大模型版“5年高考3年模拟”来了!6141道数学题,还是多模态的那种|微软&UCLA&UW联合出品
附带12个大模型112页“试题”分析
Pan Lu 投稿
量子位 | 公众号 QbitAI
大模型的“5年高考3年模拟”数学题来了,还是加强强强版!
微软、加州大学洛杉矶分校(UCLA)、华盛顿大学(UW)联合打造全新多模态数学推理基准数据集。
名为“MathVista”。
涵盖各种题型共6141个问题,来源于28个现有的多模态数据集和3个新标注的数据集。
这下想要知道一个大模型数学水平怎么样,直接让它来做这份试卷。

12个最新的大模型已经抢先体验了一把试题难度。
一份112页的详细评测报告连同数据集一起发布。
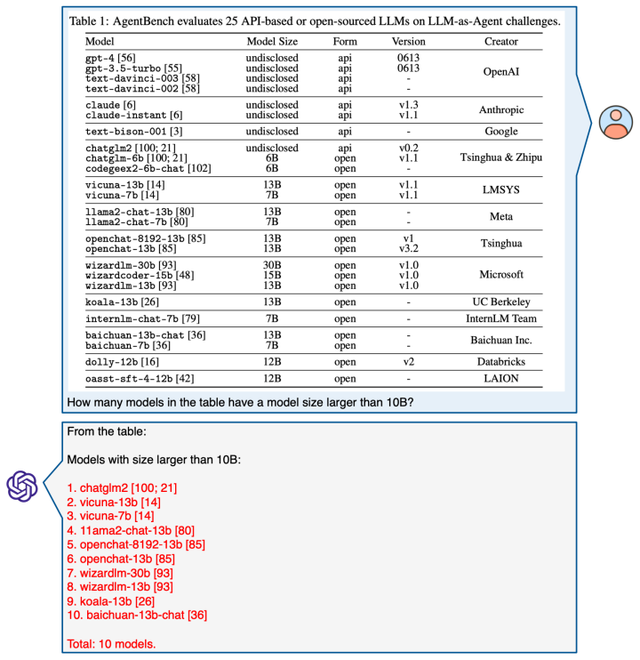
报告显示,面对MathVista中丰富的任务类型、推理方式和图像类型,即使是当前最先进的GPT-4V做起来都有“挫败感”,准确率为49.9%,和人类还有10.4%的差距。
Bard排名第二,准确率为34.8%,差距再次拉大。

此外,报告中还深入分析了GPT-4V在自我验证、自洽性和多轮对话能力的研究潜力等。
详细内容我们接着往下看。
MathVista基准数据集
数学推理能力被视为实现AGI关键一步。除了传统的纯文字场景,许多数学研究和应用还涉及到丰富的图形内容。
然而,大模型在视觉场景下的数学推理能力尚未被系统地研究。
因此,微软联合加州大学洛杉矶分校(UCLA)和华盛顿大学(UW)共同开发了这一多模态数学推理基准数据集——MathVista,聚焦于视觉场景下的数学问答任务。

正如上文提到的,MathVista包含6141个数学问题,来自于28个现有数据集和3个新标注数据集。
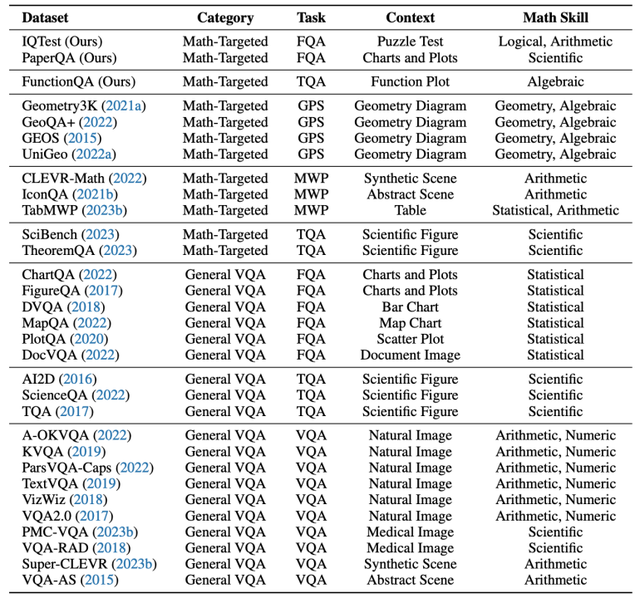
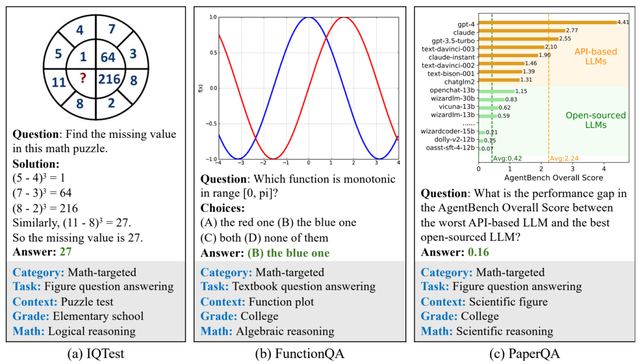
其中三个新标注的数据集是IQTest、FunctionQA和PaperQA,各有特色。
IQTest侧重于智力测试题,FunctionQA专注于函数图形的推理,而PaperQA则关注于对文献中的图表进行深入理解,有效地弥补了现有数据集的不足。
此外,MathVista覆盖了两种主要的任务类型:多选题(占比55.2%)和数值型开放题(占比44.8%)。
包括五大任务类别:图形问答(FQA)、几何解题(GPS)、数学应用题(MWP)、教材问答(TQA)和视觉问答(VQA)。
这些任务类别代表了当前数学推理领域的前沿挑战。

