三位数学家改写经典牛顿法!300年前算法一夜更新,收敛速度更快函数范围更广
耶鲁华人数学家参与
300年经典牛顿法,迎来重磅升级!
三位普林斯顿数学家找到更快更强的解法,其中还有一位是华人。
牛顿法是啥?学过高数的同学想必并不陌生,它通过不断求导来寻找复杂函数f(x)接近零点的最优解。
就是这么一个非常简单的「近似求解」算法,因为收敛速度非常快,时至今日它仍被广泛应用在计算机视觉、物流、金融甚至纯数学问题等各个领域,比如开发能够区分交通信号灯和停车标志的自动驾驶汽车。
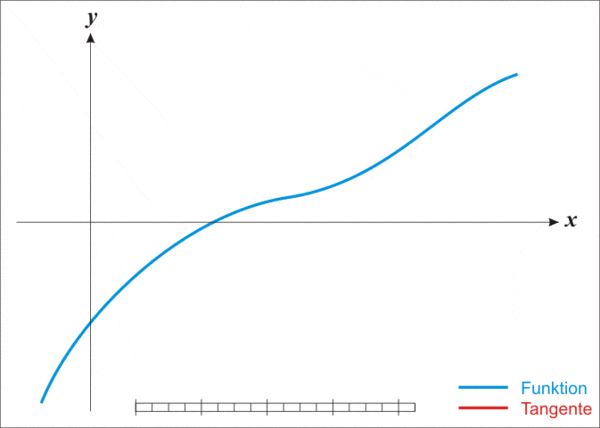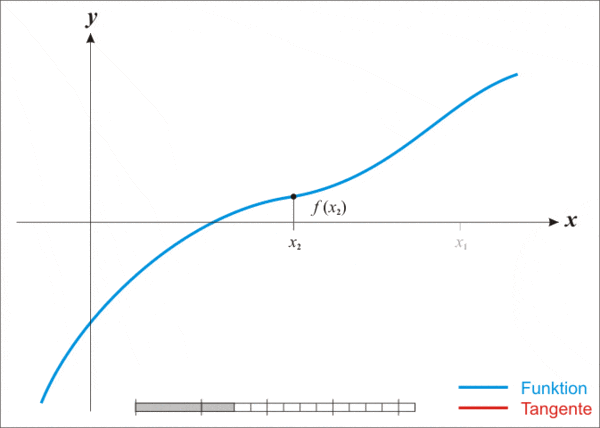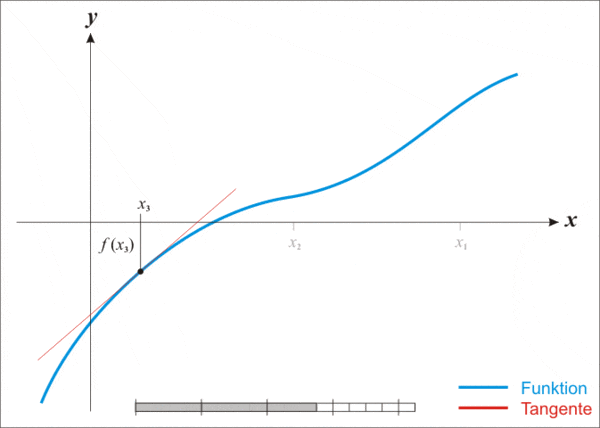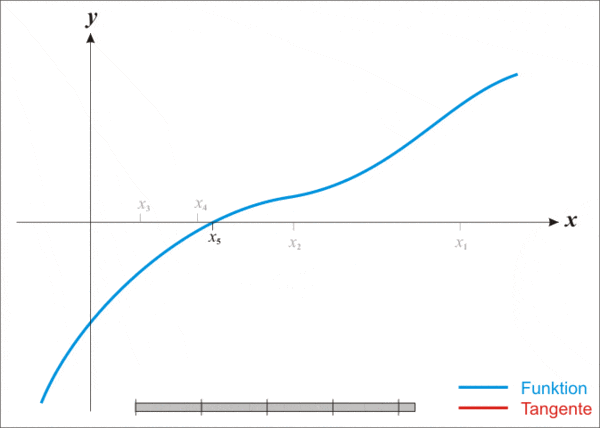
但即便这么强大,牛顿法也存在一个缺点,那就是不适用于所有函数。
于是乎,过去几个世纪诸多数学家前赴后继企图在此基础之上进行优化。现在这三位数学家成功将可适用的函数范围一扩再扩。
比如像这个复杂的二元函数。

与传统牛顿法相比,新方法展现出来的更连贯,覆盖也很大。
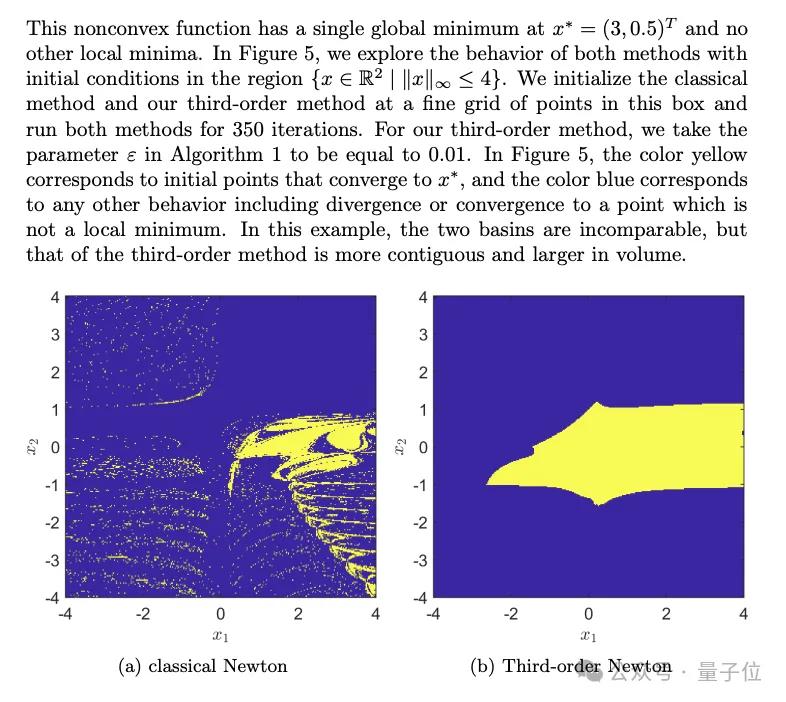
一合著者表示,牛顿法在优化中有1000种不同的应用,而他们的算法有可能取代它。
来看看究竟是咋回事儿。
三位数学家改写经典牛顿法
牛顿法(Newton’s Method)诞生于17世纪,由大名鼎鼎的英国数学家牛顿首次提出。
