混合专家系统里根本没专家?开源MoE模型论文引网友热议
实验发现专家分配与话题无关
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
红极一时的开源MoE模型Mixtral,论文终于新鲜出炉!
除了披露了更多技术细节,论文中还有一个结论引发了热烈讨论——
研究人员本想研究Mixtral是怎么根据话题分配专家的,结果发现专家的分配……和话题好像没什么关系。

而在大多数人的印象中,Mixtral里的8个专家,是分别负责处理不同领域的话题的……
论文的结论曝光后,不少网友开始认为“专家混合”这个说法,可能不那么贴切了:
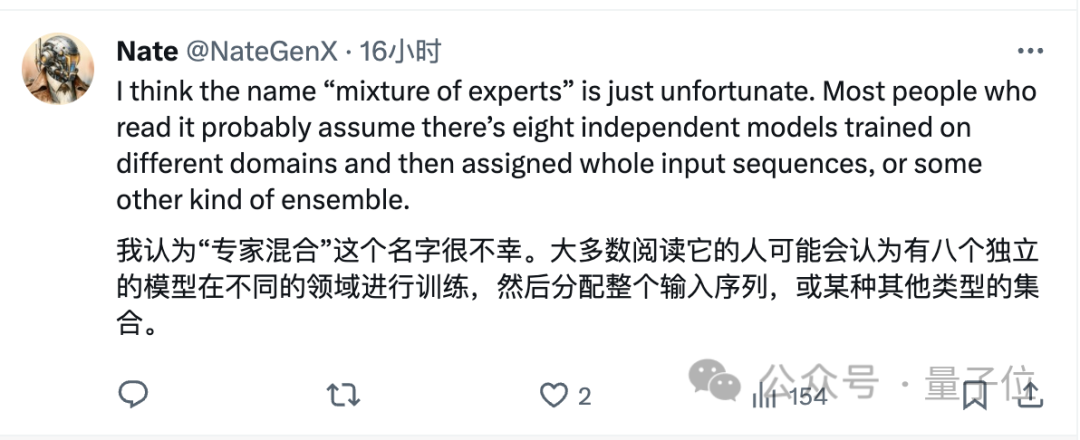
于是,针对Mixtral真实的工作机制,有网友给出了这样的比喻:
所以,比起“专家的组合”,这样的工作方式更像是一种硬盘阵列或者负载均衡?

但也有网友表示了不同意见:
这个问题并不根属于MoE,因为自己之前见过的MoE模型中,是发现了真·专家分工的现象的。

那么,这究竟是怎么一回事呢?
实验未发现专家按领域分布
在训练过程中,作者观察了Mixtral中是否有一些专家会针对某些特定领域进行专门化。
具体来说,作者计算了第0、15、31层在The Pile验证集的不同子集(包含不同领域的文档)上被选中的专家分布。
这些子集包括LaTeX格式的arXiv论文、生物学论文(PubMed摘要)、哲学论文(PhilPapers)和GitHub代码等。
结果发现,对这几个层而言,除了数学领域(DM Mathematics)数据集的专家选择略有不同外,其余数据集的专家分布都非常类似,并没有体现出领域间有什么差别。

而在数学问题上出现不同表现的原因,可能是由于其具有相对特殊的语法结构,进一步的探究也证实了这一想法。
他们发现,专家选择会被句子的语法结构所影响,一些语法关键词,比如英语中的“Question”或者代码中的“self”,被分配到相同的专家的概率非常大。

此外,定量的分析结果还发现了另一个专家分配规律——相邻的token有很大概率被分配给同一专家。
作者比较了模型针对相邻token选择相同专家的概率,包括第一选择一致率和第一二选择一致率。
第一二选择一致是指,模型针对两个token分别做出的第一和第二选择,只要存在交集即视为一致。
(比如第一个token的第一、二专家为分别为甲、乙,第二个token的第一、二专家分别为乙、丙,因为都包含了乙,就是一种第一二选择一致的情况)
因Mixtral中有8个专家,因此在全随机的选择方式下,第一选择一致率应为12.5%(1/8),第一二选择一致率应为1 – (6/8) × (5/7),约为46%。
但实际测试发现,Mixtral第一和第一二选择一致率高于随机情况,特别是中间的第15层,说明了模型在专家选择上是具有倾向性的。

论文地址:
https://arxiv.org/abs/2401.04088
- 宇树机器人强化学习代码全面开源,训练到仿真和实操手把手教学2024-12-17
- OpenAI员工意外泄露下一代ChatGPT!网友:故意的还是不小心的?2024-12-11
- AI营销的风,还是吹到了A股2024-12-05
- 通信巨头入局视频生成,直接霸榜权威评测:人物跨越多场景依然一致2024-12-05
相关阅读