细分来看,MathVista定义了数学推理的七大能力领域,包括算术、统计、代数、几何、数值常识、科学和逻辑。

这些领域涵盖了数学推理的核心要素,体现了MathVista在数学认知范围的全面覆盖。

在图像类型的多样性方面,MathVista也展现了其独特的广度和深度。
该数据集包含了十余种不同的图像类型。
从自然图像到几何图表 :

从抽象场景到合成场景:


以及各种图形、图表和绘图:
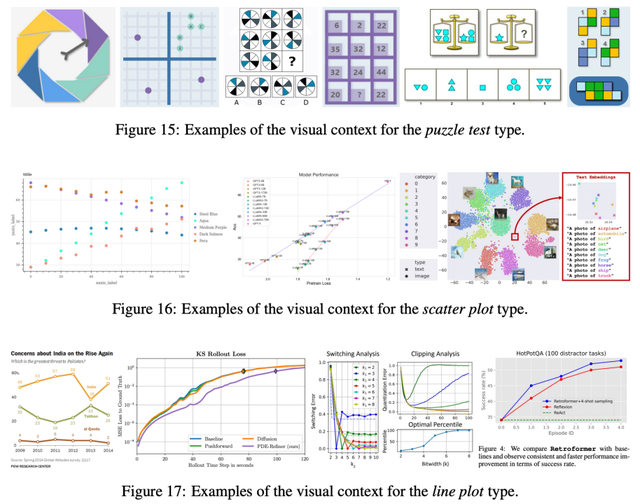
这种丰富的图像类型不仅增加了数据集的复杂性,也为多模态大模型在处理不同类型的视觉信息时提供了全面的挑战。
全面的量化评估
研究报告中,首次对当前大型模型在视觉场景下的数学推理能力进行了全面的量化评估。
报告中使用的MathVista数据集分为两个子集:minitest和test。
minitest子集含有1000个问题,主要用于快速评估模型性能。
而test子集则包含剩余的5141个问题,旨在进行模型的标准化评估,为了避免测试数据污染,该子集的答案标签数据不对外公开。
模型评估过程分为三个关键阶段:生成回答、抽取答案和计算分数。
在生成回答阶段,根据测试问题的类型,研究团队使用了特定的模板来引导模型输出答案。

考虑到当前大型模型通常以对话形式输出长文本回答,报告中的实验设计了一个基于GPT-4的答案抽取器。
这个抽取器通过几个实例提示GPT-4,从模型的长文本回答中抽取出符合题目类型的短答案。这种方法有效地克服了传统人工评估的高成本问题和基于规则的答案抽取可能导致的不准确性。
随后,这些抽取出来的短文本答案被用于计算模型的总体准确率以及在不同子分类别下的准确率。

大模型们表现如何?
实验在testmini子集上评估了12种大模型:包括ChatGPT、GPT-4和Claude-2三个大语言模型,以及LLaVA、LLaMA-Adapter、miniGPT-4、Bard和GPT-4V等九种多模态大模型。
对于大语言模型,实验设计了两种形式:
第一种只利用问题的文字信息;
第二种是使用图片的Captioning描述和OCR文作为外部增强信息。
此外,实验还完成了两种随机基准和人类表现基准。