其核心思想是,通过不断逼近函数的根或极小值点,以寻找函数的最优解。
通俗来说,这有点像在陌生环境里蒙眼寻找最低点。在行走过程中,我们唯一需要的信息在于两点:1)自己是否在上坡或者下坡,即斜率(函数的一阶导数);2)以及坡度是增加还是减少,即斜率本身的变化率(函数的二阶导数)。
利用上述信息,我们可以相对快速地得到一个近似值。
若将这一过程用数学方法来表示,则具体如下:
- Make a guess(做一个猜测):选择一个接近你认为可能是最小值的起始点,作为寻找函数最小值的起点;
- Model the curve(模拟曲线):在该点附近构造一个抛物线,以近似原函数的形状;
- Find the next point(找到下一个点):计算抛物线的最低点,以此作为新的迭代点;
- Repeat(重复):使用新的迭代点重复上述步骤,逐步逼近函数的最小值;
- Keep going(继续进行):持续迭代,直至找到函数的最小值。
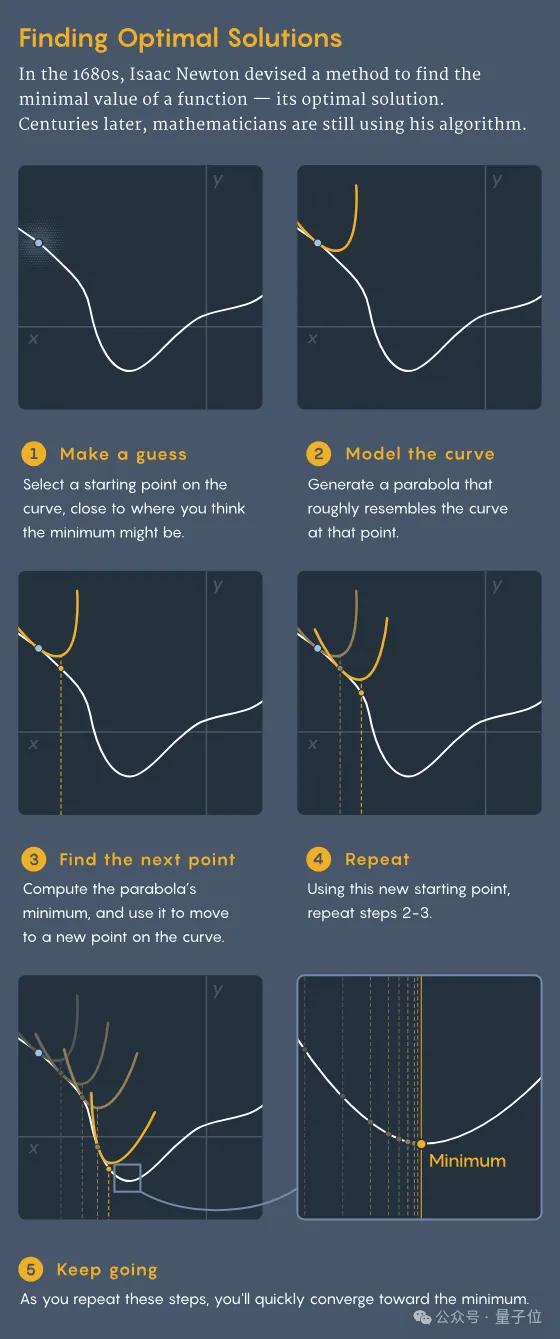
牛顿证明了,只要不断重复上述过程,最终就会逼近原始复杂函数的最小值。
而且和类似迭代方法(如梯度下降)相比,牛顿法虽然每次迭代的计算成本高于梯度下降,但在效率方面优势明显。
简单来说,牛顿法收敛速度相比梯度下降法更快,即在更少的迭代次数内找到最小值,因此也适用于多种情况。
不过牛顿当时也提醒:
虽然这一方法在大多数情况下有效,但如果一开始从一个距离真实最小值太远的点开始,则可能越跑越偏。

