飞桨框架进阶3.0!一文讲透“大模型训推一体”等五大新特性
为产学研各界提供稳定支持
深度学习框架作为基础软件,不仅促进了深度学习技术的飞速进步,更为人工智能技术的广泛应用铺设了坚实的基础。
深度学习框架为开发者提供了便捷易用的开发接口,这些接口对数据和操作进行了高度抽象,使得开发者能够更专注于算法和模型的设计,而不必深陷底层数据的处理细节。通过这些接口,开发者无需直接感知和应对复杂的硬件底层开发细节,从而极大地提升了开发效率和体验。其次深度学习框架还提供了自动微分这一强大功能,开发者通常只需要编写前向传播网络的代码,而繁琐的反向传播网络则交由框架自动完成。
飞桨作为中国首个自主研发、功能丰富、开源开放的深度学习平台,从默认使用静态图的1.0版本,到默认采用动态图并可实现动静统一与训推一体的2.0版本发布,飞桨框架已经可以完美融合动态图的灵活性与静态图的高效性,并支持模型的混合并行训练;再到近日,为大模型时代而锤炼的3.0版本的正式出炉!飞桨正式开启了新一代框架技术创新之路!
设计思想
深度学习框架的设计对于推动人工智能技术的发展至关重要,其核心设计目标是让深度学习技术的创新与应用更简单。
如何做到这一点呢?
框架需要充分考虑开发者和硬件厂商的需求。
从用户角度出发,一个优秀的深度学习框架应当为开发者提供极致的开发体验。这不仅仅意味着提供一个用户友好的开发环境,更重要的是要能够大幅度减少开发者的学习成本和时间成本,同时显著提升开发的便利性。为此,飞桨框架提出了“动静统一、训推一体、自动并行”的理念,极大地提高了开发效率。
从硬件适配角度出发,现代深度学习应用往往需要在多样化的硬件平台上运行,因此,框架必须能够兼容并适配各种不同的硬件设备。这要求框架能够智能地隔离不同硬件接口之间的差异,实现广泛的硬件适配性。同时,为了充分发挥硬件的性能,框架还需要具备软硬件协同工作的能力,确保在利用硬件资源时能够达到最优的性能表现。
与此同时,好的框架还需要考虑到 AI 技术发展的整体趋势、产业的实际落地应用的需求。
技术发展层面,大语言模型(Large Language Model,简称LLM)、 MOE(Mixture of Experts)、多模态以及科学智能(AI for Science)等前沿技术逐渐成为新的研究热点。随着模型复杂性的增加,计算瓶颈、存储瓶颈、访存瓶颈以及通信瓶颈等问题逐渐凸显,对分布式训练和通用性能优化的需求日益迫切。
