完胜BERT!谷歌NLP预训练利器:小模型也有高精度,单个GPU就能训练 | 代码开源
十三 发自 凹非寺
量子位 报道 | 公众号 QbitAI
这款NLP预训练模型,你值得拥有。
它叫ELECTRA,来自谷歌AI,不仅拥有BERT的优势,效率还比它高。
ELECTRA是一种新预训练方法,它能够高效地学习如何将收集来的句子进行准确分词,也就是我们通常说的token-replacement。
有多高效?
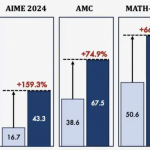
只需要RoBERTa和XLNet四分之一的计算量,就能在GLUE上达到它们的性能。并且在SQuAD上取得了性能新突破。
这就意味着“小规模,也有大作用”,在单个GPU上训练只需要4天的时间,精度还要比OpenAI的GPT模型要高。
ELECTRA已经作为TensorFlow的开源模型发布,包含了许多易于使用的预训练语言表示模型。
让预训练变得更快
现存的预训练模型主要分为两大类:语言模型 (Language Model,LM)和掩码语言模型 (Masked Language Model,MLM)。
例如GPT就是一种LM,它从左到右处理输入文本,根据给定的上下文预测下一个单词。
而像BERT、RoBERTa和ALBERT属于MLM,它们可以预测输入中被掩盖的少量单词。MLM具有双向的优势,它们可以“看到”要预测的token两侧的文本。
但MLM也有它的缺点:与预测每个输入token不同,这些模型只预测了一个很小的子集(被掩盖的15%),从而减少了从每个句子中获得的信息量。
而ELECTRA使用的是一种新的预训练任务,叫做replaced token detection (RTD)。
它像MLM一样训练一个双向模型,也像LM一样学习所有输入位置。
受生成对抗网络(GAN)的启发,ELECTRA通过训练模型来区分“真实”和“虚假”输入数据。
BERT破坏输入的方法是,使用“[MASK]”替换token,而这个方法通过使用不正确的(但有些可信的)伪token替换一些输入token。
例如下图中的“cooked”可以替换为“ate”。
首先使用一个生成器预测句中被mask掉的token,接下来使用预测的token替代句中的[MASK]标记,然后使用一个判别器区分句中的每个token是原始的还是替换后的。
在预训练后,将判别器用于下游任务。
完胜BERT,SQuAD 2.0表现最佳
将ELECTRA与其他最先进的NLP模型进行比较可以发现:
在相同的计算预算下,它比以前的方法有了很大的改进,在使用不到25%的计算量的情况下,性能与RoBERTa和XLNet相当。
为了进一步提高效率,研究人员还尝试了一个小型的ELECTRA模型,它可以4天内在单个GPU上进行训练。
虽然没有达到需要许多TPU来训练的大型模型的精度,但ELECTRA仍然表现得突出,甚至超过了GPT(只需要1/30的计算量)。
最后,为了看看是否能够大规模实施,研究人员使用了更多的计算量(大约与RoBERTa相同的数量,约T5的10%),来训练一个大型ELECTRA。
结果表明,在SQuAD 2.0测试集上效果达到了最佳。
不仅如此,在GLUE上也超过了超过了RoBERTa、XLNet和ALBERT。
代码已开源
其实,这项研究早在去年9月份的时候便已发表。但令人激动的是,就在近几日,代码终于开源了!
主要是ELECTRA进行预训练和对下游任务进行微调的代码。目前支持的任务包括文本分类、问题回答和序列标记。
开源代码支持在一个GPU上快速训练一个小型的ELECTRA模型。
ELECTRA模型目前只适用于英语,但研究人员也表示,希望将来能发布多种语言的预训练模型。
传送门
谷歌AI博客:
https://ai.googleblog.com/2020/03/more-efficient-nlp-model-pre-training.html
GitHub地址:
https://github.com/google-research/electra
论文地址:
https://openreview.net/pdf?id=r1xMH1BtvB
- 全球第一车企,集齐中美双版Waymo2025-04-30
- 14.9万元,满血流畅运行DeepSeek一体机抱回家!清华90后初创出品2025-04-29
- 全栈AI基础设施支撑,跑出全球首个开放使用视频生成DiT模型2025-04-28
- 亚马逊云计算Troy Cui:敦煌网飙升AppStore第二,企业如何应对激增流量是关键 | 中国AIGC产业峰会2025-04-27