
一次可输入多张图像,还能多轮对话!最新开源数据集,让AI聊天更接近现实
微调后模型能生成更长更精确对话
大模型对话能更接近现实了!
不仅可以最多输入20张图像,还能支持多达27轮对话。可处理文本+图像tokens最多18k。
这就是最新开源的超长多图多轮对话理解数据集MMDU(Multi-Turn Multi-Image Dialog Understanding)。

大型视觉语言模型(LVLMs)的核心能力之一是生成自然且有意义的回答,从而能够与人类进行流畅的图文对话。
尽管目前开源的LVLMs在如单轮单图输入等简化场景中展示出了不错的潜力,但在具有长上下文长度,且需要多轮对话和多图输入的真实对话场景中,表现则相对不足。
此外,现有的LVLM Benchmarks主要采用单项选择题或简短回答的形式,难以全面评估LVLMs在真实世界人机互动应用中的表现。
为此,研究团队在论文A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs中提出了全新多图多轮评测基准MMDU及大规模指令微调数据集MMDU-45k,旨在评估和提升LVLMs在多轮及多图像对话中的性能。
目前,该研究在HuggingFace的6月18日Daily Papers中位居榜首,VQA dataset trending榜排名Top3,得到了国内外的广泛关注。

可缩小开闭源模型差距
MMDU基准测试具有以下优势:
(1)多轮对话与多图像输入:MMDU基准测试最多包括20幅图像和27轮问答对话,从而超越了先前的多种benchmark,并真实地复制了复现了现实世界中的聊天互动情景。
(2)长上下文:MMDU基准测试通过最多18k文本+图像tokens,评估LVLMs处理和理解带有长上下文历史的情况下理解上下文信息的能力。
(3)开放式评估:MMDU摆脱传统基准测试依赖的close-ended问题和短输出(例如,多项选择题或简短的答案),采用了更贴合现实和精细评估的方法,通过自由形式的多轮输出评估LVLM的性能,强调了评估结果的可扩展性和可解释性。
在构建MMDU的过程中,研究者们从开源的维基百科中选取具有较高相关程度的图像及文本信息,并在GPT-4o模型的辅助下,由人工标注员构建问题和答案对。
具体而言,研究者将wikipedia词条通过聚类的方法进行合并,划分为多个不同的类别,并在同一个类别中使用不同的词条(包含图文)进行组合。经过InternLM-Chat-20B清洗并去除无用信息之后,交给GPT-4o进行对话生成。生成的基于单词条和多词条的对话进行组合,从而构建具有长上下文的多图多轮对话。
生成的对话以的格式标记图像位置,使用者可以将不同的多图多轮对话进一步组合,从而构建所需长度的对话。
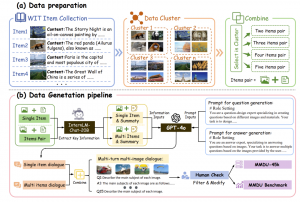
△MMDU和MMDU-45k数据生成pipeline
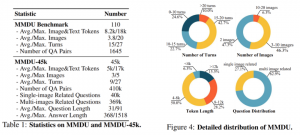
MMDU Benchmark包含的问答最长拥有18k的图像+文本tokens、20幅图像及27轮对话,其规模是以往同类型benchmark的至少五倍,为当前的LVLMs提出了新的挑战。MMDU-45k包含的最长对话数据拥有超17k的图像+文本tokens。
45k的多轮对话共包含超过410k的问答,能够显著提升LVLMs在长上下文理解,多图多轮对话等方面的能力。
受到利用强大的LLMs作为评判的NLP研究的启发,MMDU的研究员们开发了一个使用GPT-4o进行模型性能评估的评估流程。
具体来说,模型在MMDU Benchmark上生成输出后,GPT-4o将根据多个维度评估这些输出结果,并将它们与参考答案进行比较。
为确保全面和细致的评估,MMDU确定了六个评估维度:创造力、丰富度、视觉感知、逻辑连贯性、答案准确性和图像关系理解。为了引导GPT-4o提供平衡和公正的评估,每个维度都有精心制定的评估提示。
每个维度的评分范围为10分,分为五个区间(0-2、2-4…8-10),每个区间都设定了相应的评判标准。GPT-4o遵循这些标准进行评判过程,并为每个维度提供最终分数。

MMDU的评估流程中,使用GPT-4o作为评判,根据参考答案给出总体分数。在每次评估中,GPT-4o将同时参考模型的答案和参考答案。它将为每个评估标准(用蓝色表示)提供相应的分数(用绿色表示),并最终以浅橙色总结结果。
通过对15个具有代表性的开源和闭源LVLMs进行深入分析,研究人员发现开源LVLMs(如LLaVa)由于缺乏足够的对话指令微调数据,相比闭源系统(如GPT-4V)存在较大差距。研究表明,通过对开源LVLMs在MMDU-45k数据集上进行finetune,则可以显著缩小这一差距,finetune后的模型能够生成更长、更精确的对话,同时对于图文交错的多图理解能力有了显著的提升。
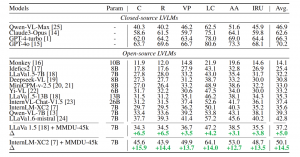
△评估不同LVLMs在MMDU上的表现
团队报告了以下指标:创造力(C)、丰富度(R)、视觉感知(VP)、逻辑连贯性(LC)、答案准确性(AA)、图像关系理解(IRU),以及平均(Avg.)结果。
此外,经过MMDU-45k微调之后的模型,在现有基准测试上表现也有所提升(MMStar: +1.1%,MathVista: +1.5%,ChartQA: +1.2%)。这一结果说明,MMDU-45k能够在各种图像文本相关的任务上提升LVLMs的能力。
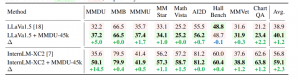
△在LVLM监督微调(SFT)阶段添加MMDU-45k数据的优势。
表中报告了LLaVa和InternLM-XC2在MMDU和现有的代表性基准测试上的表现,包括MMB(MMBench-Dev-EN)、MMMU(MMMU-Val)、MMStar 、MathVista、AI2D、HallBench(HallusionBench)、MMVet 以及ChartQA。每个部分中的最佳和次佳结果分别用绿色和红色标记。
在多图多轮问答及普通单图问答情境下,经过MMDU-45k微调的模型都有显著的性能提升。这一性能提升首先表现在对图像内容的识别上,相比微调前的LVLMs,微调之后的模型能够更加准确的同时理解多张图像的主要内容,图像的顺序,以及图像之间的关系。此外,微调之后的模型能够生成更为详实和丰富的输出,并能够轻松应对具有超长上下文长度的图文对话情景。

InternLM-Xcomposer2在MMDU-45k数据集上finetune前后的表现。错误或幻觉描述在展示中用红色标记,详细且准确的描述则用绿色标记。
- GPT-4o数学能力跑分直掉50%,上海AI Lab开始给大模型重新出题了2024-12-18
- 见证历史!AI想的科研idea,真被人类写成论文发表了2024-12-18
- 21天不用手机,抑郁减少,入睡更快丨正经研究2024-12-17
- OpenAI版《Her》全量来袭:实时视频对话,你每个动作AI都看得见2024-12-13



