打脸!GPT-4o输出长度8k都勉强,陈丹琦团队新基准测试:所有模型输出都低于标称长度
LLM生成长段回复的能力还有待加强
奇月 发自 凹非寺量子位 | 公众号 QbitAI
很多大模型的官方参数都声称自己可以输出长达32K tokens的内容,但这数字实际上是存在水分的??
最近,陈丹琦团队提出了一个全新的基准测试工具LONGPROC,专门用于检测长上下文模型处理复杂信息并生成回复的能力。

实验结果有点令人意外,团队发现,包括GPT-4o等最先进的模型在内,尽管模型在常用长上下文回忆基准上表现出色,但在处理复杂的长文生成任务时仍有很大的改进空间。
具体来说,测试的所有模型都声称自己上下文窗口大小超过32K tokens,但开源模型一般在2K tokens任务中就表现不佳,而GPT-4o等闭源模型在8K tokens任务中性能也明显下降。
举例来说,让GPT-4o模型生成一个详细的旅行规划时,即使提供了相关的时间节点和直飞航班线路,在模型的生成结果中仍然出现了不存在的航班信息,也就是出现了幻觉。

这到底是怎么回事呢?
全新LONGPROC基准
目前现有的长上下文语言模型(long-context language models)的评估基准主要集中在长上下文回忆任务上,这些任务要求模型在处理大量无关信息的同时生成简短的响应,没有充分评估模型在整合分散信息和生成长输出方面的能力。
为了进一步精确检测模型处理长上下文并生成回复的能力,陈丹琦团队提出了全新的LONGPROC基准测试。
从表1中各测试基准的对比可以看出,只有LONGPROC基准同时满足6个要求,包括复杂的流程、要求模型输出大于1K tokens、且提供确定性的解决方案等。

新基准包含的任务
具体来说,LONGPROC包含6个不同的生成任务:
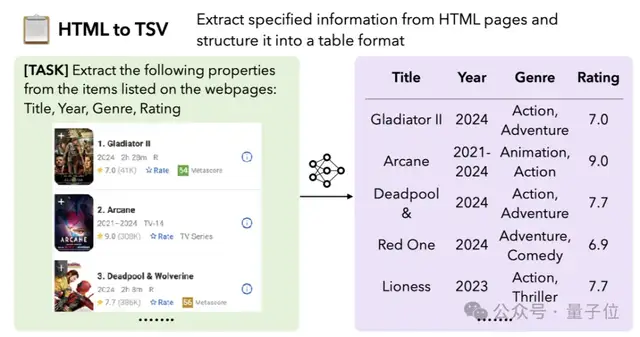
1.HTML到TSV:要求模型从HTML页面中提取指定信息并格式化为表格。需要从复杂的HTML结构中稳健地提取所有相关信息,并将其正确格式化。
比如从下面的网页中提取出所有影片的信息:
2.伪代码生成代码:要求模型将伪代码翻译成C++代码。需要保持源代码和目标代码之间的一一对应关系,并确保翻译的正确性。
3.路径遍历:要求模型在假设的公共交通网络中找到从一个城市到另一个城市的路径。需要确保路径的唯一性和正确性。
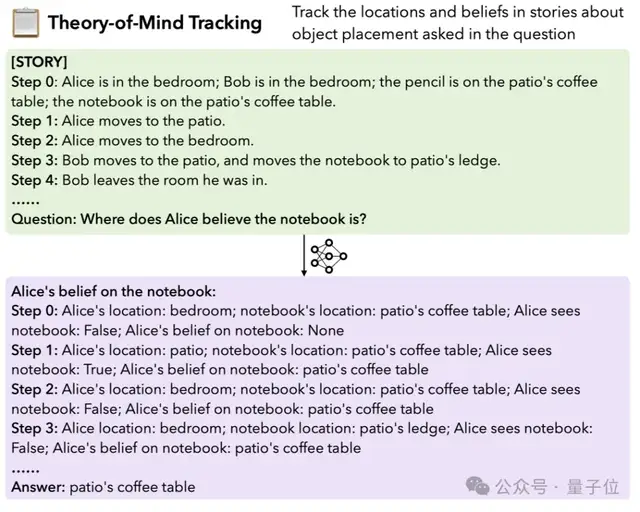
4.Theory-of-Mind跟踪:要求模型跟踪故事中对象位置的思想变化。需要进行长距离的推理,以准确反映对象在不同时间点的位置和状态。
比如根据下面的文字叙述推断出“Alice认为笔记本在哪里”:
5.Countdown游戏:要求模型使用四个数字和基本算术操作找到达到目标数字的方法。需要进行深度优先搜索,并确保搜索过程的完整性和正确性。
比如在下面的示例中,要求模型用四则运算操作输入的数字,最终得出29的结果:

6.旅行规划:要求模型生成满足多种约束的多城市旅行计划。需要探索多种可能的行程安排,并确保所有约束条件得到满足。
如下图所示,图中要求模型根据任务提供的欧洲行程计划和直飞航班规划最佳的旅行时间安排:

在输出结果的同时,LONGPROC还会要求模型在执行详细程序指令的同时生成结构化的长形式输出 。
从表2中可以看出,除了对比左边的实例数量(N)、输入和输出tokens的平均数量(#In/#Out),团队还会从表格最右3列的获取信息的方式、是否存在演绎推理和执行搜索这三个方面对任务进行比较。
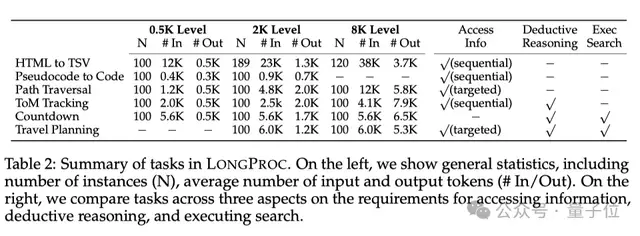
实验任务设置
实验中,上面的6个任务都有不同的数据集。例如,HTML到TSV任务使用了Arborist数据集中的56个网站;伪代码生成代码任务使用了SPOC数据集;路径遍历任务构建了一个假设的公共交通网络等等。
实验都会要求模型执行一个详细的程序来生成输出。
此外,根据任务的输出长度,数据集会被分为500 tokens、2K tokens和8K tokens三个难度级别。比如对于HTML到TSV任务来说,每个网站都会被分割成非重叠子样本,这样就可以获得更多数据点。
参与实验的模型包括17个模型,包括流行的闭源模型(如GPT-4o、Claude 3.5、Gemini 1.5)和开源模型(如ProLong、Llama-3、Mistral-v0.3、Phi-3、Qwen-2.5、Jamba)。
实验结果及分析
首先来看看实验中模型的整体表现。
结果有点令人意外,所有模型在长程序生成任务中都表现出显著的性能下降!具体的数值可以查看下面的表3。
即使是GPT-4o这种前沿模型,在8K tokens的输出任务上也难以保持稳健的表现。
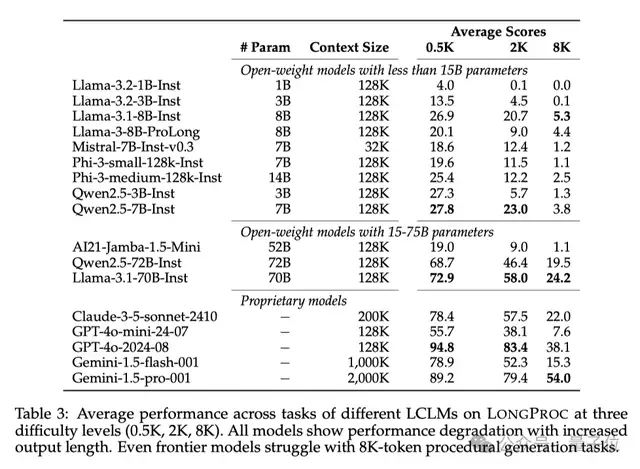
我们再来详细分析一下不同模型之间的差异。
根据下面的图3可以看出,像GPT-4o这样的顶尖闭源模型在0.5K任务上表现最佳,但在8K任务上性能显著下降。
小规模的开源模型基本都表现不佳,而中等规模的开源模型(Llama-3.1-70B-Instruct)在低难度任务上表现与GPT-4o相差不大。
不过,在某些8K任务上,中等规模的模型表现很不错,比如Gemini-1.5-pro在HTML to TSV任务中就超过了GPT-4o,Llama-3.1-70B-Instruct、Qwen2.5-72B-Instruct在8K的Countdown游戏中也与GPT-4o相差不大。