在产业化层面,框架又需要具备支持训练、压缩、推理一体化的全流程能力。这意味着,从模型的训练到优化,再到实际部署和推理,框架应当提供一套完整、高效的解决方案,才能满足产业界对于深度学习技术的实际需求。
只有跟得上趋势、经得住打磨的框架,才能为产学研各界开发者提供持续稳定的支持。
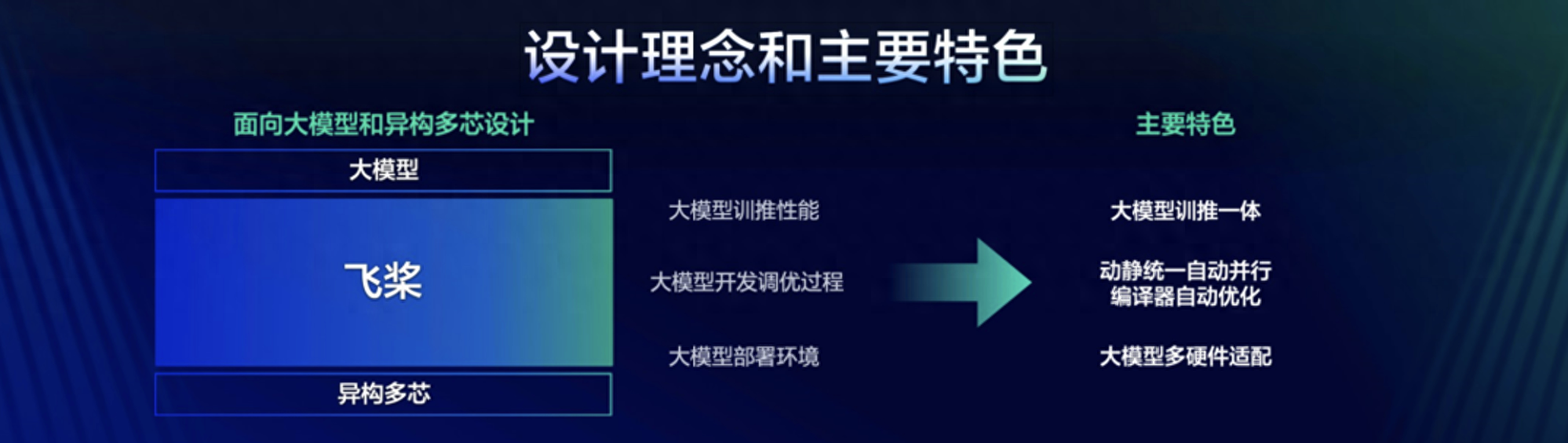
飞桨框架3.0的设计理念和主要特色
综上需求,飞桨将为开发者提供一个“动静统一、训推一体、自动并行、自动优化、广泛硬件适配”的深度学习框架,开发者可以像写单机代码一样写分布式代码,无需感知复杂的通信和调度逻辑,即可实现大模型的开发;可以像写数学公式一样用 Python 语言写神经网络,无需使用硬件开发语言编写复杂的算子内核代码,即可实现高效运行。
飞桨框架 3.0 版本应运而生,延续了2.x 版本动静统一、训推一体的设计理念,其开发接口全面兼容2.x 版本。这意味着,使用2.x 版本开发的代码,在绝大多数情况下无需修改,即可直接在3.0版本上运行。着重推出了动静统一自动并行、编译器自动优化、大模型训推一体、大模型多硬件适配四大新特性。这些特性在飞桨框架2.6版本或更早版本时就已经开始开发,目前已达到外部可试用的阶段。这些新特性在使用体验、性能、二次开发便利度以及硬件适配能力等方面带来了显著提升,飞桨正式发布3.0版本。此版本包含了对框架2.x 版本部分已有功能的改进,并且在不使用新特性的情况下,表现成熟稳定。
框架架构一览
为了实现深度学习框架的上述特性,必须对框架的架构进行精心设计,确保其能够支持各种复杂的模型构建,同时与多样化的芯片实现无缝对接。接下来,将通过直观的架构图,详细展示飞桨新一代框架内所涵盖的功能模块,以及这些模块之间的相互作用与联系。以下为飞桨框架3.0的架构图。

飞桨框架 3.0 架构图
丰富接口:飞桨框架对外提供了丰富的深度学习相关的各种开发接口,如张量表示、数学计算、模型组网、优化策略等。通过这些接口,开发者能够便捷地构建和训练自己的深度学习模型,无需深入到底层的技术细节中去。
在开发接口之下,飞桨框架可以划分为4个层次:表示层、调度层、算子层和适配层。
