黑马!大模型竞技场榜单更新,国产玩家首次进入全球总榜前10
团队GPU可能只有Google、Microsoft的5%
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
龙争虎斗的大模型竞技场,今天突然更新:
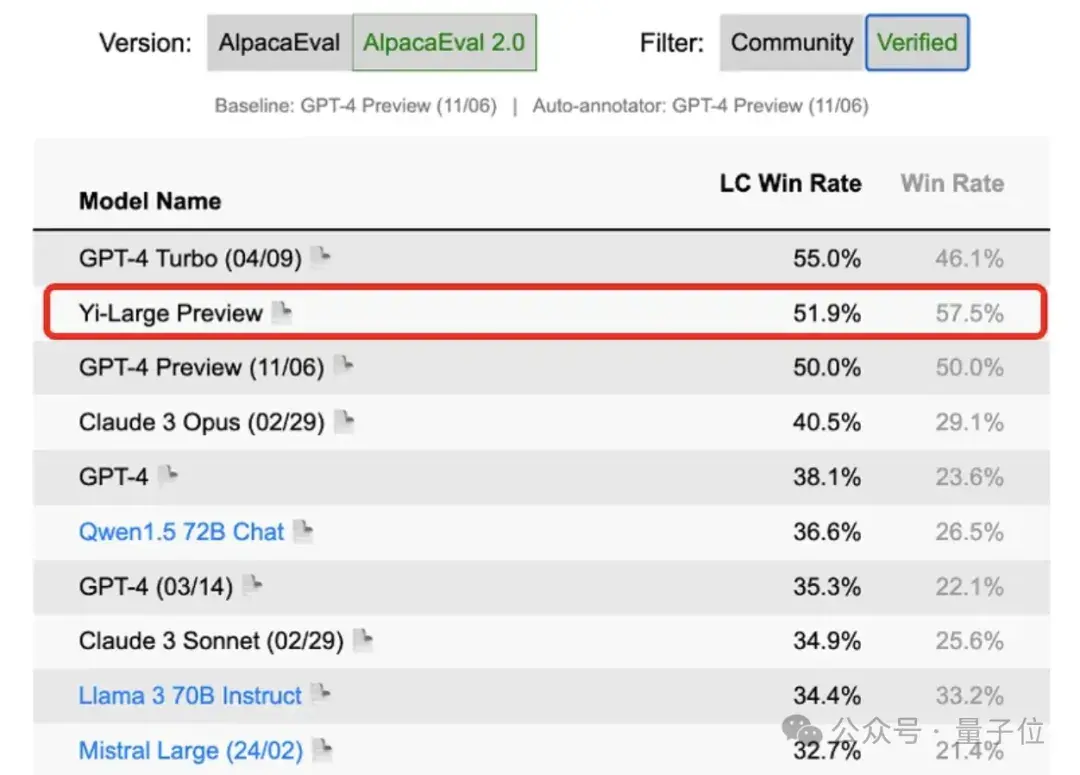
国内大模型公司零一万物旗下的Yi-Large千亿参数闭源大模型,跃升总榜第七,也成为榜上国产大模型第一。
可以看到,它的成绩几乎与GPT-4-0125-preview持平。
同时,国内清华系大模型公司智谱华章的GLM-4-0116也杀进总榜,位居第15位。
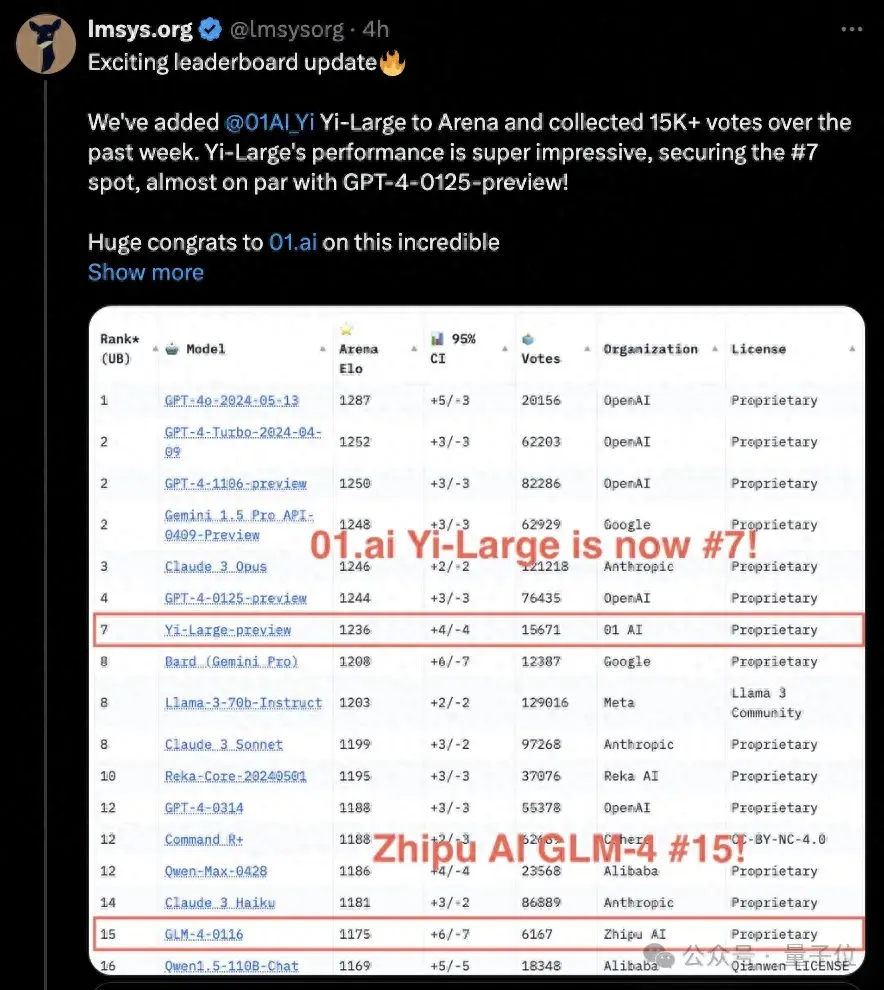
这个结果来自累积超1170万全球用户的真实盲测投票数。
而且大模型竞技场最近修改了规则,只要大模型亮明身份后就不能再继续投票,杜绝了刷分的可能性。
再来看Yi-Large排名之前的前6名中,有4个模型来自GPT,另外有1个谷歌的Gemini,1个Anthropic的Claude。
零一万物创始人兼CEO李开复博士为此表示,LMSYS提供了一个第三方的、公正的平台,其他竞争对手也都非常认可。
而零一万物的团队规模、参数规模、GPU算力都比排名更靠前的模型“小”。
