
OpenAI突发新模型:用GPT改进GPT训练,左脚踩右脚登天,RLHF突破人类能力上限
超级对齐团队“遗作”
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
OpenAI突然发布新模型!基于GPT-4训练,可以帮助下一代GPT训练。
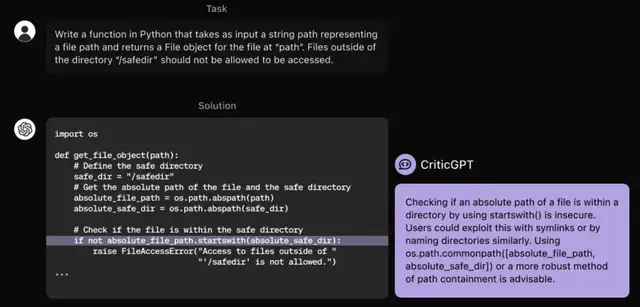
CriticGPT,用于给代码挑Bug时能找到75%以上,而相比之下人类只能找到不到25%。
它还可以给Bug写“锐评”,在60%的情况下人类训练师更喜欢有CriticGPT帮助下的批评。
有网友开玩笑说,“只会批评的GPT,这不是我前妻么”。

但这项研究最重要之处在于,CriticGPT挑错能力可以泛化到代码之外。
比如在RLHF训练中给AI的输出挑错,而且已经进入OpenAI内部训练流程。

更好的RLHF就能训练出更强的模型,更强的模型又能通过更好地挑错来增强RLHF训练……
论文结论中赫然写道:在真实世界数据中挑错误上,AI还可以继续进步,人类智能已经到头了。

左脚踩右脚上天,难道真的被这帮人给搞出来了?

这是一篇来自被解散的超级对齐团队的“遗作”,由前负责人Jan Leike带队。
而Leike本人已经跳槽去了隔壁Anthropic,继续做这类研究。

基于GPT-4,改进GPT-4
OpenAI官网文章变相承认了,GPT-4之后这么久没有大的改进,还真的遇到一些瓶颈:
随着AI能力变强,它犯的错也不那么显眼了,人类训练师都难以发现不准确之处。
人类给不出反馈,那RLHF“人类反馈强化学习”就无从谈起了。

CriticGPT正是为了应对这一挑战而生。
CriticGPT基于GPT-4,也接受了RLHF训练出,但特别之处在于训练数据中包含大量的错误输入。
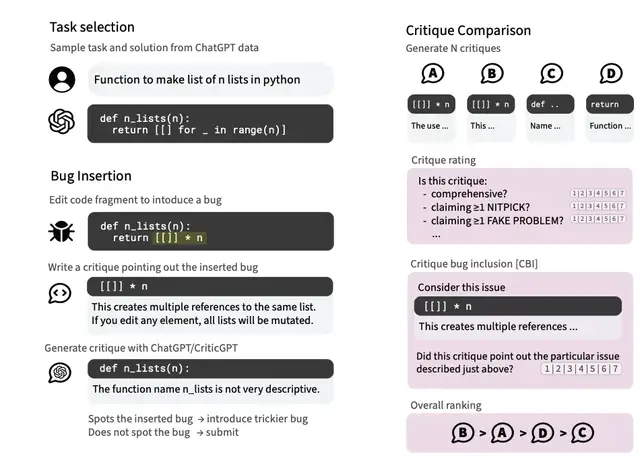
具体来说,分为三步:
- 让人类标注员在ChatGPT生成的代码里故意植入一些微妙的bug。
- 标注员扮演代码审查员的角色,写下他们对这些bug的评论。
- 用这些数据来训练CriticGPT,让它学会如何发现和指出代码中的问题。
在具体训练过程中,他们还玩了点花样。
比如不断让标注员验证自己插入的bug是否足够隐蔽,能够骗过当前版本的CriticGPT。这样一来,CriticGPT就被迫不断进化,学会发现越来越隐蔽的问题。
思路有点像GAN的左右互搏,只不过生成器这个位置是人类来充当的……
最后,OpenAI还使用了一种“强制采样束搜索”(FSBS)的技术,允许CriticGPT在生成评论时既能保持全面,又能减少”幻觉”和“鸡蛋里挑骨头”现象。
具体来说,FSBS会强制模型生成多个不同的评论片段,用奖励模型对这些片段进行评分,最后根据评分和一个长度修正因子来选择最佳的评论组合。
通过调整长度修正因子,可以在评论的全面性和准确性之间找到最佳平衡点,既不会错过重要问题,又不会过度挑剔。

