百万级高质量视频数据集发布,登顶抱抱脸数据集排行榜,中科大&上海AI Lab等出品
高质量描述,让视频生成质量更好
ShareGPT4V团队 投稿
量子位 | 公众号 QbitAI
中科大、上海AI实验室等组成的ShareGPT4V团队,推出了新的视频数据集,登顶HuggingFace排行榜!
数据集涵盖了3000小时的高质量视频数据,而且还配有高质量的文字描述。
利用这一数据集,团队重新测试了北大的Open-Sora-Plan,发现视频生成质量获得了显著提升。

作者认为,无论是视频理解还是视频生成任务,都离不开详细高质量的视频-字幕数据。
利用GPT-4v的视觉能力,团队得到了4万条(共291小时)带有标注的视频数据,生成的描述包含了丰富的世界知识。
在此基础之上,团队得到了能自动生成视频描述的模型,从而将数据规模拓展到了480万条、近3000小时。

目前该项目已开源,论文登上了6月7日的抱抱脸Daily Papers榜首,同时数据集本身也成功登顶VQA类数据集榜单。
为视频生成高质量描述
视频多模态领域中,闭源商业模型一直处于断层领先的地位,而研究者们认为,这种领先优势,离不开详细高质量的视频-字幕数据。
因此,该研究团队致力于为视频获取大量详细而精确的字幕,提升大型视频语言模型的视频理解能力和文生视频模型的视频生成能力。
经过分析,研究者们认为,用现有的闭源模型生成高质量视频描述的挑战有三个方面——
- 一是清晰地理解帧间的时序变化;
- 二是详细准确地描述帧内内容;
- 另外,对任意长度视频的可扩展性也是一大难点。
为此,研究者们精心设计了一种描述策略。
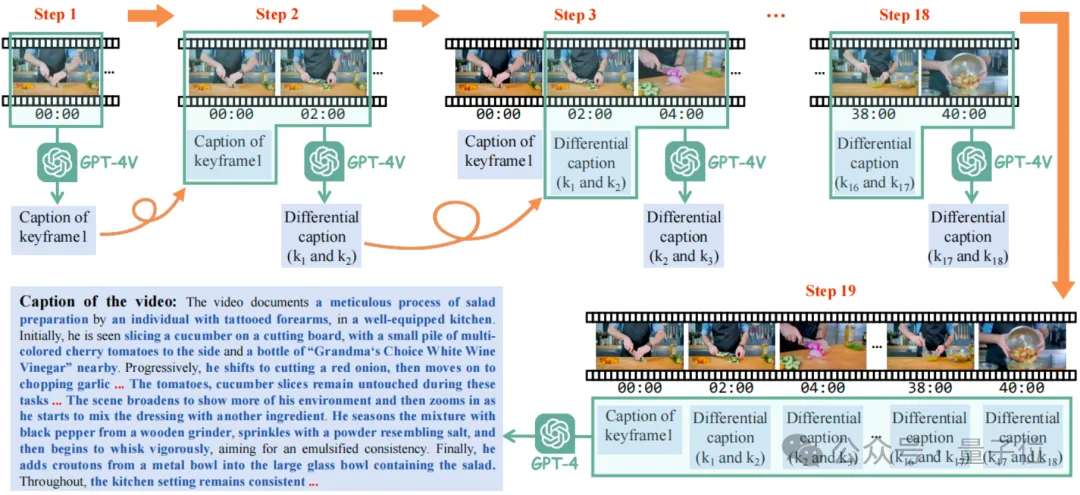
这种策略叫做差分滑窗视频描述(Differential Sliding-Window Captioning, DiffSW),可以稳定且高效地为任意分辨率、宽高比和长度的视频生成高质量描述。
具体而言,研究者们每次送入GPT-4V的输入是当前关键帧、上一关键帧,以及上一关键帧对应的差分描述。