零一万物的GPU可能只有Google、Microsoft的5%,但团队一直在探索,能不能训练跟大厂一样好的模型。
我们的特点就是以千亿模型杀入了万亿模型的范围。如果我们有10倍的GPU,我们的万亿模型应该完全可能达到第一名。
Yi-Large成排名飞升黑马
大模型竞技场官推还给出了Yi-Large的更多成绩:
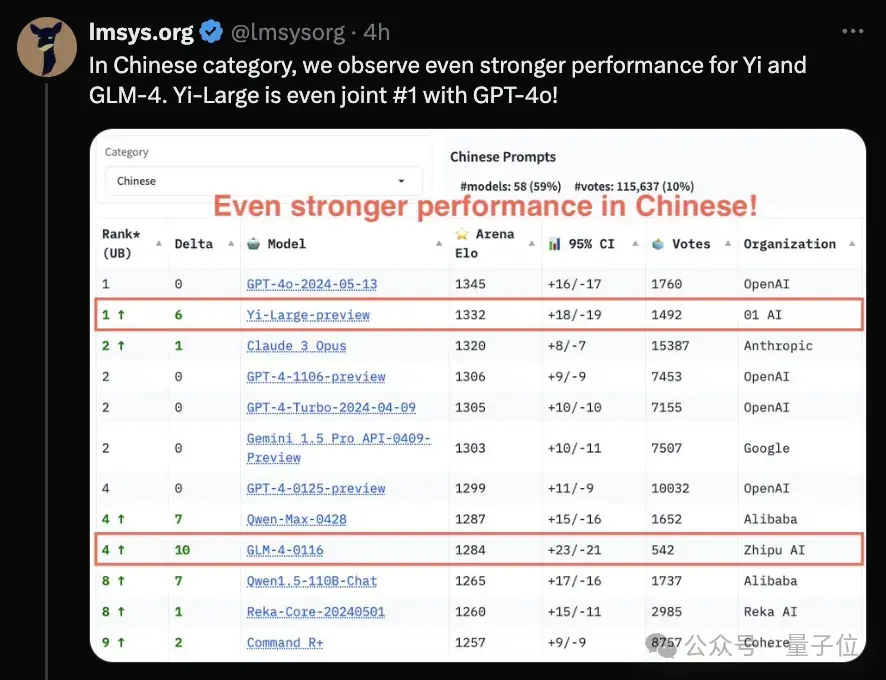
在中文类别中,Yi-Large和GLM-4两个国产大模型的表现不俗。
其中,Yi-Large成绩尤为突出,与GPT-4o并列总榜第一。
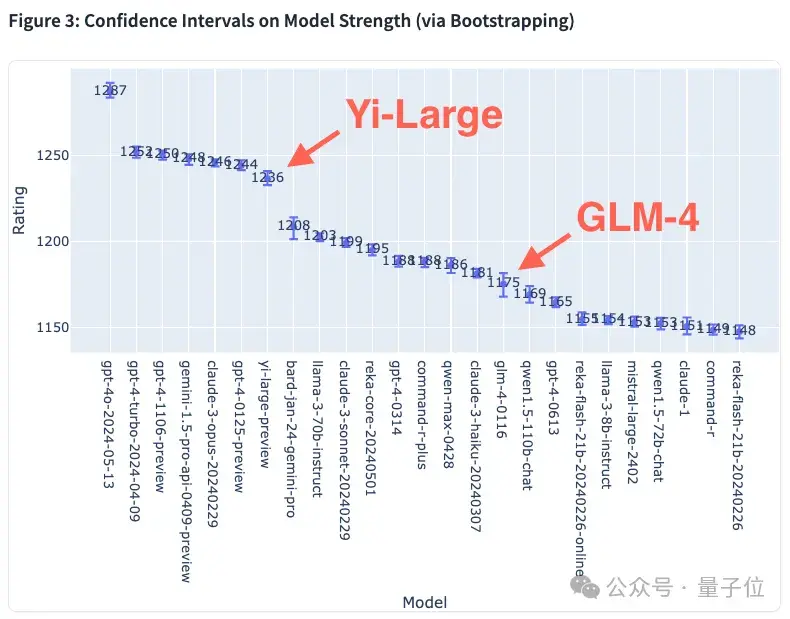
模型强度的置信区间,则如下图所示:
值得注意的是,为了提高大模型竞技场查询的整体质量,LMSYS还实施了重复数据删除机制,并出具了去除冗余查询后的榜单。
这个新机制旨在消除过度冗余的用户提示——如过度重复的“你好”——这类冗余提示可能会影响排行榜的准确性。
LMSYS公开表示,去除冗余查询后的榜单将在后续成为默认总榜。
目前,在去除冗余查询后的总榜中,Yi-Large的Elo得分更进一步,与Claude 3 Opus、GPT-4-0125-preview并列第四。
