画面主体,几乎不会发生剧烈形变或崩坏的情况。

另一个是视觉呈现方面,所有生成视频内容整体画面色彩偏鲜艳。

划重点:限时免费。
官方口吻是,今后新版本达到满意状态后,考虑开启商业化计划。
视频生成的复杂度远高于文本,包括处理长上下文、巨大的存储需求以及基础设施升级等问题,同时视频背后的存储量很大,100个文字可能不到1k,但5秒视频占据几兆之多。
不过闫俊杰表示:
我们确实在视频模型生成方面取得很大的进展,根据内部评测以及跑分,我们比其他模型的(生成视频)效果都要好。
相比已经在国际市场上打响名声的国内视频模型先头兵快手可灵,MiniMax的视频生成模型推出时间晚了一两个月。
闫俊杰说,这是因为团队一直在解决更具挑战性的技术问题,特别是如何训练算力较高的内容。

语音模型abab-speech-1
接着来聊一聊MiniMax的语音模型。
只需要20秒真人语音作为语料数据,喂给abab-speech-1,几乎只用眨一次眼睛的时间,AI语音就热乎出炉了。
如果要用一组词来形容abab-speech-1的特色,那大概可以是不同音色、饱满情绪、多种语言、轻松生成。
而且,是超拟人的那种。
具体来看,它能支持多种语言的语音,譬如中文、英文、西语、日语,国内方言如粤语也不在话下。
听起来也真的很去“AI味”,跟真人发送的语音消息一般无二。
有实例为证——之前央视节目《嗨!AI-音乐季》中,MiniMax语音大模型对歌手龚琳娜的语料进行采集、分析、模拟。
然后AI龚琳娜语音和其母亲打了个电话,完全没有被识破。
虽然叫“语音大模型”,但其实它兼具音乐生成的能力。
只需经历输入灵感——生成歌词——选择风格——生成歌曲四个简简单单的步骤。
曲风上面,不管是节奏布鲁斯、说唱还是电子,都轻松拿捏。
别看它刚刚亮相,但其实MiniMax的语音大模型从去年11月开始就已经上岗就业。
迄今为止,它服务了近500家企业用户,在语言学习、PC语音助手、语音声聊唱聊、超拟人情感配音等十余种场景都有落地案例。

