MiniMax开源4M超长上下文新模型!性能比肩DeepSeek-v3、GPT-4o
现在就能免费玩
西风 发自 凹非寺
量子位 | 公众号 QbitAI
开源模型上下文窗口卷到超长,达400万token!
刚刚,“大模型六小强”之一MiniMax开源最新模型——
MiniMax-01系列,包含两个模型:基础语言模型MiniMax-Text-01、视觉多模态模型MiniMax-VL-01。
MiniMax-01首次大规模扩展了新型Lightning Attention架构,替代了传统Transformer架构,使模型能够高效处理4M token上下文。

在基准测试中,MiniMax-01性能与顶级闭源模型表现相当。
MiniMax-Text-01性能与前段时间大火的DeepSeek-V3、GPT-4o等打的有来有回:
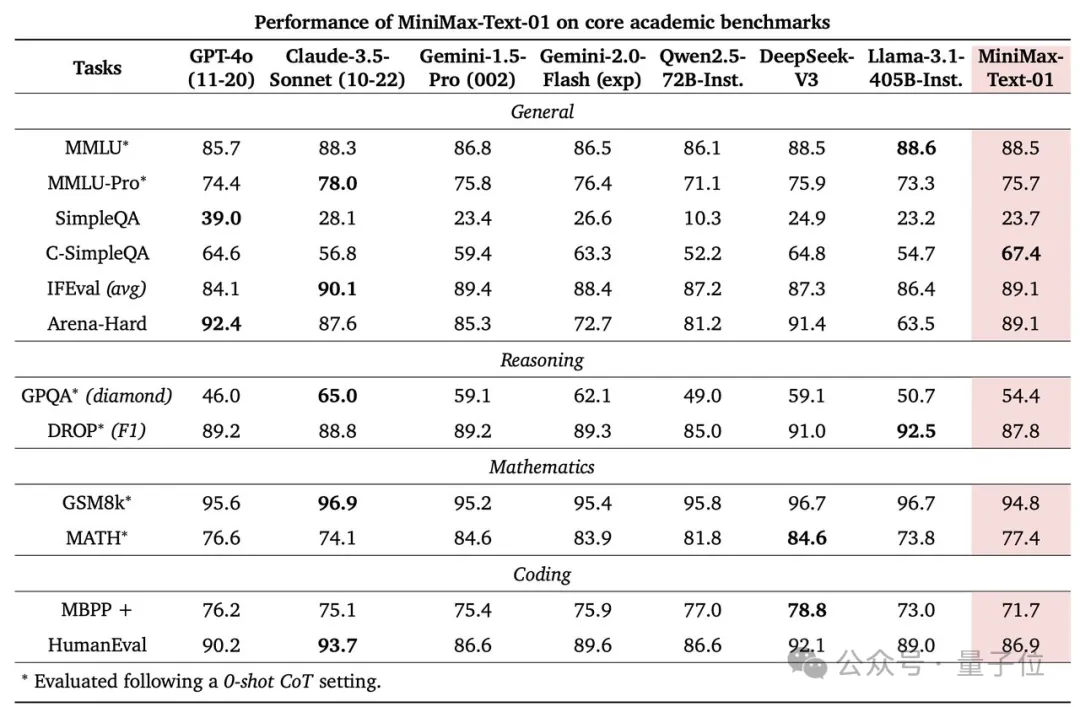
如下图(c)所示,当上下文超过20万token,MiniMax-Text-01的优势逐渐明显。