表示层:专注于计算图的表达与转换,通过高可扩展中间表示 PIR,为动转静(动态图转为静态图)、自动微分、自动并行、算子组合以及计算图优化等核心功能提供坚实支撑。
调度层:负责对代码或计算图进行智能编排与高效调度,并且能够根据实际需求进行显存和内存的管理优化,支持动态图和静态图高效执行。无论开发者选择使用动态图还是静态图进行模型开发,飞桨框架都能提供高效的执行环境,同时确保资源利用的最优化。
算子层:由神经网络编译器 CINN 和算子库 PHI 共同构成,涵盖了张量定义、算子定义、算子自动融合和算子内核实现等关键功能。
适配层:则用于实现与底层芯片适配,包括设备管理、算子适配、通信适配以及编译接入等功能。
下面将重点介绍飞桨3.0版本架构全新重大升级,这次升级主要包含以下模块:
1)高扩展中间表示 PIR,通过打造全架构统一的中间表示,突破框架层各模块壁垒,提升飞桨在科学计算、编译优化、大模型领域的潜力;
2)神经网络编译器自动优化,通过自动融合和策略调优,大幅提升模型端到端表现;
3)自动并行,降低大模型场景模型开发和性能优化的成本,大幅提升大模型场景的用户体验。
高扩展中间表示PIR
计算图中间表示(Intermediate Representation,即 IR)是深度学习框架性能优化、推理部署、编译器等方向的重要基石。近些年来,越来越多的框架和研究者将编译器技术引入到深度学习的神经网络模型优化中,并在此基础上借助编译器的理念、技术和工具对神经网络进行自动优化和代码生成。在大模型时代,对 IR 在灵活性、扩展性、完备性有了更高的要求。
因此在3.0版本下,飞桨在基础架构层面规范了中间表示 IR 定义,实现全架构统一表示,实现上下游各个方向共享开发成果。飞桨的新一代 IR 架构聚焦于高度灵活和高扩展性两个重要维度,通过更加完备且鲁棒的语义表达能力、训推全架构统一表示和高效可插拔的性能优化策略(Pass)开发机制,实现复杂语义支持,更便捷地支撑大模型自动并行下丰富的切分策略,无缝对接神经网络编译器实现自动性能优化和多硬件适配。
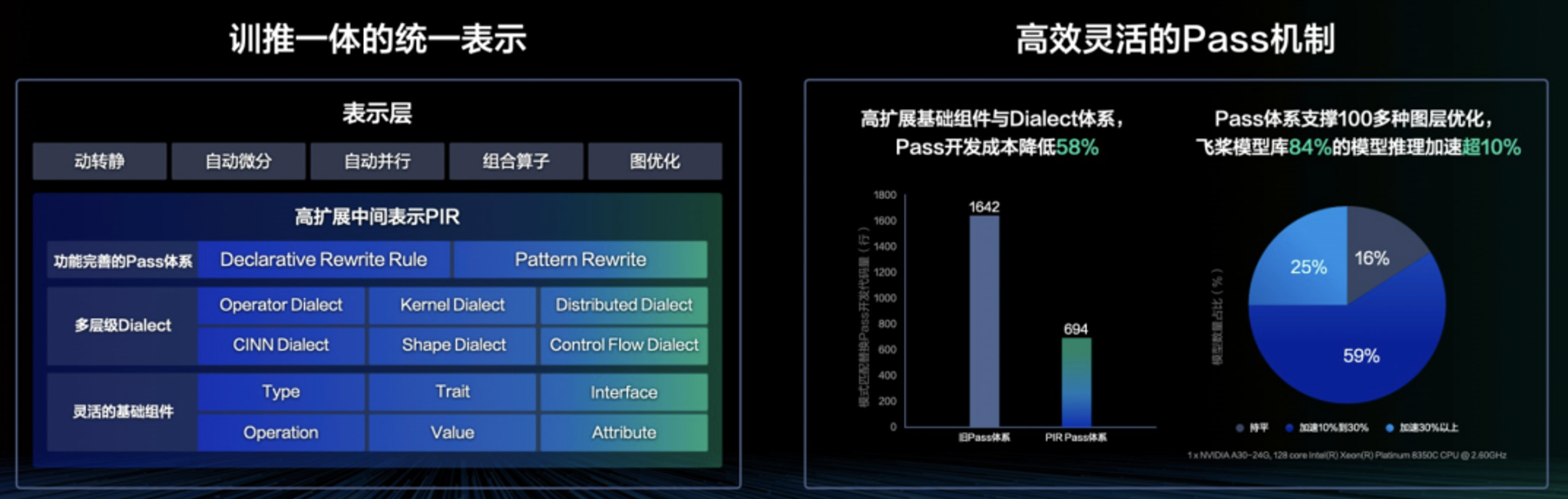