上述所有的一切,都基于MiniMax的技术底座构建。
在底层技术上,MiniMax核心关注3方面:
- 持续降低模型错误率
- 无限长输入输出
- 多模态
这是模型之上的产品,能够更快更强的关键要素。
闫俊杰认为,大语言模型领域,两个模型性能相似,一定是速度更快的那个模型更容易带来产品数据增长。就好像Scaling Law一样,算法相同情况下,训练数据量更大的模型往往会取得更好效果。
在如何让模型变得更快上,MiniMax做了两次重大的技术变革:第一是MoE,第二是Linear Attention。
这两者,都集中体现在数周后将正式对外的多模态模型abab-7身上,没错,就是使用MoE+Linear Attention技术的那种。
首先是在MoE(混合专家模型)尚未形成共识时,就已经决心押注,并且身体力行地在路上。
展开来说,今年1月,MiniMax发布了国内首个MoE大语言模型abab-6;又很快地在4月推出了abab-6.5系列。
基于这个结构,模型可以处理复杂任务,同时提升计算效率,在单位时间内训练更多(多到“足够多”)的数据。
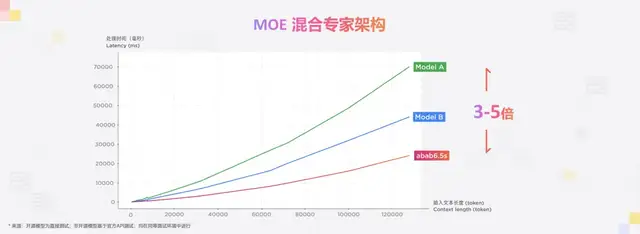
MiniMax官方表示,其MoE模型取得了比Dense模型快3-5倍的速度。
具体在模型表现上,abab-6.5s在1秒内可以处理近3万字的文本。
其次是对Linear架构的选择。
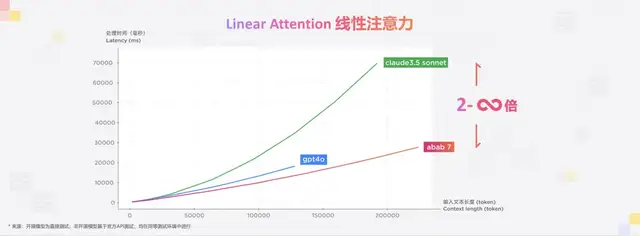
过去的线性注意力存在缺陷,建模效果逊于标准注意力,速度也不如标准注意力,且召回能力有限,使得复杂推理能力偏弱。
针对这些问题,MiniMax设计了全新的Linear架构,在保证精度和效率的同时,解决了Linear Attention召回能力弱的问题,使得新架构可以适用于复杂推理任务。
在Benchmark上,新Linear架构达到相同效果所需训练算力减少了三成;推理侧,尤其是长文推理成本显著降低,128k窗口推理成本下降到二分之一,10M窗口推理成本甚至降低了85%。
另外,面对快速增长的推理压力,MiniMax一边进行上下文缓存持久化(即把对话历史的LLM Attention kv cache持久化/半持久化保存下来、持续复用)和多阶段推理(即在容器层面保持单一用途),提升性能和资源的利用效率。
另一边,MiniMax的模型背后是超大的推理集群,支持海量高并发吞吐,以此支撑将各个版本、各个模态的模型应用于大规模用户产品中。
不难看出,算力实力打底,全模态多点开花,作为国内最早入局大模型创业的公司之一,MiniMax凭借着自己雄厚的研发实力稳步向前。
大模型每天30亿次交互
所有的技术积淀,都只为了一个目的:
Intelligence with Everyone。
目前,MiniMax旗下主要有四款产品:星野、Talkie、海螺AI和开放平台。
前三者主打2C,开放平台更多面向开发者。
2C不难理解,这代表了更广阔的市场。不过为什么要做这么多产品?
一方面,从触及所有人的目标出发,多个不同定位的产品,能更快速触达更多用户。
另一方面,站在初创公司内部视角来看,多尝试才能找到真正正确的答案。与此同时,闫俊杰认为对于初创公司,如果没有足够好的产品能力来承接技术,那么哪怕取得了一定的技术进展,这些东西最终也不是你的。
但如今,行业对于大模型的商业化路径都还模棱两可。技术和产品之间该如何平衡,哪个更重要?
在闫俊杰的最新分享中给出了回答:以Intelligence with Everyone为起点,技术和产品密不可分。
产品是技术落地的平台,它能直接体现技术的价值,也是实现AGI愿景的必要路径。技术是产品前进的核心驱动力。如何抵达Intelligence with Everyone的终局,核心只有两点:
- 怎样提升用户的渗透率
- 怎样提高用户的使用深度
我们认为提升这两点只能通过一件事来完成,一句话总结:科学技术是第一生产力。
比如,如何提高渗透率。转化到技术角度,应该考虑的是如何持续降低模型错误率、无限长度的输入和输出以及多模态。
降低模型错误率是为了让模型能处理更复杂的任务,这是增加用户使用深度的核心手段。
让模型的输入输出尽可能长,则是让AI更进一步像人。