实验结果显示,当前的大模型在MathVista上的整体表现仍有待提升。
表现最佳的GPT-4V模型达到了49.9%的准确率,但这与人类的60.3%表现相比还有显著差距。
其次是Bard模型,准确率为34.8%,而目前最好的开源模型LLaVA的准确率则为26.1%。
这些数据表明,大模型在视觉背景下的数学推理能力还有很大的提升空间。
有趣的是,当结合图像OCR和Captioning信息时,大语言模型GPT-4的表现(33.9%)接近于多模态模型Bard(34.8%)。这一发现显示,通过适当的工具增强,大型语言模型在多模态领域具有巨大的潜力。
实验还对主要模型在不同数学推理能力和图像类型子类上的表现进行了量化评估。
结果显示,GPT-4V在诸如代数、几何和科学领域的推理能力上,以及在处理表格、函数图、几何图像、散点图和科学图形等图像类型时,其表现接近甚至超过了人类。
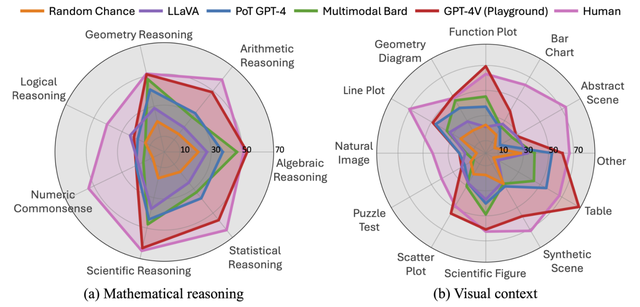
在test子集的评估中,实验比较了最佳的两个大语言模型(CoT/PoT GPT-4)和最好的开源大型多模态模型(LLaVA),提供了一个全面的模型性能概览。

下面是更为详细的分析。
Bard在MathVista中的表现
在MathVista上的评估显示,Bard模型的总体表现紧随GPT-4之后。通过具体案例分析,报告发现Bard模型经常产生所谓的“幻觉现象”,即在生成的答案中引入了问题文本和图片中不存在的信息。
此外,Bard在进行数学运算时也容易出现错误。

例如,在下面的例子中,Bard在简化分式8/10的过程中犯了计算错误。这种问题突显了模型在处理数学问题时的局限性。

GPT-4在MathVista上的表现
虽然GPT-4本质上是一种语言模型,但通过工具增强(例如OCR文字和captioning描述的结合),它在MathVista上的性能可以达到与多模态模型Bard相当的水平。
具体来说,当引入这些图片的OCR文字和Captioning描述作为辅助输入信息时,GPT-4能够成功解决许多多模态数学问题。这一发现显示了GPT-4在多模态问题处理方面的潜力。
然而,GPT-4对这些增强信息的准确性有着极高的依赖性。
如果这些OCR文字或Captioning描述存在错误或不准确性,GPT-4在推理过程中就很容易走向错误的方向,从而导致不正确的结果。
这一点凸显了在使用工具增强大型语言模型时,输入信息质量的重要性。

GPT-4V在MathVista上的全方位分析
GPT-4V作为目前最先进的多模态大模型,对其能力的深入分析对未来的研究具有重要意义。报告通过大量实例详尽分析了GPT-4V在不同维度的能力,特别是在自我验证、自洽性和多轮对话方面的巨大潜力。
- 代数推理能力:
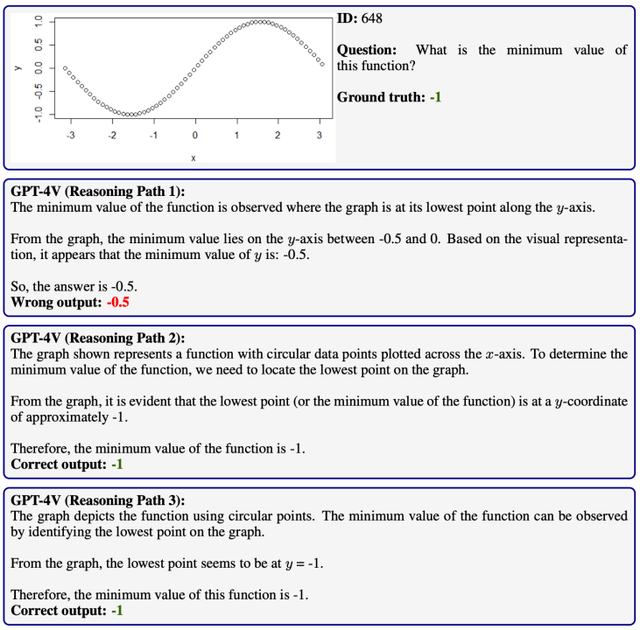
在MathVista的代数问题中,GPT-4V展现了理解图像中函数并推断其性质的出色能力,甚至超过了其他大型模型和人类。但在处理低分辨率图像和多函数图像时,GPT-4V仍面临挑战。