飞桨中间表示(PIR)在底层抽象了一套高度可扩展的基础组件,涵盖 Type、Attribute、Op、Trait 和 Interface,并引入了 Dialect 的概念,赋予开发者灵活扩展与自由定制的能力,从而提供了全面且稳健的语义表达能力。在模型表示层,通过多 Dialect 的模块化管理和统一多端表示,实现了训练与推理一体化的全架构统一表示,实现了算子和编译器的无缝衔接,支持自动优化和多硬件适配。在图变换层,通过统一底层模块并简化基础概念,向用户提供了低成本、易用且高性能的开发体验,以及丰富且可插拔的 Pass 优化机制。飞桨 PIR 坚守静态单赋值(SSA)原则,确保模型等价于一个有向无环图,并采用 Value 和 Operation 对计算图进行抽象,其中 Operation 代表节点,Value 代表边。
Operation 表示计算图中的节点:每个 Operation 表示一个算子,并包含零个或多个 Region。Region 表示一个闭包,它内部可以包含零个或多个 Block。而 Block 则代表一个符合静态单赋值(SSA)原则的基本块,其中包含零个或多个 Operation。这三者之间通过循环嵌套的方式,能够构建出任意复杂的语法结构。
Value 表示计算图中的有向边:它用于连接两个 Operation,从而描述了程序中的 Use-Define 链(即 UD 链)。其中,OpResult 作为定义端,用于定义一个 Value;而 OpOperand 则作为使用端,描述了对某个 Value 的使用情况。
飞桨提供了 PatternRewriter 和 Declarative Rewrite Rule(简称 DRR)这两种 Pass 开发机制,兼顾了自定义的灵活性与开发的易用性。采用三段式的 Pass 开发方式,使开发者能够更加专注于 Pass 逻辑的处理,而无需关注底层IR的细节。利用 PIR 的 Pass 开发机制,实现了 Pass 开发成本降低58%;应用于推理场景,超过84%的模型推理加速超10%。
神经网络编译器自动优化
为什么我们要研发编译器技术,有3个维度的原因:
1)硬件发展趋势:结合硬件发展历史和技术演进特点,算力发展速度远大于访存性能、CPU 性能和总线带宽;其中访存性能影响访存密集型算子(norm 类,activation 等)性能,CPU 性能和总线带宽影响调度性能。基于编译器的自动融合的通用优化技术,可以将多个算子融合成一个大算子,通过减少访存量和算子数量,能够大幅提升模型性能,编译器技术会成为深度学习框架标配组件。
