8.6M超轻量中英文OCR模型开源,训练部署一条龙 | Demo在线可玩
OCR从业者重磅开源大礼包
鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
要说生活里最常见、最便民的AI应用技术,OCR(光学字符识别)当属其中之一。
寻常到日常办理各种业务时的身份证识别,前沿到自动驾驶车辆的路牌识别,都少不了它的加持。
作为一名开发者,各种OCR相关的需求自然也少不了:卡证识别、票据识别、汽车场景、教育场景文字识别……
那么,这个模型大小仅8.6M,没有GPU也能跑得动,还提供自定义训练到多硬件部署的全套开发套件的开源通用OCR项目,了解一下?
话不多说,先来看效果。
可以看到,无论文字是横排、还是竖排,这个超轻量模型都有不错的识别效果。
难度略高,且实际生活当中经常遇到的场景也不在话下:
那么,如果情况更复杂一点,这么小的模型能hold住吗?
毕竟,在实际应用场景中,图像中的文字难免存在字符弯曲、模糊等诸多问题。
比如,并不高清的路牌:
主体部分基本都识别无误,只有英文小字部分因为确实比较模糊,识别效果不太理想。
再看一张文字背景复杂的图像识别效果:
出现一个错别字,扣一分。满分10分的话,可以打个9分了。
其实,在实际OCR项目落地过程中,开发者往往面临两个痛点:
1. 无论是移动端和服务器端,待识别的图像数目往往非常多,都希望模型更小,精度更高,预测速度更快。GPU太贵,最好使用CPU跑起来更经济。在满足业务需求的前提下,模型越轻量占用的资源越少。
2. 实际业务场景中,OCR面临的问题多种多样,业务场景个性化往往需要自定义数据集重新训练,硬件环境多样化就需要支持丰富的部署方式。再加上收集数据之类的dirty work,往往一个项目落地中的大部分时间都用在算法研发以外的环节中,迫切需要一套完整全流程的解决方案,来加快研发进度,节约宝贵的研发时间。
也就是说,超轻量模型及其全流程解决方案,尤其对于算力、存储空间有限的移动端、嵌入式设备而言,可以说是刚需。
而在这个开源项目中,开发者也贴心提供了直接可供测试的Demo。
在量子位的实际上手测试中,在移动端Demo上这样一个不到10M的模型,基本上可以做到秒出效果。
在中文公开数据集ICDAR2017-RCTW上,限定图片长边尺寸960px,测试数据与测试条件相同的前提下,将该项目与之前一度登上GitHub热榜的Chineseocr_Lite(5.1k stars)最新发布的10M模型进行测试对比。在模型大小、精度和预测速度方面,结果如下:
该8.6M超轻量模型,V100 GPU单卡平均预测耗时57ms,CPU平均预测耗时319ms。
而Chineseocr_Lite的10M模型,V100单卡预测速度230ms,CPU平均预测耗时739ms。
当然,这里面模型预测速度的提升不仅是因为模型大小更小了,也离不开算法与框架深度适配优化。
项目中给出的Benchmark如下:
作为一名面向GitHub编程的程序员,顿时感到老板再来各种OCR需求都不方了。
而且这个8.6M超轻量开源模型,背后还有大厂背书。
因为出品方不是别人,是国产AI开发一哥百度,他们把这个最新开源的OCR工具库取名:PaddleOCR。
GitHub 地址:https://github.com/PaddlePaddle/PaddleOCR
8.6M的通用OCR模型如何炼成
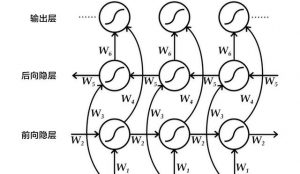
PaddleOCR发布的超轻量模型,主要由4.1M的检测模型和4.5M的识别模型组成。
其中,检测模型的Base模型采用DB算法,文本模型的Base模型采用经典的CRNN算法。
鉴于MobileNetV3在端侧系列模型中的优越表现,两个模型均选择使用MobileNetV3作为骨干网络,可将模型大小初步减少90%以上。
除此之外,开发人员还采用减小特征通道数等策略,进一步对模型大小进行了压缩。
模型虽小,但是训练用到的数据集却一点也不少,根据项目方给出的数据,模型用到的数据量(包括合成数据)大约在百万到千万量级。
但是也有开发者可能会问,在某些垂类场景,通用OCR模型的精度可能不能满足需求,而且算法模型在实际项目部署也会遇到各种问题,应该怎么办呢?