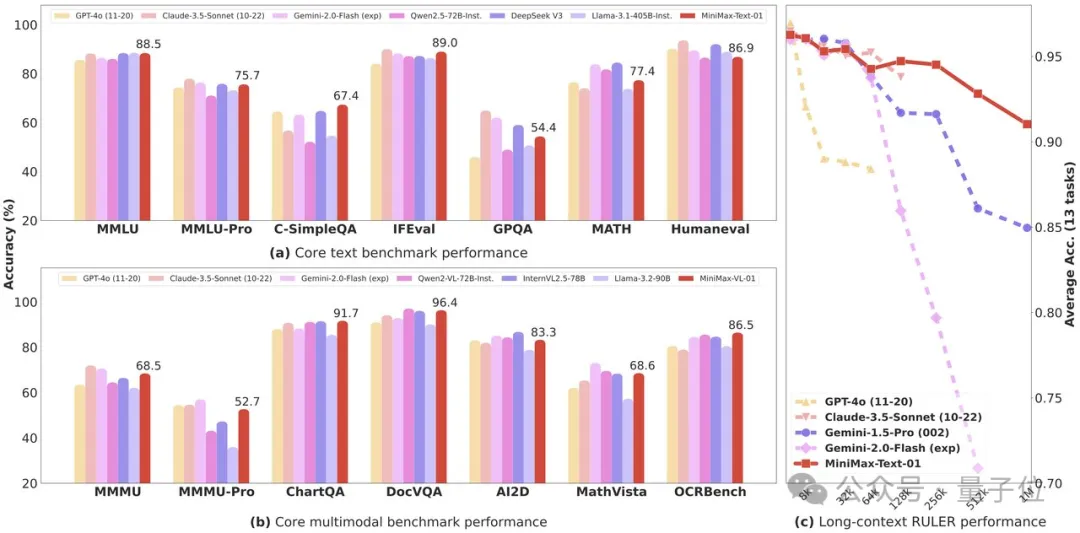
在预填充延迟方面也有显著优势,在处理超长上下文时更高效,延迟更低:
网友直呼“难以置信”:

开放权重,拥有400万token的上下文窗口!我原本以为这可能要五年后才会实现。

官方表示,MiniMax-01是为支持之后Agent相关应用而预备的:
因为Agent越来越需要扩展的上下文处理能力和持续的内存。
目前官方还公开了MiniMax-01的68页技术论文,并且已将MiniMax-01在Hailuo AI上部署了,可免费试用。
另外,新模型API价格也被打下来了:
输入每百万token0.2美元,输出每百万token1.1美元。

下面是模型更多细节。
4M超长上下文
MiniMax-Text-01
MiniMax-Text-01,参数456B,每次推理激活45.9B。
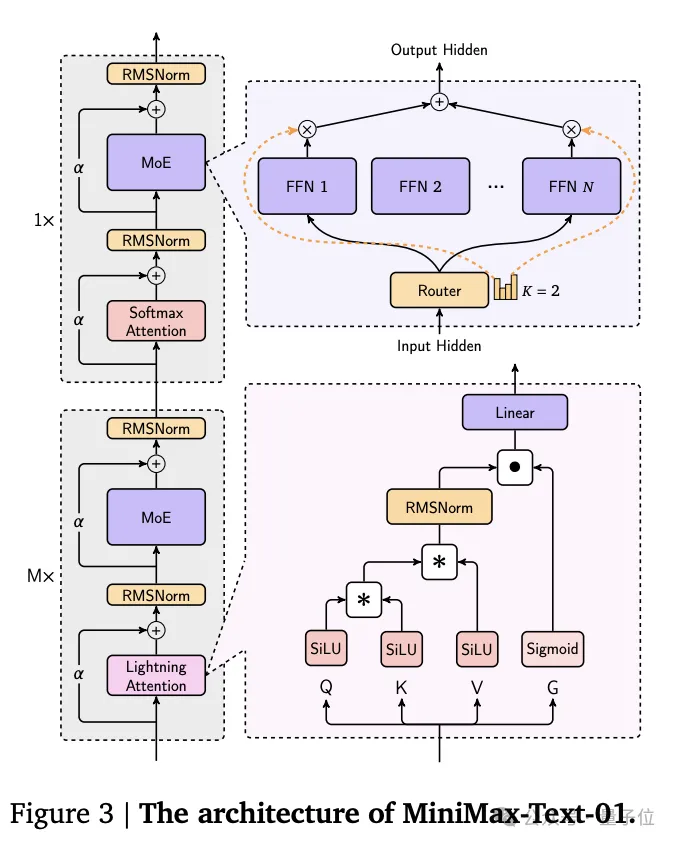
它创新性地采用了混合架构,结合了Lightning Attention、Softmax Attention以及Mixture-of-Experts(MoE)。