2)模型发展趋势:模型结构存在多样性的特点,多样性的需求非常依赖编译器的通用优化。
3)多硬件优化:当前市面存在有多款硬件,不同的硬件平台有不同的特性和优化需求,每个硬件均需要投入大量的人力进行优化,借助编译器技术,能够大幅降低这类优化技术成本。
让我们通过一个实例来阐释这一点。我们以 Llama 模型中经常使用的 RMS Normalization (Root Mean Square Layer Normalization)为例,其计算公式相对简单明了。

假设我们需要是实现 RMS Normalization 的计算,最简单的办法是,我们可以使用飞桨框架提供的张量运算开发接口,调用平方、求和、除法、开根号等操作来完成,代码如下:

上述代码开发简单,但是性能较差,且显存占比较多;开发者可以进行 FusedRMSNorm 的实现,但是对于开发者要求更高,成本也更高。
借助神经网络编译器技术,我们能够在维持高度灵活性和易用性的基础上,实现性能的显著提升。以下 A100平台上 RMSNorm 算子的性能测试结果便是一个明证:相较于采用 Python 开发接口组合实现的方式,经过编译优化后的算子运行速度提升了 4 倍;即便与手动算子融合的方式相比,也实现了 14%的性能提升。这一成果充分展示了飞桨框架在灵活性与性能之间寻找到的理想平衡点。
为此,飞桨把神经网络编译器技术作为一个重要的研发方向,下面是飞桨编译器的整体架构图。
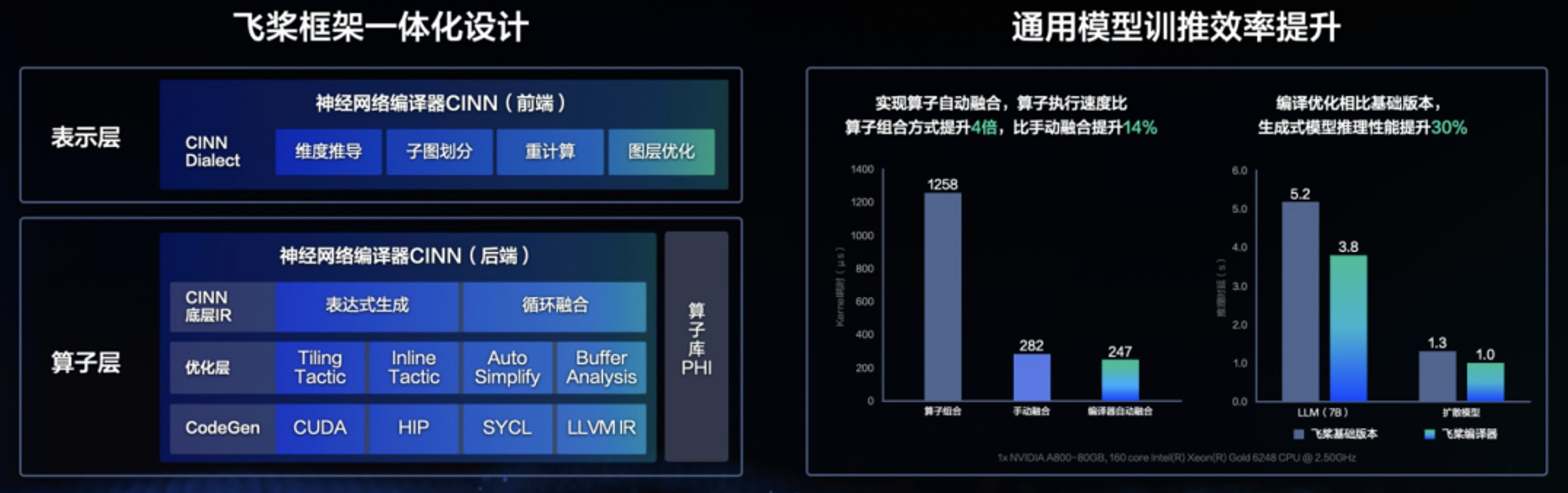
在表示层,借助 PIR 的扩展能力,实现 CINN 前端模块,处理图层相关变换,包含算子拆分、重计算、子图划分、维度推导模块等模块,最终得到多个可被编译器后端生成优化的子图。在编译器后端,对于这些可融合的子图,编译器会进一步调用Compute 函数,将它们转换为由抽象语法树(AST)构成的低层中间表示(IR),并在此基础上进行循环的融合,确保能融合成一个 kernel;在 CINN 底层 IR 上,会进行性能的调优分析,得到最优配置;最后底层 IR 会被进一步精心转换成具体的代码实现。