解释一下,Elo评分系统基于统计学原理设定,是当前国际公认的竞技水平评估标准。在这个评分系统里,每个参赛者都有基准评分,然后根据每场比赛调整评分。一旦低分选手击败高分选手,那么低分选手就会获得较多的分数,反之则较少。
LMSYS引入Elo评分系统,是为了保证大模型竞技场在最大程度上保证排名的客观公正。
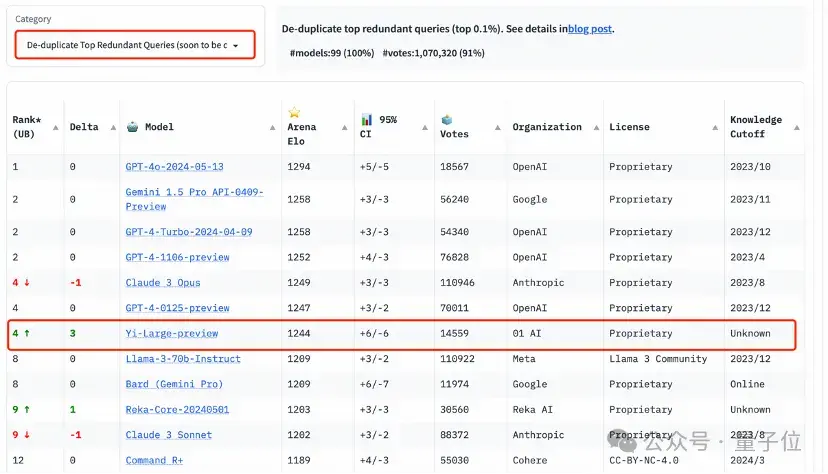
而在分类别的排行榜中,Yi-Large同样表现亮眼。
编程能力、长提问及最新推出的 “艰难提示词” 的三个评测是LMSYS所给出的针对性榜单。这三个榜单以专业性与高难度著称,可称为当下大模型最烧脑的公开盲测。
在编程能力(Coding)排行榜上,Yi-Large 的Elo分数超过Anthropic当家旗舰模型Claude 3 Opus,仅低于GPT-4o,与GPT-4-Turbo、GPT-4并列第二。
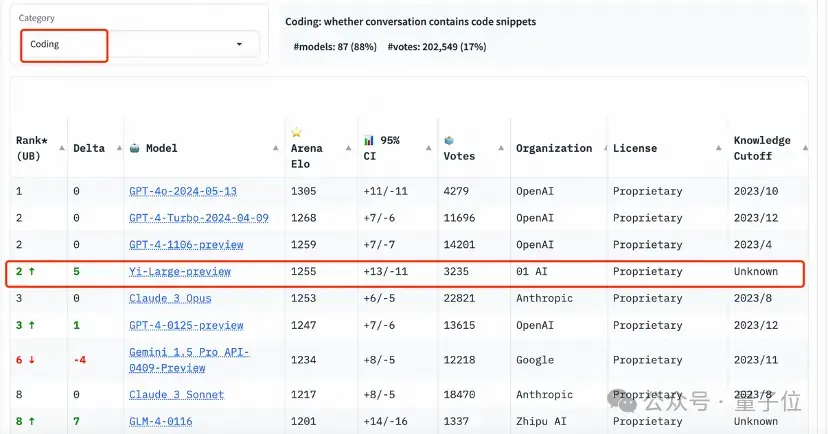
在长提问(Longer Query)榜单上,Yi-Large同样位列全球第二,与GPT-4-Turbo、GPT-4、Claude 3 Opus并列。
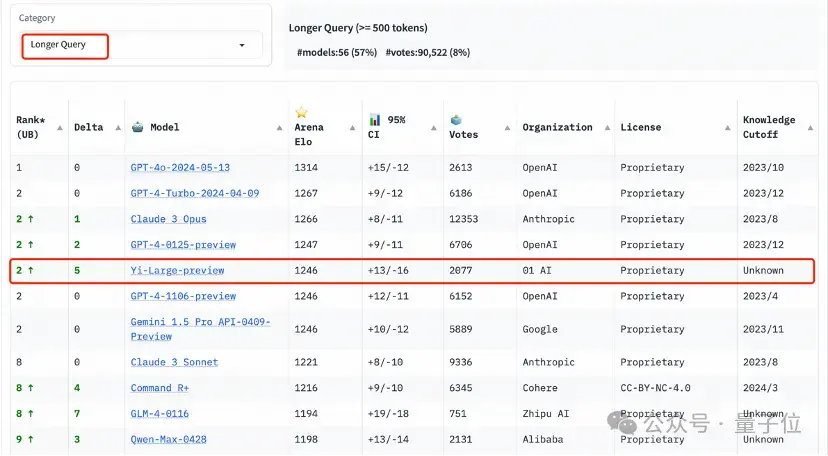
