
一次预测多个token,Meta新模型推理加速3倍,编程任务提高17%
若无远虑必有近忧?
梦晨 西风 发自 凹非寺
量子位 | 公众号 QbitAI
“预测下一个token”被认为是大模型的基本范式,一次预测多个tokens又会怎样?
Meta AI法国团队推出“基于多token预测的更快&更好大模型”。

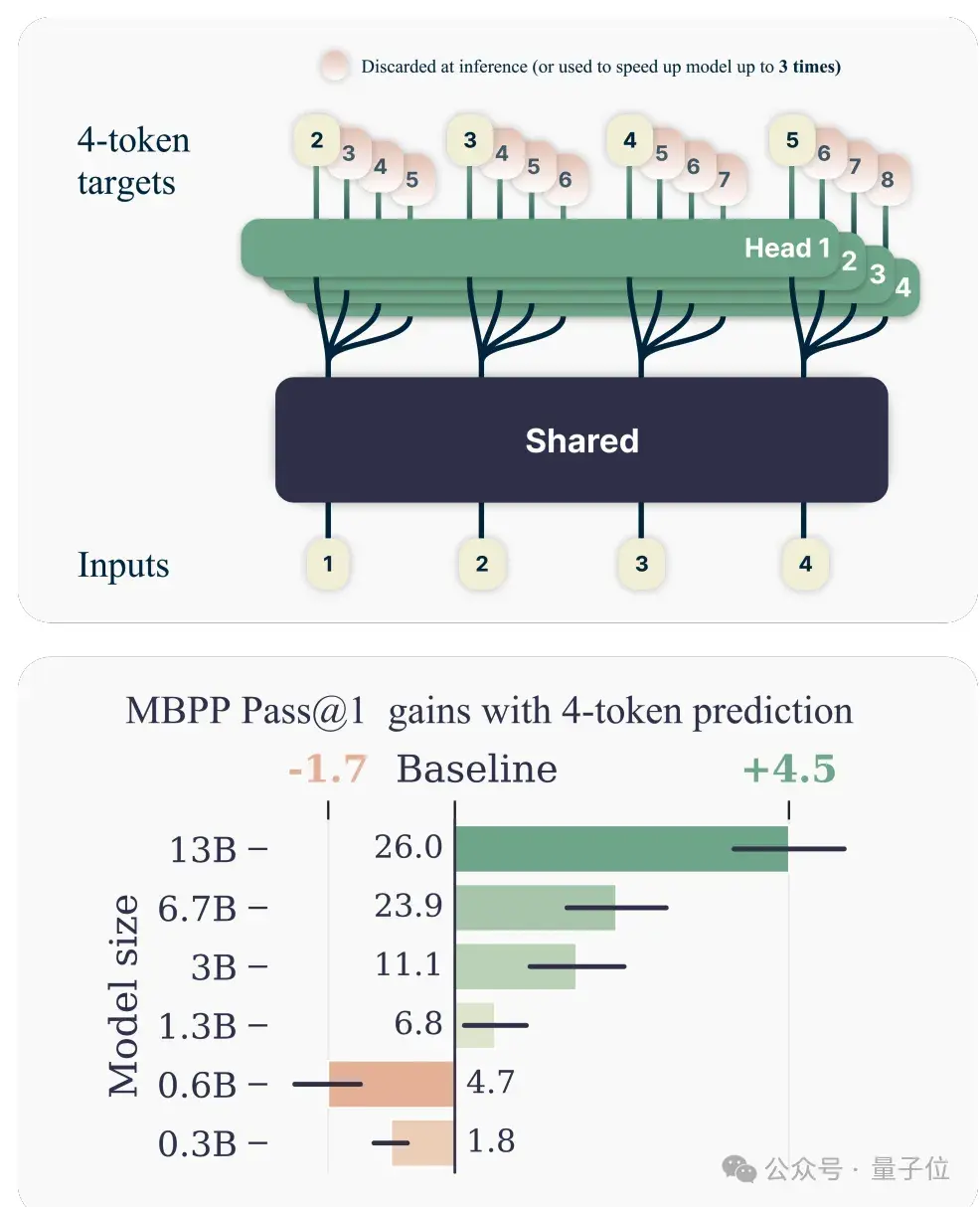
多token预测模型,在编程类任务上表现尤其突出。
与单token预测相比,13B参数模型在HumanEval上多解决了12%的问题,在MBPP上多解决了17%。
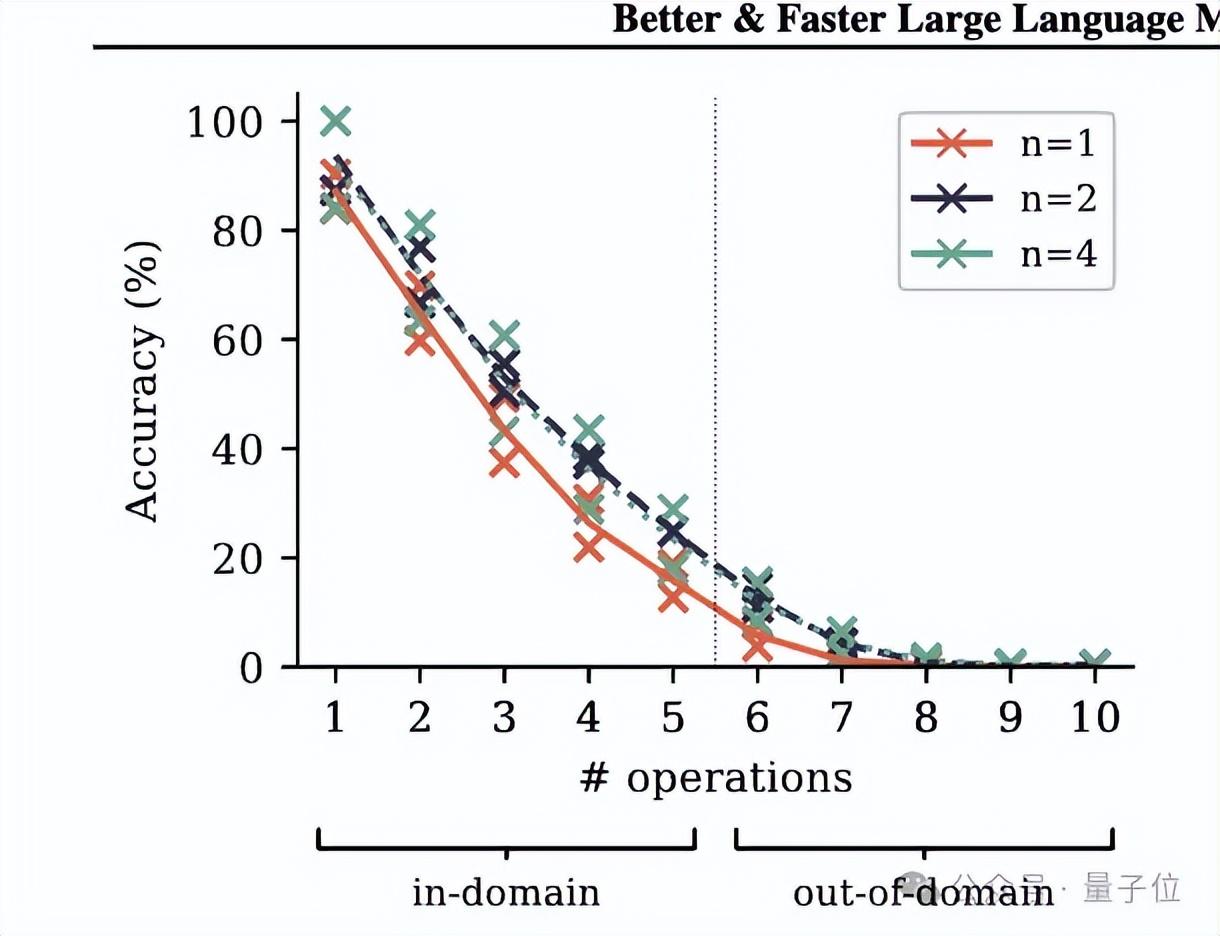
小型算法推理任务上,多token预测也在分布外泛化方面带来了令人印象深刻的收益。