而且更麻烦的是,牛顿法还存在一个显著缺点——不适用于所有函数。
其核心策略是将一个复杂函数转化为一个更简单的函数,而一旦函数过于复杂,它也同样没辙了。
因此后来数学家们努力的方向在于,在不牺牲效率的前提下扩大算法使用范围。
直到去年夏天,三位研究人员发表了对牛顿法的最新改进。
将牛顿法扩展到迄今为止最广泛的函数类别
具体而言,他们发现牛顿法在处理某些复杂函数(如高次幂函数)时效果不好,这是因为它依赖于函数的泰勒展开(一种使用求导和多项式逼近原函数的手段),而这个展开并不总是能很好地描述原函数,特别是当函数有很多“山谷”(局部最小值)时。
于是他们提出,如果一个函数满足两个条件,那么它就更容易找到最小值:
- 凸形(Convex):函数的形状像一个碗,只有一个“山谷”
- 平方和(Sum of Squares):函数可以表示为一些平方项的和
前者意味着如果从任何位置开始寻找,都不会陷入局部最小值的问题,因为只有一个最小值,而且无论从哪个方向开始,都会滑向这个唯一的最低点。
后者意味着可以很容易地识别和计算函数的最小值,因为平方和形式的函数特别容易处理,其平方数总是非负的,而且它们的最小值是0。
接下来,为了满足上述条件,他们使用了一种叫做半定规划(Semidefinite Programming)的技术来调整泰勒展开,具体步骤如下:
1、微调泰勒展开。不直接使用函数的泰勒展开,而是对其进行微调,使其既凸形又可以表示为平方和。
2、增加调整因子。在泰勒展开中加入一个调整因子,这个因子可以帮助他们控制展开的形状,使其更接近原函数,同时满足凸形和平方和的条件。