并且通过LASP+、varlen ring attention、ETP等优化的并行策略和高效的计算通信重叠方法,MiniMax-Text-01训练上下文长度达100万token,推理时可以扩展到400万token上下文。
模型架构细节如下:

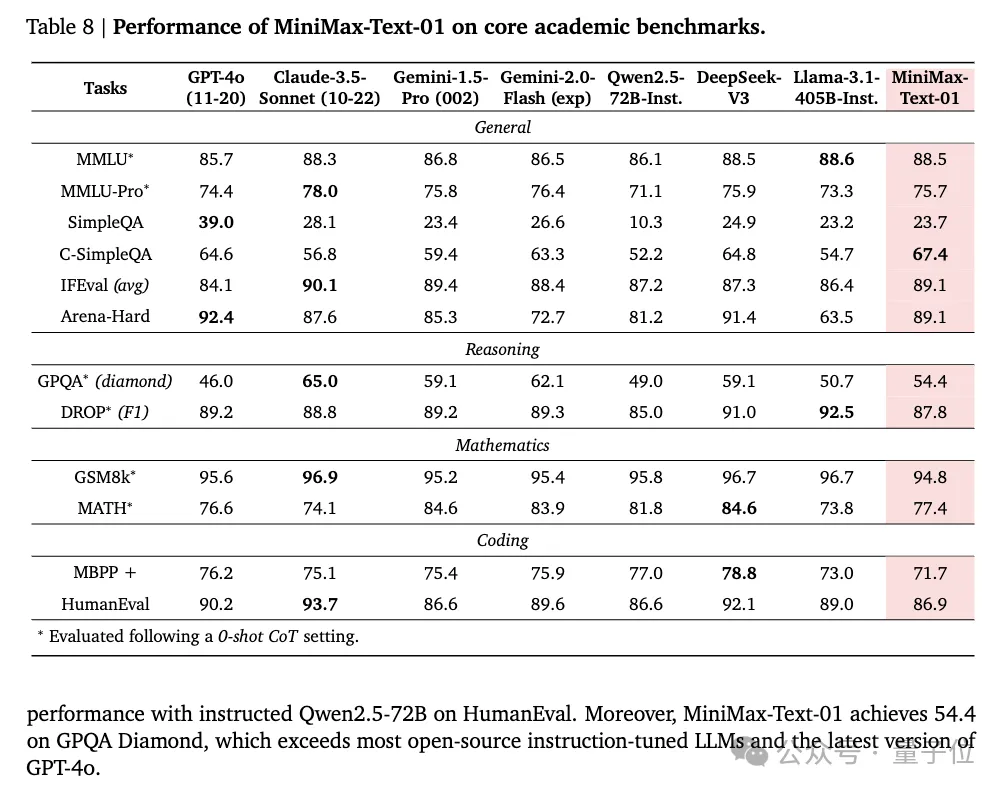
在Core Academic Benchmark上,MiniMax-Text-01在GPQA Diamond上获得54.4分,超越GPT-4o。
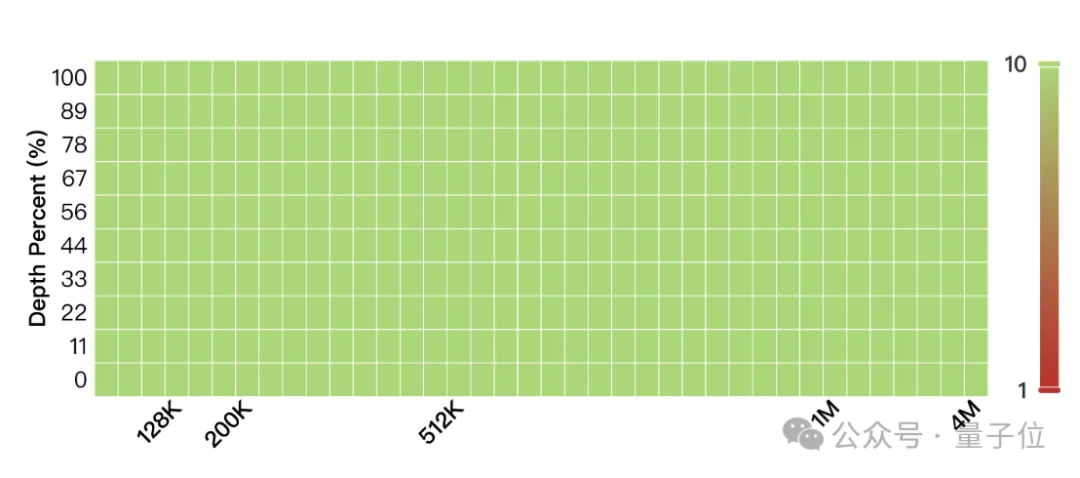
在长基准测试之4M大海捞针测试,MiniMax-Text-01一水儿全绿。
也就是说,这400万上下文里,有细节MiniMax-Text-01是真能100%捕捉到。
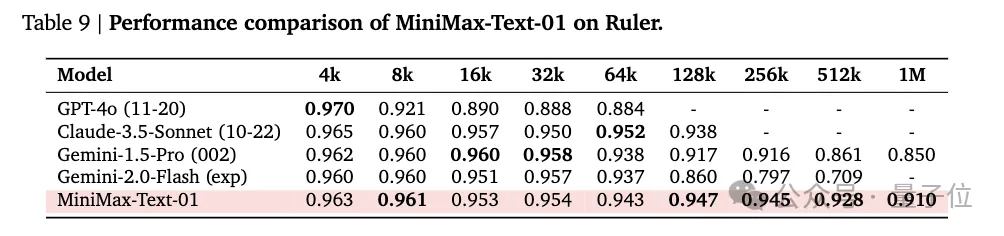