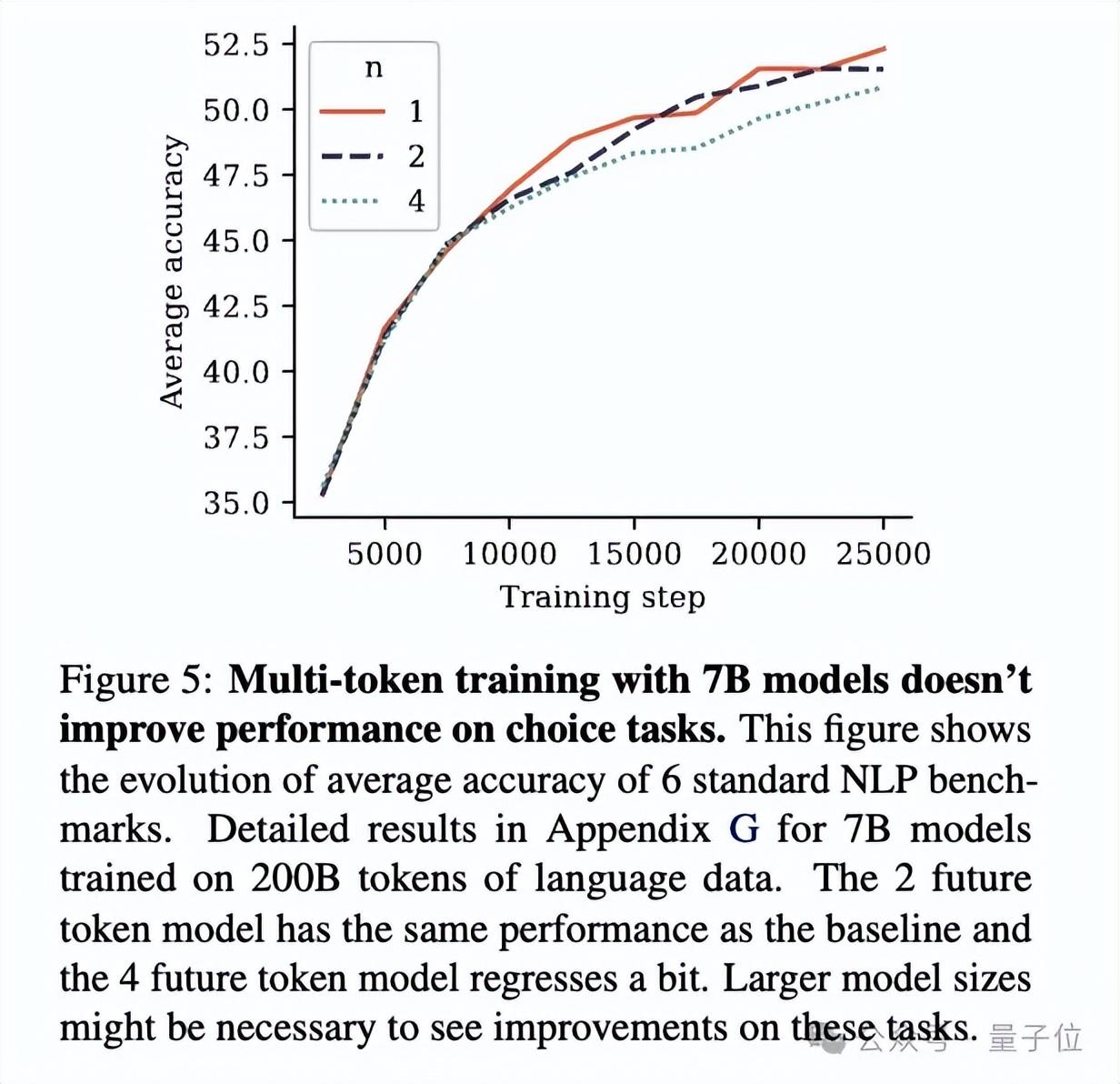
不过在自然语言任务上,多token预测方法并不能显著提高7B模型在数学选择题上的表现了。
另外一个好处是,即使batch size较大,使用4-token预测训练的模型,推理速度也可提高3倍。
多token预测更适合编程
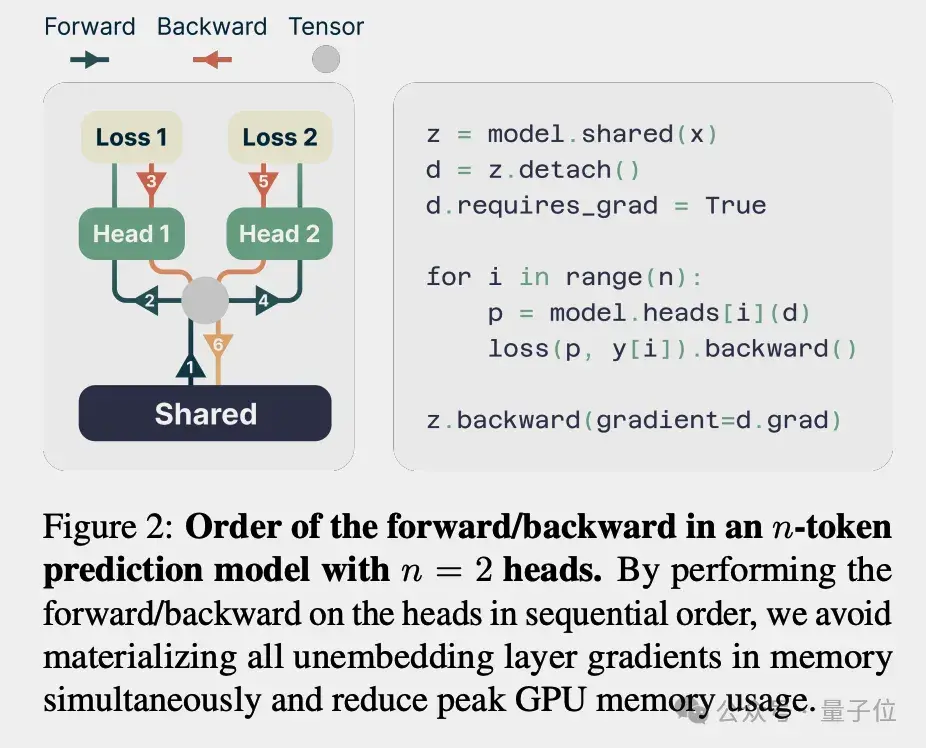
具体来说,团队设计了一种新的多token预测架构,通过n个独立的输出头并行预测n个未来token。
使用大量文本数据进行模型训练,包括代码和自然语言数据集。
再通过实验比较多token预测和单token预测在多个下游任务上的性能。
为啥多token预测在编程任务和小型算法推理任务上提升更明显?