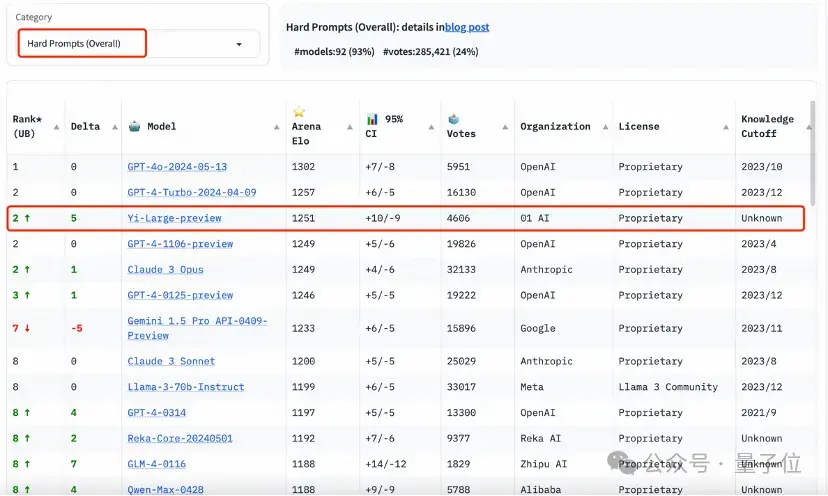
艰难提示词(Hard Prompts)则是LMSYS响应社区要求,在今天的排行榜刷新中新增的类别。
这个类别的提示词来自大模型竞技场用户提交的prompts,它们经过专门设计,更加复杂、要求更高且更加严格。
LMSYS增加这一类别榜单的原因,是官方认为这类提示能够测试最新语言模型面临挑战性任务时的性能。
这个榜单上,Yi-Large处理艰难提示的能力与GPT-4-Turbo、GPT-4、Claude 3 Opus并列第二。
这次表现亮眼的Yi-Large,是一周前零一万物刚对外发布的闭源模型。
当时官方给出的评测结果中,推理方面,Yi-Large在HumanEval和MATH都位列第一,超越GPT-4、Claude3 Sonnet、Gemini 1.5 Pro以及LLaMA3-70B-Instruct(都是时下大模型领域的佼佼者)。
据了解,Yi-Large的下一步是采用MoE架构的Yi-XLarge,目前已经启动训练。
大模型竞技场
大模型竞技场(Chatbot Arena),似乎已经成为现在头部大模型的兵家必争之地。
此前,国外如谷歌Bard、OpenAI的神秘大模型gpt2-chatbot(不是GPT-2)、Mistral AI的Mistral Large等模型都在上面冲锋陷阵。