这样做的目的是让GPT-4V通过观察两帧之间的时间与空间变化,总结出当前帧相对于上一帧的重要空间、时序变化,也就是当前帧与上一帧对应的差分描述。
最终,所有差分描述会连同时间戳一起送入GPT4中,从而总结出最终的关于整个视频的高质量字幕。
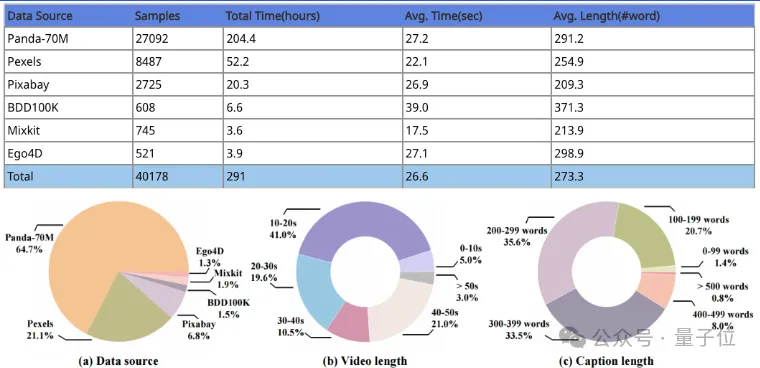
通过这一方法,研究者们推出了大型“视频-文本描述”数据集——ShareGPT4Video数据集,其中包括4万条(共291小时)由GPT-4V标注的视频数据。
这些数据涵盖了广泛的类别,生成的描述包含丰富的世界知识、对象属性、摄像机运动,以及详细和精确的事件时间描述。
描述文本的字数主要在200-400之间,提供了丰富的时间信息,可以很好地完成视频理解和生成任务。
为了进一步扩大数据集规模,以及便于开源社区在自有数据上的使用,在ShareGPT4Video数据集的基础上,研究者们进一步设计开发了ShareCaptioner-Video,一个能够有效地为任意视频生成高质量描述的多功能多模态大模型。
ShareCaptioner-Video是一款四合一的特殊视频描述模型,具有滑动窗口生成视频描述、快速生成视频描述、视频片段对应描述整合,以及提示词生成详细描述四种功能。
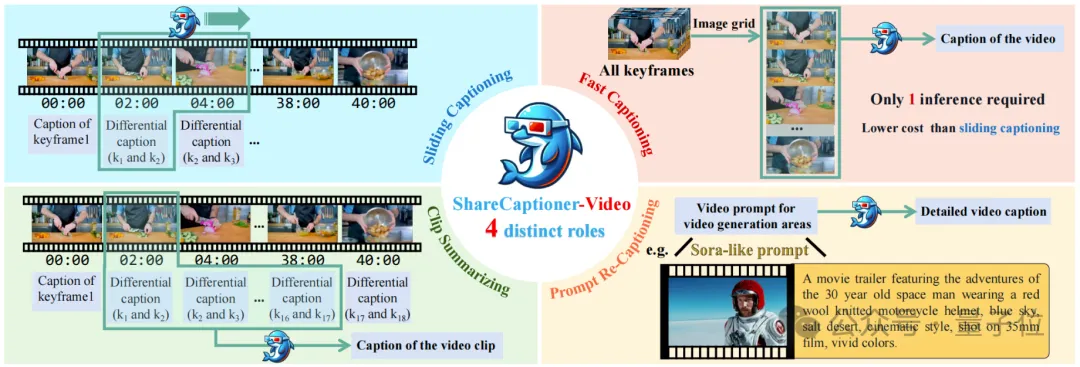
具体而言,滑窗视频描述功能可以担任GPT-4V收集标注数据中的全部角色,并且通过滑窗的方式来产生差分描述并汇总出最终的字幕。
快速视频描述功能则是把所有关键帧沿竖直方向拼成一张长图一次性产生最终的字幕,在略微牺牲性能的情况下大幅提升标注速度。
视频片段总结功能则可以在对完整视频进行一次滑窗描述后,对其中任意的视频片段直接总结出字幕而不需要再次进行滑窗描述过程。
在得到了优异的视频描述模型后,研究者们用它进一步标注了480万条,总时长3000小时的丰富的视频数据。
这些视频具有较高的美学评分以及较少的转场效果,可以进一步为视频生成任务服务,其具体构成如下:

让视频理解和视频生成模型更好
在视频理解方面,研究者们首先通过简单的等量替换实验,验证了ShareGPT4Video数据集在几种当前LVLM架构上的有效性。
研究者们把VideoChatGPT数据集中的100K视频训练数据中的与详细caption相关的28K数据,等量替换成了ShareGPT4Video数据集中的子集。
结果立竿见影,从下表可以看到,通过简单的数据替换,仅仅是字幕数据质量上的提升,便可以一致地为不同架构、不同规模的视频理解多模态大模型带来显著的性能增益。
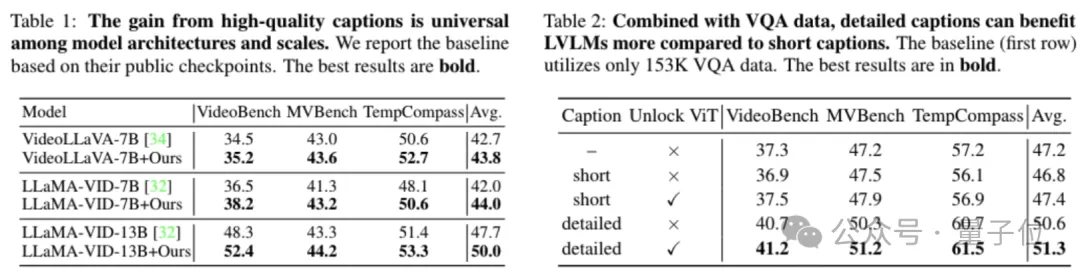
之后,研究者们自主收集了153K的视频VQA数据,并结合ShareGPT4Video数据集中与视频理解相关的28K高质量字幕数据,提出了新的LVLM ShareGPT4Video-8B。
仅需8卡以及5个小时的训练开销,该模型就能在多项Benchmark上取得优异的结果。
下图中,从上到下依次为TempCompass、 VideoBench和MVBench上的性能对比。
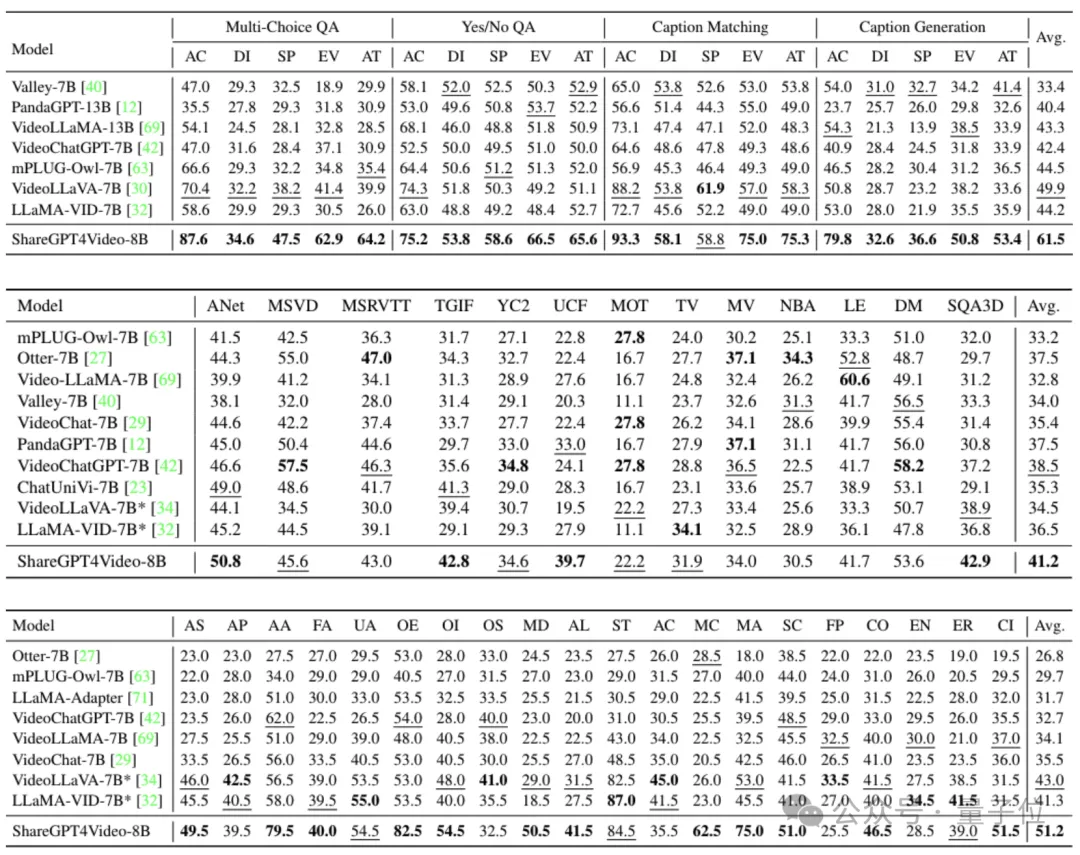
即使是在最近新出现的几个视频理解基准上,ShareGPT4Video-8B也可以在7B参数规模上一致地展现出具有竞争力的性能。
下图从左到右依次展示了LongVideoBench、Video-MME与MMBench-Video数据集上的性能对比。

在视频生成方面,研究者们基于Open-Sora-Plan项目简单直接地验证了详细的字幕数据对于文生视频模型的帮助。
下图中,第一行的结果是使用了短字幕数据训练出的文生视频模型得到的,第二行的结果是使用了ShareCaptioner-Video标注的高质量字幕数据训练出的文生视频模型得到的。
可以看到,使用详细的字幕数据,可以让文生视频模型具备优异的镜头移动控制以及语义内容控制能力。

论文地址:
https://arxiv.org/abs/2406.04325v1
项目主页:
https://ShareGPT4Video.github.io/
GitHub:
https://github.com/ShareGPT4Omni/ShareGPT4Video
- 1450亿!马斯克xAI与X合并后再寻资金,将成史上第二大初创企业单轮融资2025-04-27
- 挤爆字节服务器的Agent到底啥水平?一手实测来了2025-04-23
- 电视装了智能体,只凭台词就能找到剧集了2025-04-24
- 无需数据标注!测试时强化学习,模型数学能力暴增 | 清华&上海AI Lab2025-04-24