- 数值计算能力:
MathVista中的算术问题不仅需要准确的基础运算,还需理解多样化视觉场景。如下图所示,GPT-4V在此方面相比现有模型表现出显著的提升。

- 几何推理能力:
在几何推理方面,GPT-4V在MathVista上的表现与人类相当。在以下两个例子中,无论是小学难度还是高年级难度的问题,GPT-4V均能给出正确答案,并附有详细解释。



- 逻辑推理能力:
在MathVista的逻辑推理问题中,模型需从抽象图形中推导出数字或形状的隐含规律。GPT-4V在这方面遇到了挑战,其准确率仅为21.6%,仅略高于随机猜测的8.1%。


- 数值常识推理能力:
MathVista中的数值常识推理涉及日常物品和名人知识。这类问题对大型模型是一大挑战。例如,下图所示的问题中,只有GPT-4V能正确理解图像中的光学错觉现象。

然而,某些情况下,例如识别烧杯的最大容量,GPT-4V与Bard模型均表现不佳。

- 科学推理能力:
在MathVista的科学推理问题上,GPT-4V显著优于其他大型模型。它经常能准确解析涉及特定科学领域的图中信息,并进行后续推理。


然而,某些基本概念的应用,如相对运动,仍是GPT-4V的弱点。


- 统计推理能力:
GPT-4V在理解MathVista中的各种图表、绘图和图形方面展现出强大的统计推理能力。它能准确解答涉及图表分析的数学问题,超过了其他大型模型。



GPT-4V的自我验证能力探究
自我验证(self-verification)是一种社会心理学概念,其核心观点是个体希望他人按照他们自我感知的方式来理解他们。这导致个体主动采取行动,确保他人能看到他们的稳定状态(Talaifar & Swann, 2020)。
在实验中,研究人员表示GPT-4V显示出了一种类似的自我验证能力。
这种能力体现在GPT-4V能够在推理过程中自主检查自身的行为,并主动纠正可能的错误。
值得注意的是,这种自我验证能力不同于仅依赖外部反馈或多轮对话来改进模型输出。
例如,在某些情况下,GPT-4V能够在单次输出中自行审核一组候选答案,从而识别出符合所有给定条件的有效答案。

在以下多步推理问题中,GPT-4V显示出了显著的能力。它不仅能够进行连贯的推理,还能验证关键步骤的有效性。
特别是在遇到无效的中间结果时,如发现得出的长度为负数,GPT-4V能够主动检测并识别这些错误。这种能力使得GPT-4V在识别问题后,能够尝试采用不同的方法来解决问题,从而优化其推理过程。


GPT-4V的自洽性应用及其局限性
自洽性(self-consistency)是在大型语言模型中广泛使用的一种技术,目的是提升模型在处理复杂推理任务时的准确性。这种方法通常包括采样多种推理路径,并选择出现频次最高的答案作为最终解。
研究人员的实验验证了自洽性技术在提高GPT-4V在MathVista上的性能方面的有效性。
实验表明,自洽性对于纠正GPT-4V在视觉感知和计算中的错误,以及减少幻觉现象方面起到了显著作用。


然而,实验也揭示了自洽性的局限性。特别是在GPT-4V难以正确理解复杂的视觉场景的情况下,自洽性的改善效果并不显著。
这表明,尽管自洽性是一种有效的提升方法,但它的成功在很大程度上还是依赖于模型对视觉信息的基本理解能力。