考虑到人类社会中,文字信息的占比非常小,更多信息交流是通过语音、图文、视频来传递,所以多模态也很重要。
基于这些产品方面提出的要求,MiniMax提出了“快就是好”,通过技术创新,来让模型变得更快、更好,这一点在他们的最新技术成果MoE+Linear Attention架构中也已全面展示。
每当模型有重大提升后,MiniMax也能直接从用户层面得到反馈。比如使用深度显著变高,也会遇到对话量显著下滑的事故。而这也更进一步验证了在AI领域里,技术和产品之间密不可分的关系。
目前,MiniMax的产品每天可产生30亿次交互,积累用户超过6000万。
其中有诸多企业客户,比如快递100、智联招聘。MiniMax的模型可以完成客服服务、地址补全、甚至是OKR调整等任务。
更多的是广大普通用户,他们每天在星野、海螺AI上与AI对话。AI创造的形象、智能体也成为了他们日常生活的一部分。
不鸣则已
成立996天,MiniMax终于自己搭建了舞台,完成了对外首秀。
为什么要等这么久?
毕竟,MiniMax从不缺关注度。明星创始团队、热门AI应用、一笔又一笔大额融资……只用跨一步,MiniMax就能完成华丽的登台亮相。
等到现在,或许是公司策略上的考量,或许是团队个性使然。
一方面,MiniMax似乎更愿意用实绩说话。
产品每天30亿次交互、3万亿token处理量,大概已是国内公司中的No.1,“并且可能比第二名多2-3倍”。底层MoE模型,在性能和效率上都已验证实力,6000万用户就是最好的证明。以及率先达成全模态能力,不发模型则已,一发就是视频语音音乐全都来。
更重要的是,MiniMax的路线已被验证。
Intelligence with Everyone。技术和产品并驾齐驱,让MiniMax能更快从用户侧得到反馈,在技术上进行提升、产品上进行优化。重2C但是也做2B,满足普通用户和开发者的需求,当然也是更健康的商业模式。
最关键的是,带着这样一份亮眼的成绩单首秀,MiniMax的实力不言而喻。
另一方面,MiniMax绝对称得上是一家有个性的初创公司。
大模型目前仍旧是一个非共识议题,技术路线的选择一定程度上决定公司的生死。
闫俊杰曾直言,自己选了一条非常激进的路线。
去年,在其他公司还在迭代稠密模型时,闫俊杰转去赌MoE路线。大模型趋势日新月异,几个月时间里别人都在快速进步,但MiniMax把80%以上的算力和研发资源都用来做MoE,且没有Plan B。
过程中,前后失败了两次。模型训了半个月,指标离前期估测越来越远。背后不仅是团队精力、时间、资金的巨大投入,也是对信心的考验。
换来的是,MiniMax成为国内首个推出MoE大模型的公司。也刚好和OpenAI走在了同一条路线上。
从外部视角来看,有能力、有个性是MiniMax最为鲜明的特点。
而从内来看,闫俊杰表示,MiniMax的内核要素还有最重要的一点:乐观。
我们对技术的进步充满了乐观,对用户充满了乐观,对产品的迭代效率充满了乐观。
尽管有时候会遇到很多挑战,但是我觉得我们可能是大模型里面能够最坚持往前来迭代技术,最坚持跟用户互动的大模型公司,也是最国际化的一家大模型公司。
悲观者正确,乐观者永远勇于前行。
完成首秀后,MiniMax的脚步也一点不停歇。
在活动上,闫俊杰放出重磅预告,最新一代旗舰模型abab-7即将正式亮相。
结合最近OpenAI风声不断,新一代模型呼之欲出。
那么国内,谁能是最快追赶的呢?有好戏看了。
- 把1个脑洞发展成1场顶会workshop,阿里妈妈只用了1年|直击NeurIPS’242024-12-16
- 直击CCAI大会:院士专家舌战激辩,20个AI案例C位出道,海淀无愧AI科技“梦工厂”2024-12-15
- ChatGPT搜索与Her打通了!搜索免费开放,居然还剧透明日直播主题2024-12-17
- 《2024年度AI十大趋势报告》发布:技术创新、产品洗牌、行业动态一文看尽2024-12-13
相关阅读




无一大模型及格! 北大/通研院提出超难基准,专门评估长文本理解生成
像Claude3-200k,GPT4-32k、GPT4-8k、GPT3.5-turbo-6k、LlamaIndex这种商业模型,平均只有40%的准确率。