但整体来看,开源模型的性能还是不及闭源模型。
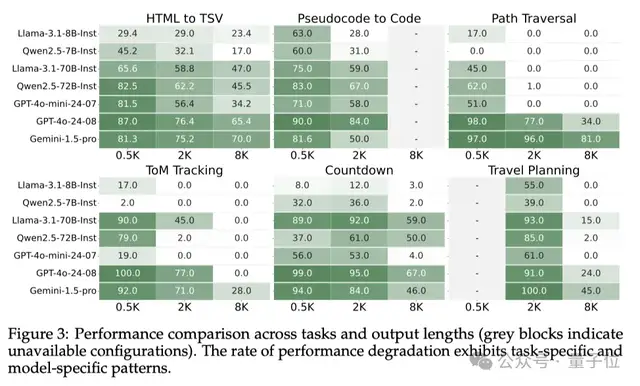
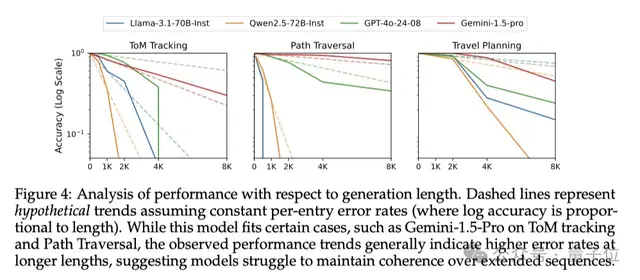
此外,模型表现跟任务类型也有关系。在需要更长推理的任务中,模型的性能普遍出现了更显著的下降。
如图4所示,在Theory-of-Mind跟踪、Countdown游戏和旅行规划任务这些需要处理更复杂的信息、进行更长链的推理的任务中,模型性能的下降幅度都更大,GPT-4o、Qwen等模型的精确度甚至直线下降。
除了对比17个模型之间的能力,团队成员还将表现较好的模型输出内容与人类输出进行了对比。
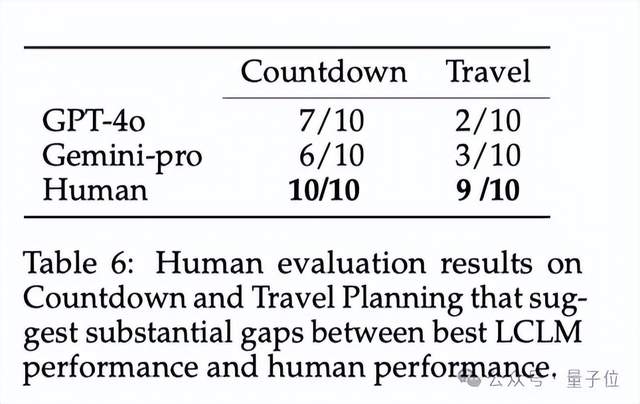
从表6的结果中可以看出,与人类能力相比,当前模型还存在显著差距。
人类在Countdown游戏和旅行规划任务中分别解决了10个和9个问题,而最好的模型GPT-4o分别只解决了7个和3个问题。
总体来说,本论文提出的LONGPROC测试基准有效地评估了模型在长程序生成任务方面的表现,是对现有基准的一个补充。
实验发现,即使是最先进的模型,在生成连贯的长段内容方面仍然有很大的改进空间。
尤其是在要求输出8k tokens的任务中,参数较大的先进模型也表现不佳,这可能是未来LLM研究的一个非常有意义的方向。
一作是清华校友
这篇论文的一作是本科毕业于清华软件学院的Xi Ye(叶曦),之后从UT Austin计算机科学系获得了博士学位。
清华特奖得主Tianyu Gao(高天宇)也有参与这篇论文:

据一作Xi Ye的个人主页显示,他的研究主要集中在自然语言处理领域,重点是提高LLM的可解释性并增强其推理能力,此外他还从事语义解析和程序综合的相关工作。
目前他是普林斯顿大学语言与智能实验室(PLI)的博士后研究员,还将从 2025 年 7 月开始加入阿尔伯塔大学(University of Alberta)担任助理教授。
PS:他的主页也正在招收25届秋季全奖博/硕士生哦
参考链接:
[1]https://arxiv.org/pdf/2501.05414
[2]https://xiye17.github.io/
- 好家伙,海螺直接拍了个AI版的《教父》2025-01-10
- 2025-01-08
- 用大模型吃瓜更智能了!阿里通义实验室提出新时间线总结框架2025-01-07
- 你的专属“钢铁侠”助手OSAgents来了!浙大等10个机构全新综述2025-01-03