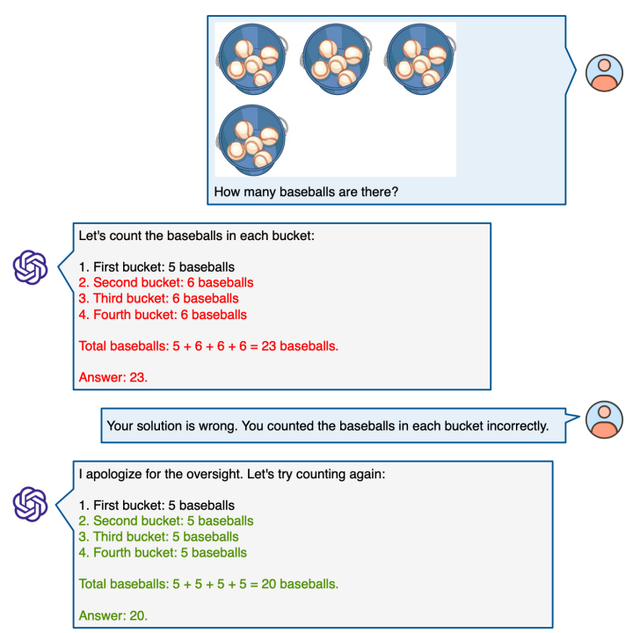
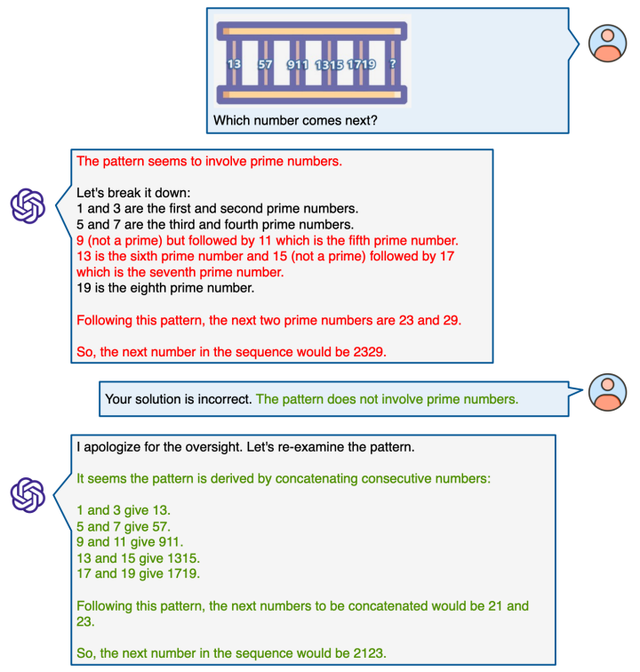
GPT-4V在MathVista上的多轮对话能力
微软的报告最后探讨了GPT-4V在MathVista上进行多轮人机互动对话的能力。
实验结果表明,GPT-4V擅长在多轮对话中有效地利用用户提供的提示来优化其推理过程。
这包括根据用户的引导来纠正视觉感知上的误解,修正推理逻辑中的不一致,更正相关领域的知识,甚至在人类的协助下理解和处理极其复杂的图表问题。

主要华人作者简介
Pan Lu

Pan Lu是加州大学洛杉矶分校(UCLA)的博士生,是UCLA自然语言处理实验室(NLP Group)和视觉、认知、学习和自主中心(VCLA)的成员。
在此之前,他在清华大学获得计算机科学硕士学位。他曾在微软和艾伦人工智能研究院进行过实习。
他是ScienceQA和Chameleon等工作的作者。他曾荣获亚马逊博士奖学金、彭博社博士奖学金和高通创新奖学金。
Tony Xia

Tony Xia是斯坦福大学计算机系的硕士生。此前,他在加州大学洛杉矶分校获得计算机本科学位。
Jiacheng Liu

Jiacheng Liu是华盛顿大学的博士生,从事常识推理、数学推理和文本生成的研究。
此前,他在伊利诺伊香槟分校取得本科学位。他曾获高通创新奖学金。
Chunyuan Li

Chunyuan Li是微软雷德蒙德研究院的首席研究员。
此前,他在杜克大学获得了机器学习博士学位,师从Lawrence Carin教授。他曾担任过NeurIPS、ICML、ICLR、EMNLP和AAAI的领域主席,以及IJCV的客座编辑。
他是LLaVA、Visual Instruction Tuning和Instruction Tuning等工作的作者。
Hao Cheng

Hao Cheng是微软雷德蒙德研究院的高级研究员,同时也是华盛顿大学的兼职教授。
此前,他在华盛顿大学获得了博士学位。他是2017年Alexa Prize冠军团队的主要成员。
论文地址:https://arxiv.org/abs/2310.02255
项目地址:https://mathvista.github.io/
HF数据集:https://huggingface.co/datasets/AI4Math/MathVista
数据可视化:https://mathvista.github.io/#visualization
Leaderboard:https://mathvista.github.io/#leaderboard
- 猫猫运动方程,首次被物理学家破解! |《美国物理学杂志》正经研究2024-11-18
- AI一键解析九大生物医学成像模式,用户只需文字prompt交互,微软UW等新研究登Nature Methods2024-11-21
- DeepSeek版o1炸场,数学代码超越OpenAI,每天免费玩50次,后续将开源2024-11-21
- 马斯克新官上任再起诉OpenAI!新证据称Ilya七年前就不放心奥特曼2024-11-16
相关阅读