国内诸多玩家也都陆陆续续把自家孩子放进去考验真功夫。
大神卡帕西去年就夸过大模型竞技场很Awesome:
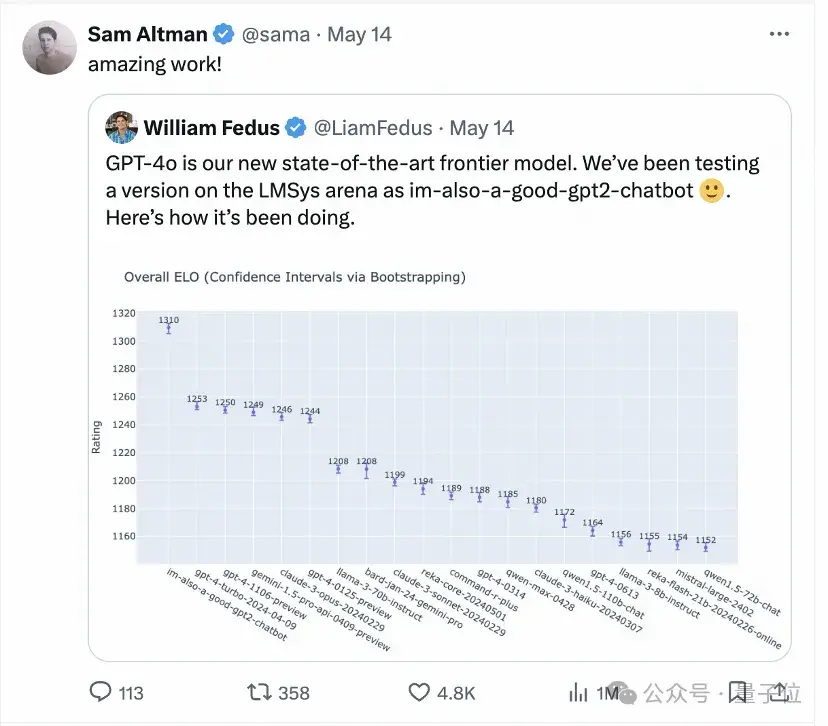
GPT-4o发布后,OpenAI的CEO奥特曼也转帖引用大模型竞技场盲测擂台的测试结果,直呼鹅妹子嘤。
发布它的开放研究组织LMSYS Org(Large Model Systems Organization)发布,由加州大学伯克利分校的学生和教师、加州大学圣地亚哥分校、卡耐基梅隆大学合作创立。
虽然背后团队主要来自高校,但LMSYS的研究项目却相对更贴近产业。
他们不仅自己开发大语言模型,还向业内输出多种数据集(其推出的MT-Bench已是指令遵循方向的权威评测集)、评估工具,此外还开发分布式系统以加速大模型训练和推理,提供线上live大模型打擂台测试所需的算力。

在形式上,大模型竞技场借鉴了搜索引擎时代的横向对比评测思路。
它首先将所有上传评测的参赛模型随机两两配对,以匿名模型的形式呈现在用户面前。
在不知道模型型号名称的前提下,用户输入自己的提示词,模型A、模型B两侧分别生成两PK模型的真实结果,然后由用户在结果下方做出投票四选一:
A模型较佳/B模型较佳/两者平手/两者都不好。
