Ilya宣判后GPT-5被曝屡训屡败,一次训数月,数据要人工从头构建
OpenAI已经在调整战略了
明敏 克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
GPT-5被曝效果远不达预期。
OpenAI连续12场发布会刚刚结束,大家最想看的GPT-5/4.5影子都没有,于是华尔街日报这边爆料了。
- GPT-5已至少完成2轮训练,每次长达数月,但是每次训练后都遇到新问题。
- OpenAI正在专门雇人写代码、做数学题为GPT-5从头创建数据,o1合成数据也用,但效率不够高,想要满足GPT-5的预训练需求有难度。

按照市场估算,一次长达6个月的训练仅计算就需要花费5亿美金。GPT-5两次训练进展都不顺,背后的成本想必也是个天文数字。
Ilya前不久在NeurIPS 2024上宣判的预训练即将终结,似乎再次得到论证……
这也和The Information此前爆料相呼应,随着GPT系列进化速度放缓,OpenAI正在尝试调整战略,比如o1、o3系列的推出。
目前,OpenAI对最新爆料尚无回应。
但GPT-5究竟是OpenAI藏着不发,还是不能发?答案更确定了一点。
巨量数据算力堆不好GPT-5的预训练
在华尔街日报的爆料中,OpenAI对于GPT-5的预期很高。
它能够进行科学探索发现,并完成例行的人类任务,比如预约、订航班。而且希望它能够犯更少的错误,或者能够承认错误存在,也就是减少幻觉。
这与更早透露出的信息相呼应。OpenAI前CTO Mira曾形象地将GPT-5的智能水平比作博士生。
这意味着GPT-5能够在某些特定领域取得高水平成绩,能像研究生、博士那样可以深刻理解、推理,并具备专业知识。对比来看,GPT-3是蹒跚学步的孩子,GPT-4是高中生。
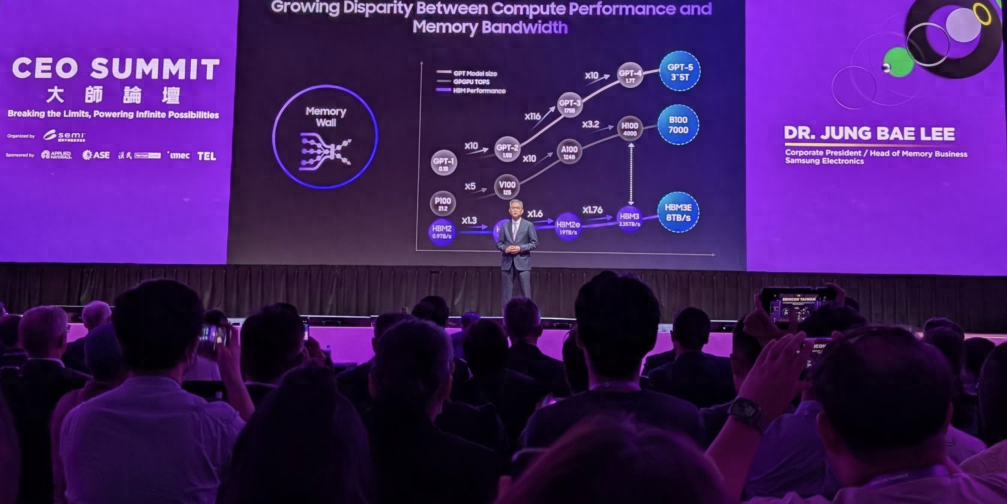
今年10月,OpenAI最新筹集到的66亿美元融资,估值飙升到1570亿美元。投资者的再一次加码,也被认为是因为相信GPT-5将能完成重大飞跃。
但是GPT-5的发布一直悬而未决。
奥特曼之前表示,GPT-5不会有明确的发布时间,等什么时候准备好了,就什么时候发。这个时间可能是2025,也可能是2026。

如今回溯来看,GPT-5的推出一直都坎坷不断。
在2023年,OpenAI被曝光放弃了一个代号为Arrakis的模型。放弃原因是该模型不能实现在保持性能的同时减少对计算资源的需求,没有达到预期的训练效率。
这其实反向证明,如果想要训练规模更大规模的模型,还是需要更庞大的计算资源、更长的时间。
从设定来看,GPT-5显然会是个“巨无霸”。
GPT-5的开发启动于GPT-4发布时。至今已经超过18个月了。
它在内部的代号是猎户座Orion。按照原本计划,微软是想在2024年年中看到GPT-5的。
华尔街日报披露,GPT-5的大规模训练至少进行了2轮。每次都需要几个月,每次也都遇到了新问题。
最好的情况下,Orion比OpenAI目前的产品表现都要好。但与所消耗的成本相比,这种提升并不明显。
据估测,一次为期6个月的训练仅算力成本就要消耗5亿美元。对比来看,GPT-4的训练成本超1亿美元。

另一方面,想要更好的模型,就需要更多的数据。
公共资源的数据消耗殆尽,OpenAI决定雇人从头构建数据。据爆料,它专门找了一些软件工程师、数学家来写代码、解数学题,供GPT-5学习。
一直以来,AI圈内都认为模型学习代码可以提升它解决其他问题的能力。
同时OpenAI也和一些物理学家合作,让GPT-5学习科学家如何理解领域内的问题。
但问题就是,这样太慢了。
AI合成数据的路子OpenAI也走。据说GPT-5就使用了o1合成的数据。
这种范式可能已经可以被论证。
隔壁Anthropic也被爆料使用AI合成数据训练模型。他们的做法是把最好用的模型内部自留合成数据,因为模型性能与合成数据质量直接成正比。

以上,大概就是GPT-5最新相关信息。
不过话说回来,最近谁还在乎GPT-5呢(手动狗头)?