PaddleOCR从训练到部署,提供了非常全面的一条龙指引,堪称「最全OCR开发者大礼包」。
「最全OCR开发者大礼包」
△礼包目录,堪称业界最全
支持自定义训练
OCR业务其实有特殊性,用户的需求很难通过一个通用模型来满足,之前开源的Chineseocr_Lite也是不支持用户训练的。
为了方便开发者使用自己的数据自定义超轻量模型,除了8.6M超轻量模型外,PaddleOCR同时提供了2种文本检测算法(EAST、DB)、4种文本识别算法(CRNN、Rosseta、STAR-Net、RARE),基本可以覆盖常见OCR任务的需求,并且算法还在持续丰富中。
特别是「模型训练/评估」中的「中文OCR训练预测技巧」,更是让人眼前一亮,点进去可以看到「中文长文本识别的特殊处理、如何更换不同的backbone等业务实战技巧」,相当符合开发者项目实战中的炼丹需求。
打通预测部署全流程
对开发者更友好的是,PaddleOCR提供了手机端(含iOS、Android Demo)、嵌入式端、大规模数据离线预测、在线服务化预测等多种预测工具组件的支持,能够满足多样化的工业级应用场景。
数据集汇总
项目帮开发者整理了常用的中文数据集、标注和合成工具,并在持续更新中。
目前包含的数据集包括:
- 5个大规模通用数据集(ICDAR2019-LSVT,ICDAR2017-RCTW-17,中文街景文字识别,中文文档文字识别,ICDAR2019-ArT)
- 大规模手写中文数据集(中科院自动化研究所-手写中文数据集)
- 垂类多语言OCR数据集(中国城市车牌数据集、银行信用卡数据集、验证码数据集-Captcha、多语言数据集)
还整理了常用数据标注工具(labelImg、roLabelImg、labelme)、常用数据合成工具(text_renderer、SynthText、SynthText_Chinese_version、TextRecognitionDataGenerator、SynthText3D、UnrealText)
并且开源以来,受到开发者的广泛关注,已经有大量开发者投入到项目的建设中并且贡献内容。
真·干货满满。
直播课程
为了让开发者深入了解PaddleOCR开源大礼包的更多内容,项目团队还准备了直播课程,现场技术解读答疑,更有丰富“炼丹秘籍”倾囊相授,扫描下方海报二维码,填问卷报名即可加群获取直播链接,在社群与百度资深研发工程工程师深度技术交流。

体验一下?
看到这里,你心动了吗?如果还想眼见为实,PaddleOCR已经提供了在线Demo,网页版、手机端均可尝试。
感兴趣的话收好下面的传送门,亲自体验起来吧~
传送门:
项目地址:https://github.com/PaddlePaddle/PaddleOCR
网页版Demo:https://www.paddlepaddle.org.cn/hub/scene/ocr
移动端Demo:
项目组为开发者在百度大脑EasyEdge上开放了基于飞桨轻量化推理引擎Paddle Lite实现的APP demo。安卓手机可以直接扫码:

iOS版本由于证书限制,需要登录百度EasyEdge网页扫码体验:
https://ai.baidu.com/easyedge/app/openSource?from=paddlelite
— 完 —
- 10秒生成官网,WeaveFox重塑前端研发生产力 | 蚂蚁徐达峰@中国AIGC产业峰会2025-04-30
- 粉笔CTO:大模型打破教育「不可能三角」,因材施教真正成为可能|中国AIGC产业峰会2025-04-18
- GPT-4.1淘汰了4.5!全系列百万上下文,主打一个性价比2025-04-15
- SOTA自动绑骨开源框架来了!3D版DeepSeek开源月大礼包持续开箱ing2025-04-11