提交投票后,可进行下一轮PK。
目前,大模型竞技场的评测过程涵盖了从用户直接参与投票、盲测、大规模投票和动态更新评分机制等多个方面,尽可能保证结果的客观和专业。
官方公开数据显示,本次更新的大模型竞技场,共有44款模型参赛。
既有开源高手,如Llama3-70B;也有全球各家大厂、创业公司的闭源模型。
最后,奉上一张胜率热图,它涵盖了目前大模型竞技场上的所有大模型:
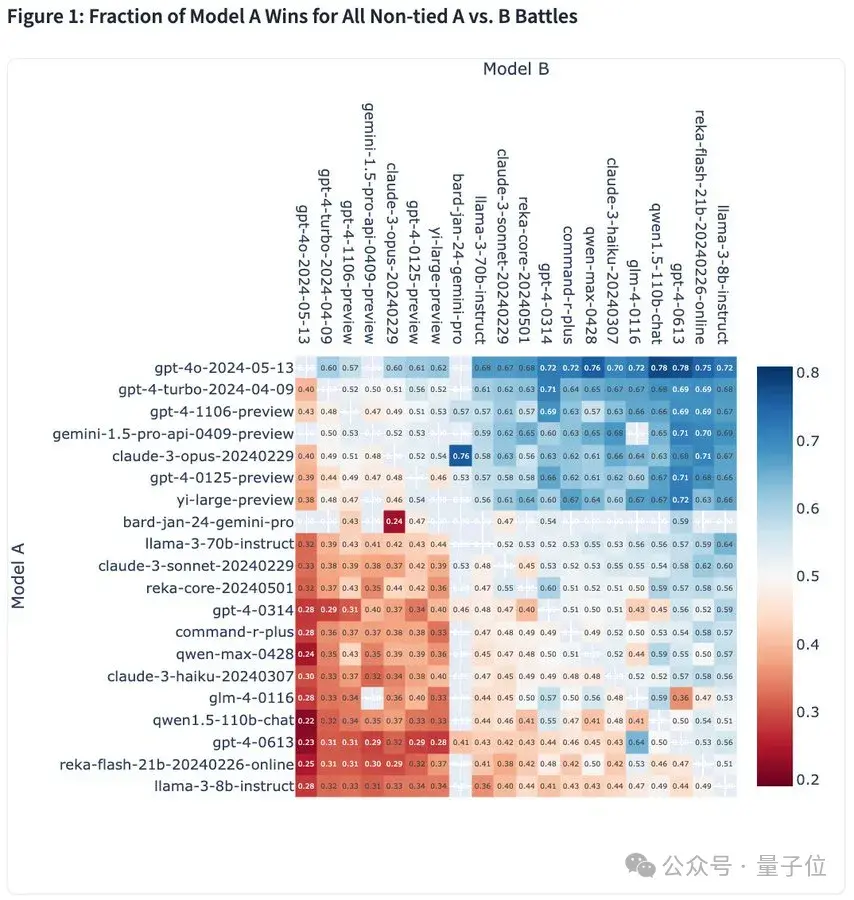
快来看看你pick的大模型胜率如何吧(手动狗头)~
大模型竞技场盲测平台:
https://arena.lmsys.org/
大模型竞技场评测排行(滚动更新):
https://chat.lmsys.org/?leaderboard
- 推理大模型1年内就会撞墙,性能无法再扩展几个数量级 | FrontierMath团队最新研究2025-05-13
- 黄仁勋放话:中国AI市场3年内达500亿美元!AI救了旧金山,整个世界急于与AI互动2025-05-07
- 突发!曝阿里通义薄列峰离职,此前为应用视觉团队负责人2025-05-06
- o3一张图锁定地球表面坐标,AI看图猜地点战胜人类大师,奥特曼:这是我的「直升机」时刻2025-05-05