除此之外,还有LongBench v2、Ruler基准测试,考验的是模型长上下文理解能力,包含基于长上下文输入的逻辑推理能力。
MiniMax-Text-01模型在处理Ruler的长上下文推理任务时表现出显著的优势。
在64K输入级别的表现与顶尖模型GPT-4o、Claude-3.5-Sonnet等竞争力相当,变化微小,但从128K开始显现出明显的优势,并超越了所有基准模型。
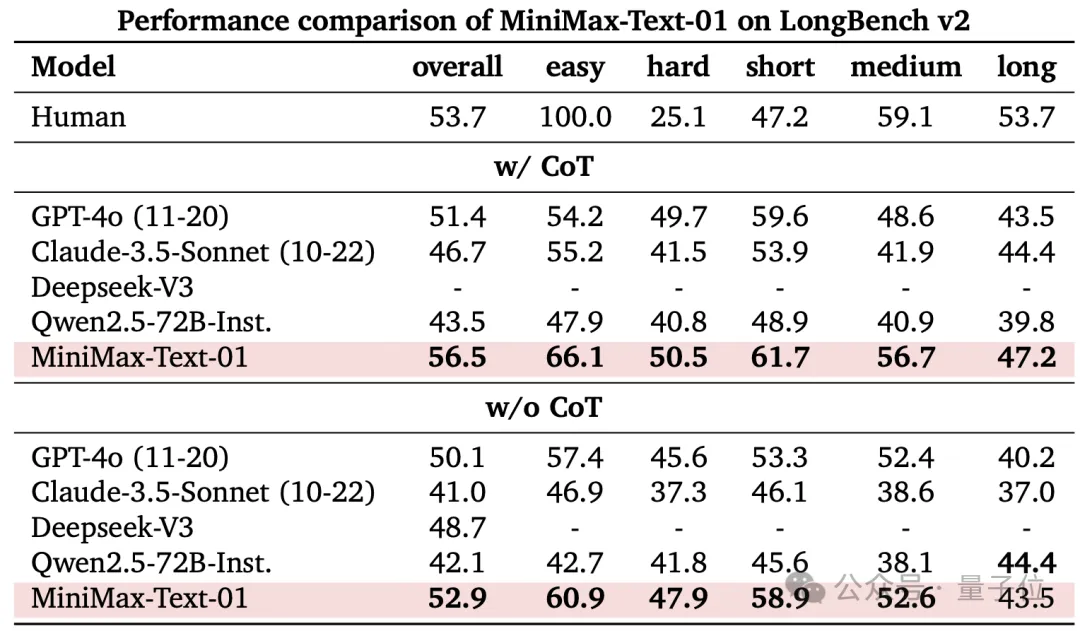
LongBench-V2包括不同难度级别的问答任务,涵盖多种上下文类型,包括单文档和多文档、多轮对话、代码仓库和长结构化数据等。团队考虑了两种测试模式:不使用思维链推理(w/o CoT)和使用思维链推理(w/ CoT)。
MiniMax-Text-01在w/ CoT设置中实现了所有评估系统中的最佳结果,在w/o CoT中表现也很显著。
团队还用MTOB( Machine Translation from One Book)数据集评估了模型从上下文中学习的能力。