3、多导数收敛。他们的方法可以使用任意多个导数来进行泰勒展开,这意味着他们可以更快地找到函数的最小值。使用更多的导数可以让算法以更高的速度(比如立方速度)收敛到最小值。
最终他们创造了这种更强版本的牛顿法,能够以更少的迭代次数找到最小值。
他们的算法如下:

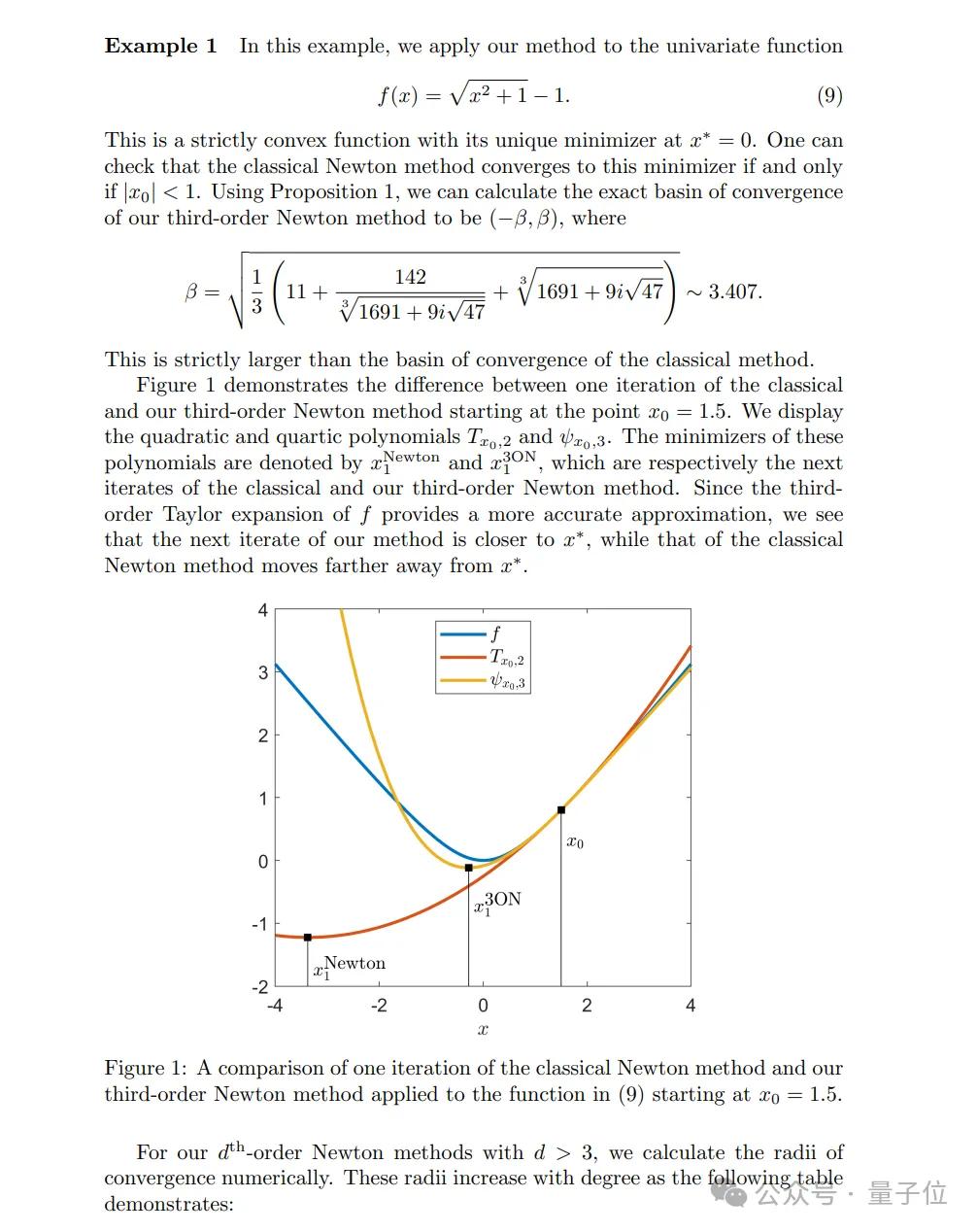
在下面这个函数中,与传统牛顿法相比,其改进版本(第三阶牛顿法)在理论上提供了更快的收敛速度,并且在实践中可能比经典牛顿法更有效,尤其是在初始点离最小值点较远的情况下。
一位华人参与
这项工作是三位数学家在普林斯顿大学期间合作完成的。

其中华人Jeffrey Zhang,目前是耶鲁大学生物医学信息学与数据科学博士后研究员,研究方向包括大型语言模型、数据科学和统计学、计算复杂性、多项式优化、博弈论和机制设计。

此前在普林斯顿大学获得运筹学和金融工程博士学位,导师正是同为该论文作者的Amir Ali Ahmadi教授。
更早之前,他在2014年获得耶鲁大学计算机科学和经济学与数学学士学位。
另一位作者Abraar Chaudhry也是Amir Ali Ahmadi教授的学生,现乔治亚理工学院博士后研究员。在普林斯顿攻读博士之前,他在布朗大学读本科。
事实上,在这三位数学家出现之前,有很多数学家都进行了尝试。
最早19世纪,被称为「俄罗斯数学之父」的Pafnuty Chebyshev提出了一种牛顿法,用三次方程(指数为3)近似函数。