在生成式大语言模型 Llama 和文生图模型 Stable Diffusion 上的实验结果显示,通过使用编译器的优化技术,相较于未采用手动性能优化的基础版本,推理速度分别实现了 36%和 30%的提升。
动静统一自动并行
为什么我们要做自动并行?
当前大模型主流训练方式,会用到多种并行策略,这些并行策略基于动态图模式实现的“手动”并行方式,即在单卡的基础上,手工处理切分(切分 Tensor、计算图)、通信(添加通信算子)、显存优化(显存共享、Re-Compute)、调度优化(流水线编排、计算和通信异步)等策略,开发者既要熟知模型结构,也要深入了解并行策略和框架调度逻辑, 使得大模型的开发和性能优化门槛非常高。除了要有专门算法团队负责模型算法创新,还必须有专门负责模型并行优化的团队配合,这给大模型的创新和迭代带来了诸多障碍。
我们举一个简单的例子,来阐释下大模型开发和单卡逻辑的差异,由于并行策略会引起 Tensor 运行时 shape 发生变化,所以跟 shape 处理相关算子均需考虑是否会受到并行策略的影响。如下面 reshape 的处理,切分策略导致输入 shape 发生了变换,所以输出的 shape 需要根据切分策略进行合理的调整:

为此,我们提出了动静统一的自动并行方案。开发者仅需少量的张量切分标注,框架便能自动推导出所有张量和算子的分布式切分状态,并添加合适的通信算子,保证结果正确性;最后会根据模型结构和集群信息,结合显存、调度层优化,自动寻找最高效的分布式并行策略。
在自动并行设计中,开发者仅需少量的张量切分标注,我们将切分方式进行抽象,共需两类切分方式:切分张量(参数,输入)和切分计算图(流水线)。为实现这两类切分方式,框架需要一种机制来描述分布式张量和计算设备之前的映射关系,为此我们引入 ProcessMesh 和 Placements 两个分布式概念,其中 ProcessMesh 将一块 GPU 卡映射为一个进程,将多个设备映射为多个进程组成的一维或多维数组,下图展示了由 8 个设备构成的两种不同 ProcessMesh 抽象表示。
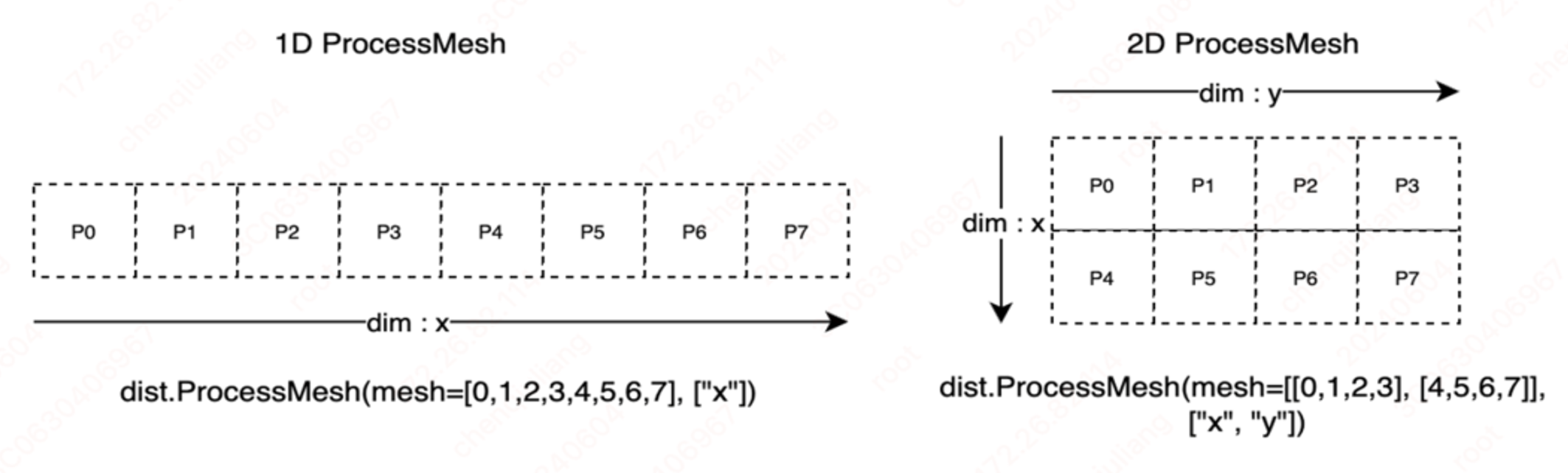