团队猜测可能有两个原因:
第一,编程语言的逻辑结构更严谨,知识的内在联系更紧密。一个关键节点可能影响到后续整个代码块的走向。多Token预测能更好捕捉这种长距离依赖。
第二,相比自然语言,编程语言的词汇量更小。因此即便每次预测多个Token,难度也没那么大。反而能迫使模型从局部细节中抽身,着眼全局优化。
除了在token层面的实验,团队还在更细粒度的字节级模型上做了尝试。
他们发现,用8字节预测替代下一个字节预测后,模型在MBPP上的Pass@1指标暴增67%,在HumanEval上也提升了20%。
而且推理速度还能再快6倍,简直不要太香。

对于背后原理,团队认为多token预测缓解了训练时Teacher Forcing和推理时自回归生成之间的分布差异。
也就是说,在训练的时候,模型看到的都是标准答案,生成的时候却得靠自己。好比人类在家做练习册时有答案,考试时却啥也没有,就会不适应。
而多token预测相当于训练时就逼着模型多想几步,这样到了考场上,才能应对自如。
从信息论的角度,团队还给出了一个更精确的论证。
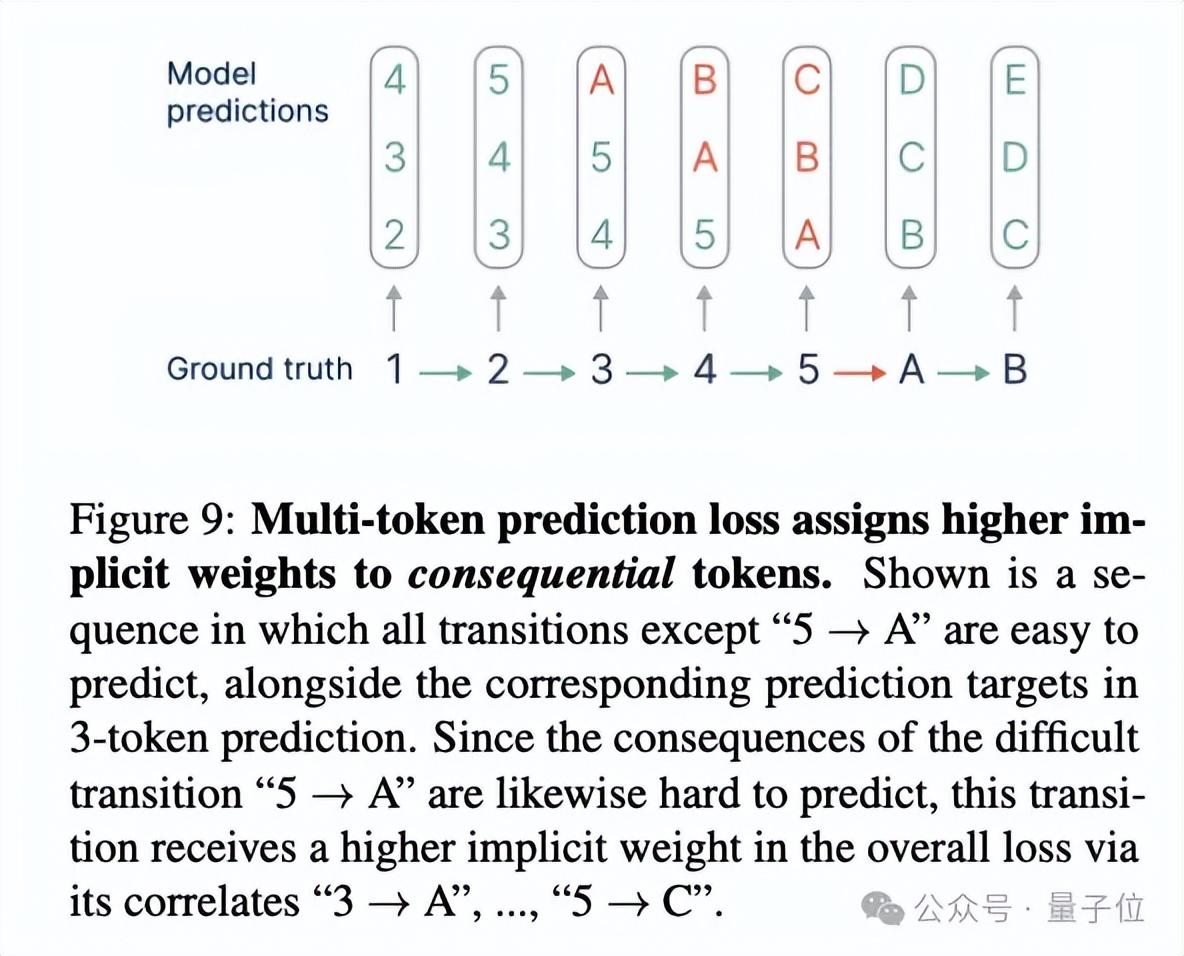
传统的下一个Token预测,目标是最小化当前位置的信息熵。而2-Token预测实际上最小化的是当前和下一位置的信息熵之和。
数学推导表明,后者其实隐含了更大的互信息权重,也就是更看重当前Token和未来Token的相关性。这就是为什么多Token预测更”有远见”。
不过在这篇论文中,还有几个未解决的问题。
比如没有探讨如何自动选择最佳的预测token数量n,作者提出,未来可以研究使用损失权重调整或动态调整n来解决最佳n的选择问题。
此外最佳的词表大小也可能与单token预测时不同。
总之,看过这篇论文之后,大家都更期待Llama-4了。

论文地址:
https://arxiv.org/abs/2404.19737
- 手机实现GPT级智能,比MoE更极致的稀疏技术:省内存效果不减|对话面壁&清华肖朝军2025-04-12
- 7B小模型写好学术论文,新框架告别AI引用幻觉,实测100%学生认可引用质量2025-04-11
- 字节新推理模型逆袭DeepSeek,200B参数战胜671B,豆包史诗级加强?2025-04-11
- Llama 4发布36小时差评如潮!匿名员工爆料拒绝署名技术报告2025-04-07