不过当原始函数涉及多个变量时,他的算法就会不起作用。
更近的一次,2021年俄罗斯数学家Yurii Nesterov展示了如何使用三次方程有效地逼近任何数量的变量的函数。
但他的方法无法扩展到使用四次方程、五次方程等近似函数,否则会降低其效率。

现在,3位数学家将内斯特罗夫的结果又推进了一步。
与牛顿法的原始版本一样,这种新算法的每次迭代在计算上仍然比梯度下降等方法成本更高。
因此,目前这项新工作不会改变自动驾驶汽车、机器学习算法或空中交通管制系统的运作方式。在这些情况下,最好的选择仍然是梯度下降。
宾夕法尼亚大学Jason Altschuler表示:许多优化理念需要花费数年时间才能完全付诸实践。不过这似乎是个全新的视角。
如果随着时间的推移,运行牛顿法所需的底层计算技术变得更加高效,使得每次迭代的计算成本更低,那么Ahmadi、Chaudhry和Zhang开发的算法最终可以在包括机器学习在内的各种应用中超越梯度下降。
合著者表示,从理论上讲,他们目前的算法确实更快。
论文:
https://arxiv.org/pdf/2311.06374
- 人人可用的超级智能体!100+MCP工具随便选,爬虫小红书效果惊艳2025-04-29
- 当购物用上大模型!阿里妈妈首发世界知识大模型,破解推荐难题2025-05-01
- OceanBase全员信:全面拥抱AI,打造AI时代的数据底座2025-04-27
- 网易有道张艺:AI教育的规模化落地,以C端应用反推大模型发展2025-04-27