Placements 是由 Replicate、Shard、Partial 三种分布式标记组成的列表,长度和 ProcessMesh 的维度一致,用于表示分布式张量在对应计算设备的维度上,按照哪种分布式标记做切分,这三种分布式标记的详细描述如下:
如下图所示,Replicate 表示张量在不同设备上会以复制的形式存在;Shard 表示按照特定的维度在不同设备上进行切分;Partial 表示设备上的张量不完整,需要进行 Reduce Sum 或者 Reduce Mean 等不同方式的操作后,才能得到完整的状态。
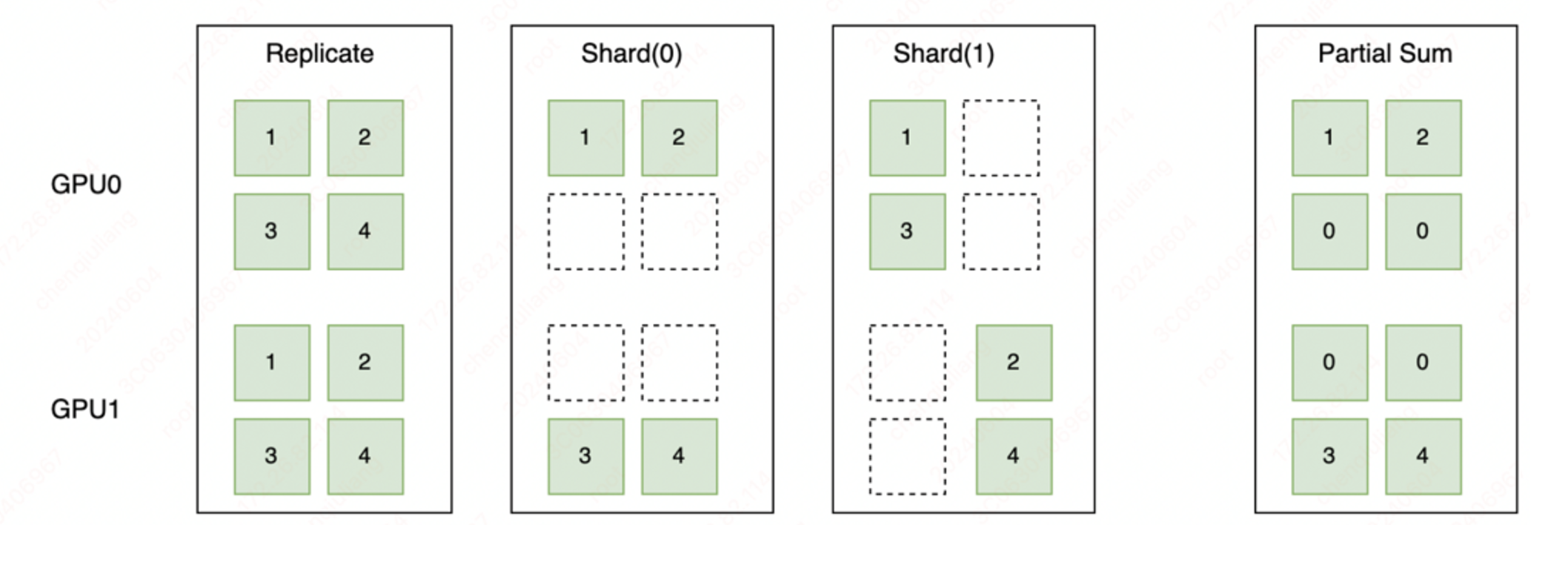
在完成分布式标记抽象后,我们通过调用
paddle.distributed.shard_tensor()接口,实现对张量切分的标记。通过张量切分的标记和自动推导,我们可以表示复杂的分布式混合并行,下图展示了一个具体的数据并行、张量模型并行、流水线并行组成的混合并行的例子。
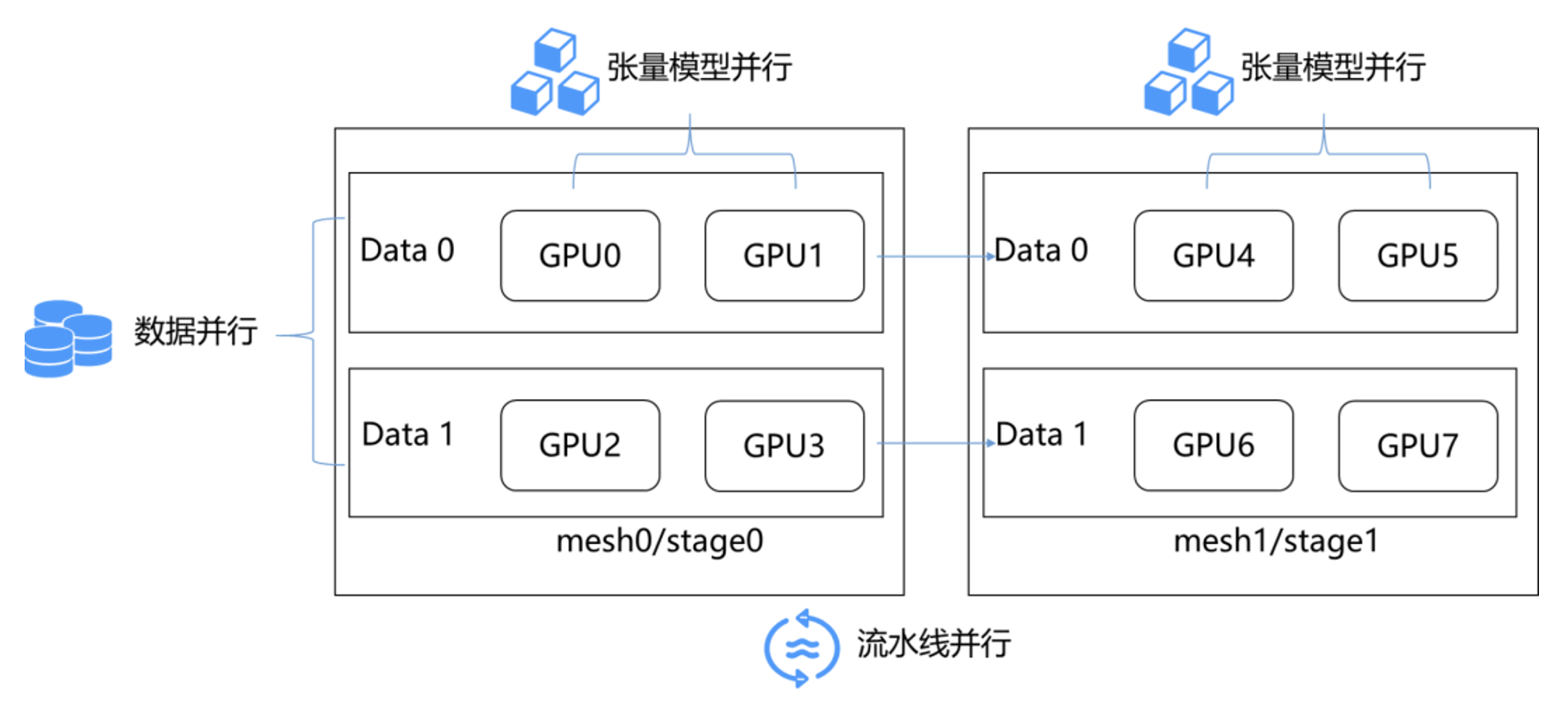
以下代码展示了混合并行的具体例子。

通过采用自动并行的开发方式,开发者无需再考虑复杂的通信逻辑。以 Llama 任务为例,分布式训练核心代码量减少了50%,从而大大降低了开发的难度;从我们的一些实验可知,借助全局的分析等优化,性能也优于动态图手动并行的性能。
未来,我们将进一步探索无需使用张量切分标记的全自动并行,让开发者可以像写单机代码一样写分布式代码,进一步提升大模型的开发体验。
产业优势
总的来说,飞桨新一代框架——飞桨框架3.0-Beta 是面向大模型、异构多芯进行专属设计,向下适配异构多芯,充分释放硬件潜能;向上一体化支撑大模型的训练、推理。同时具有动静统一自动并行、编译器自动优化、大模型训推一体、大模型多硬件适配四大能力,全面地提升了服务产业的能力。
动静统一自动并行:这一功能大幅度降低了产业开发和训练的成本。用户只需在单卡基础上进行少量的张量切分标记,飞桨框架便会自动完成分布式切分信息的推导,并添加通信算子以确保逻辑的正确性。同时,根据模型结构和集群信息,结合显存和调度层的优化,飞桨能自动寻找最高效的分布式并行策略,从而大幅降低混合并行训练的开发成本,使开发者能够更专注于模型和算法的创新。