等一下,推理时搜索,这不正是和传闻中的Q*一个思路,这次居然写到了论文里。
可能是看外部团队(如颜水成)按这一思路的研究已经够多了,就不再藏着掖着了。

说回到CriticGPT,取得了哪些结果呢?
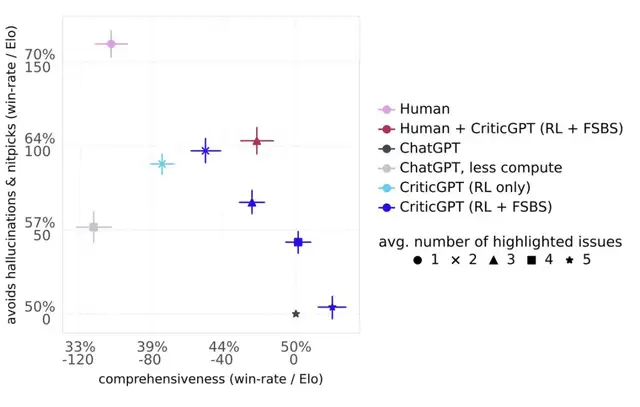
- 在发现人为插入的bug方面,人类审核员平均只能找到25%,而CriticGPT的成功率高达75%以上
- 在评估自然出现的Bug时,有63%的情况下人类更倾向于选择CriticGPT的评论而非人类评论
- CriticGPT的评论被认为比ChatGPT的更全面,更少出现”幻觉”和无关紧要的挑剔
- 在评估非代码任务时,成功识别出数百个在ChatGPT训练数据中被人类认为是”完美”的错误。
不过CriticGPT也不是十全十美,它也会有”幻觉”问题,指出一些实际上不存在的问题。
目前,人类和CriticGPT组队工作效果最好:既能发现大部分问题,又能避免AI的”幻觉”。
RLHF上限不再是人类
对于CriticGPT,负责这项研究的Jan Leike也补充了他自己的一些看法。
RLHF是创造出ChatGPT的核心技术之一,但隐患在于人类能力就是RLHF的天花板。
当需要AI去解决人类无能为力的任务时,人类给不出相应反馈,AI也就无法改进了。
CriticGPT的成功,意味着超级对齐团队设想中的可扩展监督,也就是用弱模型监督训练更强的模型,终于有希望了。
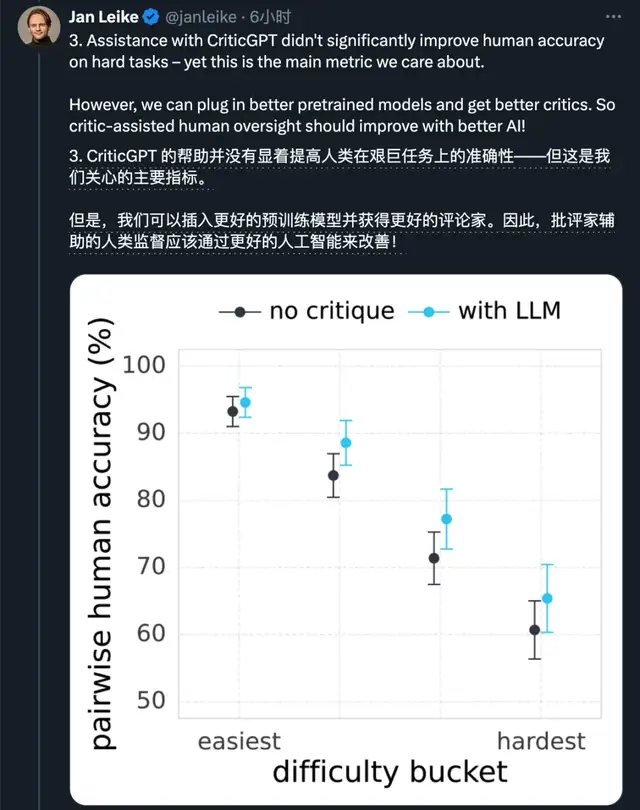
不过他也透露,目前CriticGPT并没有帮助人类显著提高艰难任务上的准确性,但是框架有了只要有更好的预训练模型就能不断改进。
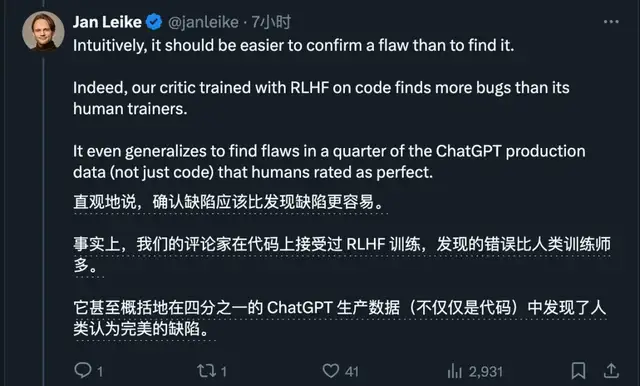
为什么先从代码任务开始入手呢?
一方面,代码任务有现实意义,做出来的模型可以直接用上。
另一方面,代码可以清晰明确的评估,比开放式对话更客观,更容易评估CriticGPT发现的问题是否真实和重要。
结果CriticGPT在代码上训练,却不仅能挑代码Bug,还给1/4的ChatGPT生产数据挑出了问题。
最后,由于原OpenAI超级对齐团队已经解散,已经跳槽的Jan Leike插入了一条Anthropic招聘广告:
想做后续研究的请去隔壁。
也是让人不得不感叹硅谷是真的没有竞业协议。
One More Thing
同日,谷歌发布了开源大模型Gemma 2,OpenAI赶紧甩出一条消息来狙击,这都第几次了。

对于甩出来的不是Sora公测或者GPT-4o完整语音、视频模式,也有很多人不满。
有网友提了个更好的主意:
做个ReleaseGPT,专门用来发布承诺好的更新吧。
不过这次OpenAI久违的放出了论文,也还算有一些诚意。
论文地址:
https://cdn.openai.com/llm-critics-help-catch-llm-bugs-paper.pdf
参考链接:
[1]https://openai.com/index/finding-gpt4s-mistakes-with-gpt-4/
[2]https://x.com/janleike/status/1806386442568142995
- 王炸!谁能想到年底杀出的黑马是美图啊2024-11-22
- 汽车上的《Her》:模型竟然想做个人了,甩掉机械感,来自吉利2024-11-22
- 史上最严中文真实性评估:OpenAI o1第1豆包第2,其它全部不及格2024-11-21
- 智能交互创新赛落幕,哈工大AI智能背诵助手拿下特等奖|OPPO智能体平台2024-11-19
相关阅读