该任务要求模型在英语和Kalamang(一种在公开数据中非常有限的语言)之间进行翻译,因此在训练语料库中,LLM仅从一部语法书的部分内容和375个翻译示例中学习该语言。
测试结果显示,MiniMax-Text-01在无上下文场景下eng→kalam (ChrF)得分最低,团队认为其它模型可能是在预训练或后训练数据中集加入了kalam相关数据。在delta half book和full book上,MiniMax-Text-01超过了所有模型。
在kalam→eng(BLEURT)得分上MiniMax-Text-01也与其它模型表现相当。

MiniMax-VL-01
MiniMax-VL-01采用多模态大语言模型常用的“ViT-MLP-LLM”框架:
- 一个具有3.03亿参数的ViT用于视觉编码
- 一个随机初始化的双层MLP projector用于图像适配
- 以及作为基础LLM的MiniMax-Text-01
MiniMax-VL-01特别具有动态分辨率功能,可以根据预设网格调整输入图像的大小,分辨率从336×336到2016×2016不等,并保留一个336×336的缩略图。
调整后的图像被分割成大小相同的不重叠块,这些块和缩略图分别编码后组合,形成完整的图像表示。
MiniMax-VL-01的训练数据涵盖标题、描述和指令。ViT从头开始在6.94亿图像-标题对上进行训练。在训练过程的四个阶段,处理了总计5120亿token。
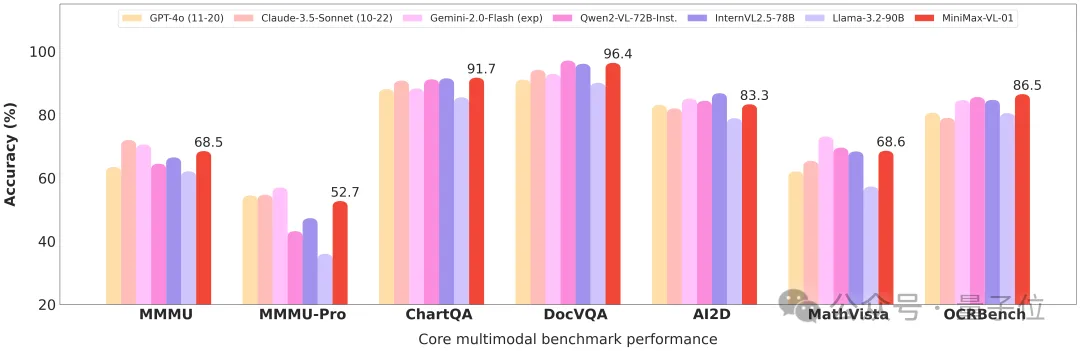
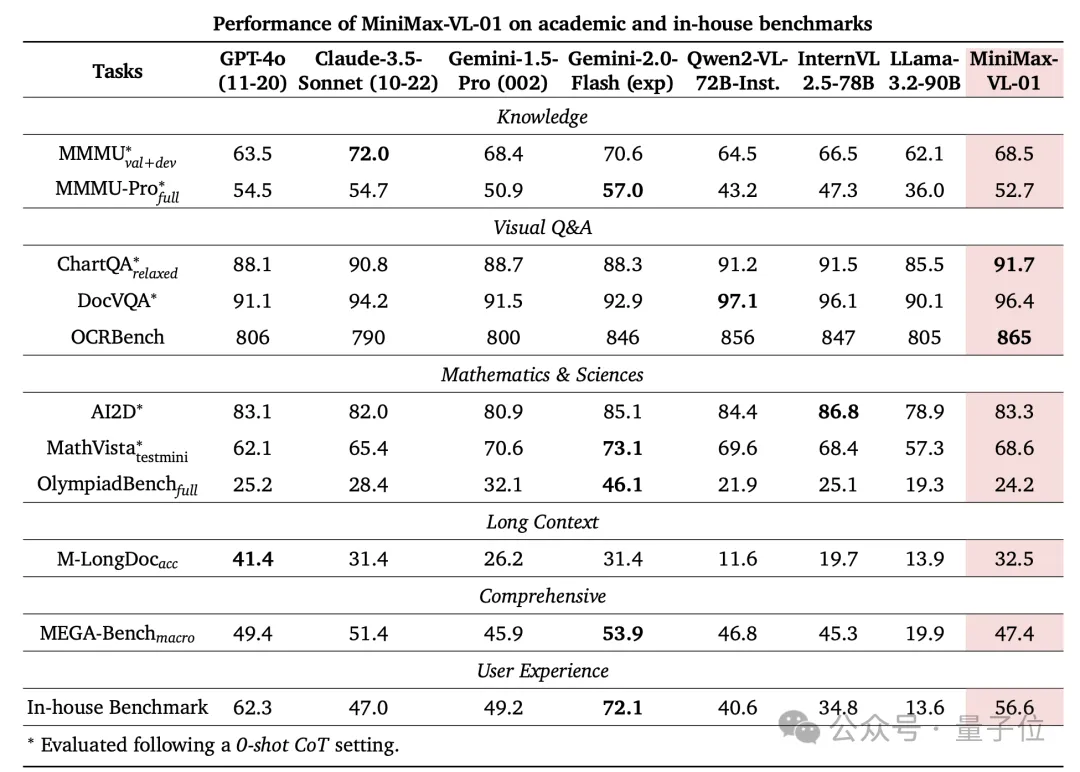
最终,MiniMax-VL-01 在多模态排行榜上表现突出,证明了其在处理复杂多模态任务中的优势和可靠性。
网友们已开始第一波实测
得知新模型已在Hailuo AI上部署,网友们已紧忙赶往测试。

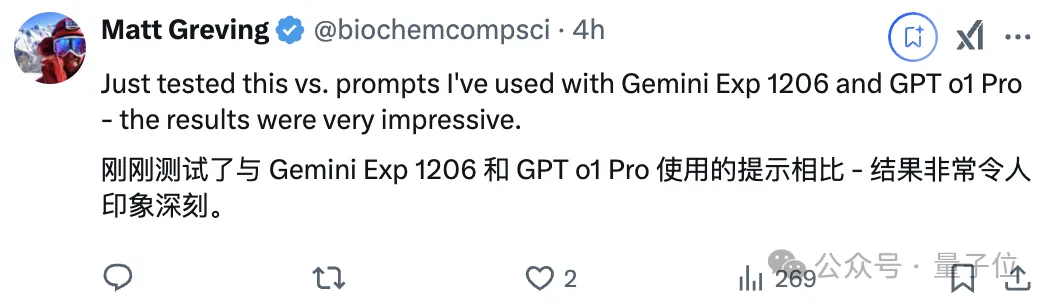
有网友使用相同的prompt将它和Gemini、o1对比,感叹MiniMax-01表现令人印象深刻。
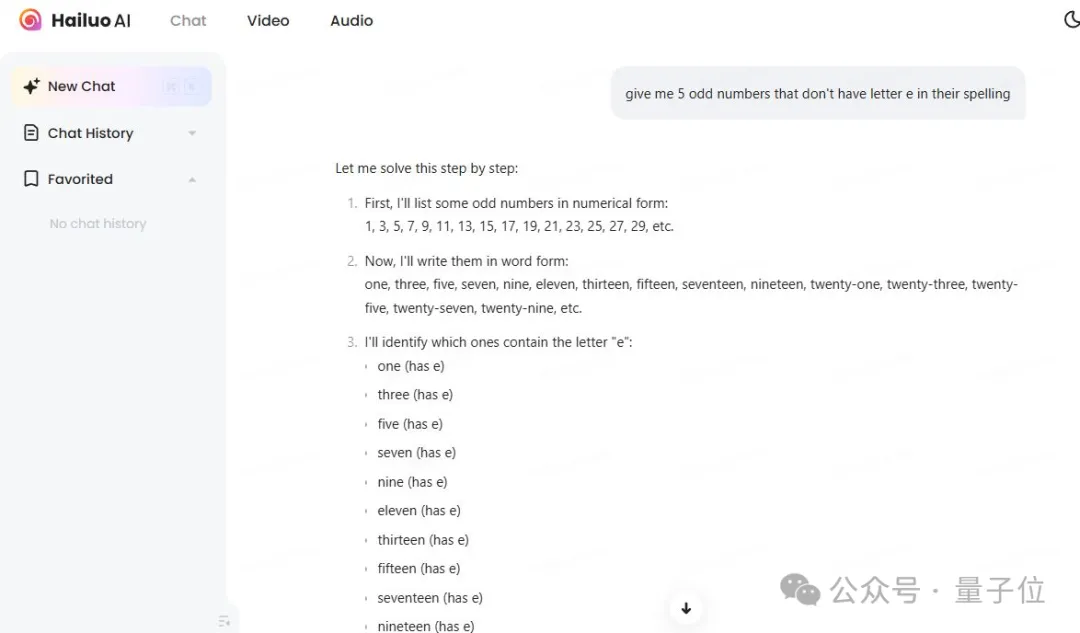
下面这个测试也没能难倒它:
给我5个奇数,这些数的英文拼写中不包含字母“e”。
感兴趣的童鞋可以玩起来了。
技术论文:https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf
参考链接:
[1]https://x.com/MiniMax__AI/status/1879226391352549451
[2]https://huggingface.co/MiniMaxAI/MiniMax-Text-01
[3]https://huggingface.co/MiniMaxAI/MiniMax-VL-01
- 又一开源AI神器!将机器学习论文自动转为可运行代码库2025-05-01
- 一次示范就能终身掌握!让手机AI轻松搞定复杂操作丨浙大&vivo出品2025-05-01
- AI卧底美国贴吧4个月“洗脑”100+用户无人察觉,苏黎世大学秘密实验引争议,马斯克惊呼2025-04-30
- 全网首测!Qwen3 vs Deepseek-R1数据分析哪家强?2025-04-30