编译器自动优化:这一功能显著降低了性能优化的成本。飞桨的编译器采用与框架一体化的设计,能够支持生成式模型、科学计算模型等多种模型的高效训练与可变形状推理,为计算灵活性与高性能之间提供了良好的平衡点。通过算子的自动融合和代码生成技术,Llama2和 Stable Diffusion 等生成式模型的推理性能得到了超过30%的提升。
大模型训推一体:这一特性为产业提供了极致的开发体验。它使训练和推理的能力能够相互复用,为大模型的全流程提供了统一的开发体验和极致的训练效率。通过动转静的工作,训练和推理的工作得以无缝衔接。在 RLHF(人类反馈强化学习)训练过程中的生成计算可以复用推理优化,实现2.1倍的加速。同时,推理量化场景复用训练的分布式自动并行策略,效率提升了3.8倍。
大模型多硬件适配:飞桨的重要特色之一是适配异构多芯并充分释放硬件潜能。在接入机制上,飞桨提供了简洁高效的抽象接口和基础算子体系,降低了适配成本。在运行机制上,它优化了调度编排和存储共享等机制,提升了调度效率。从算子内核角度,飞桨提供了编译器自动融合调优方案,以提升端到端的性能。同时,飞桨还为新硬件厂商建设了代码合入、持续集成、模型回归测试等研发基础设施。这些机制保障了新硬件被纳入飞桨的正常发版体系中,用户无需编译即可直接安装试用。飞桨这种功能完善、低成本接入的机制吸引了硬件厂商共同为飞桨贡献了3,456个PR,共包含25,000多个 commits。
这就是飞桨的新一代框架 3.0 ,目前3.0-Beta 版本已面向开发者开放,并且所有的开发接口跟2.0完全兼容,非常欢迎广大的开发者去使用和反馈。
- 火山引擎发布豆包视频生成模型Seedance 1.0 lite2025-05-13
- 刚刚,ChatGPT的深度研究可以连接GitHub了!网友:这是真·RAG2025-05-09
- Bye,英伟达!华为NPU,跑出了准万亿参数大模型2025-05-08
- IDC重磅报告:商汤万象跻身国内AI大模型解决方案市场第一梯队2025-05-08

相关阅读




代码小浣熊Raccoon公测,商汤大语言模型加持,编程效率提升超50%
它支持Python、Java、JavaScript、C++、Go、SQL等30+主流编程语言和VS Code、IntelliJ IDEA等主流IDE。实际应用中,可帮助开发者提升编程效率超50%。