毕竟OpenAI凭借o1、o3系列开启了推理Scaling Law。
刚刚发布的o3在ARC-AGI上刷新成绩。最新结果报告显示,在400项公共任务上,o3的最好成绩已经达到91.5%。
在核心机制上,o3也给出新启发。它通过LLM在token空间内搜索和执行,实现了在测试时内的知识重组。
随着o3系列发布,AGI的预言依旧很有吸引力。
o3屠榜ARC-AGI测试,离AGI还有多远?
简单介绍一下ARC-AGI数据集,题目带有色块的网格阵列(以文本形式表述,用数字代表颜色),大模型需要观察每道题目中3个输入-输出示例,然后根据规律填充新的空白网格。
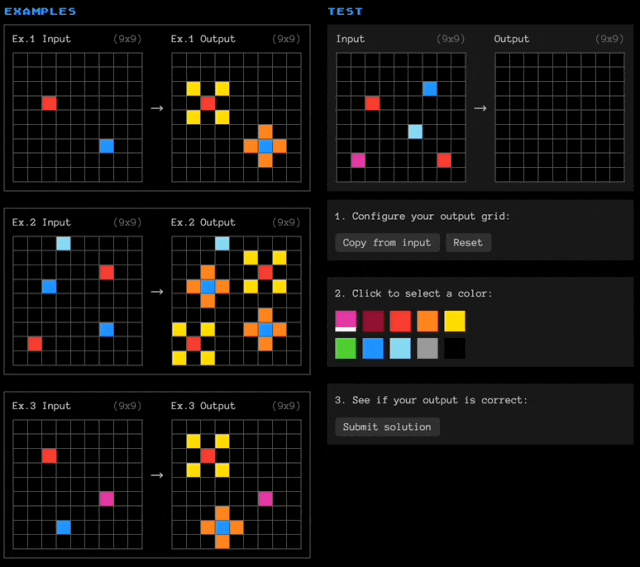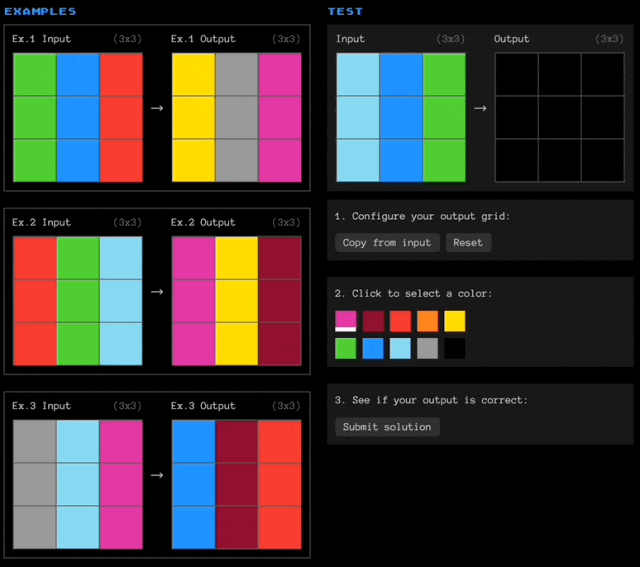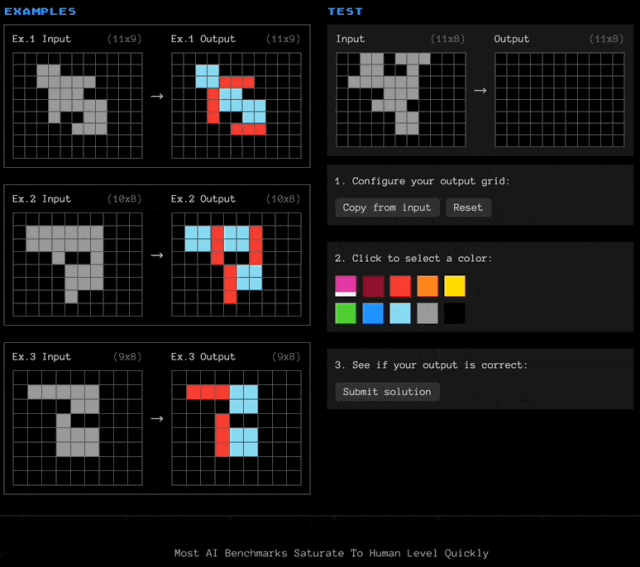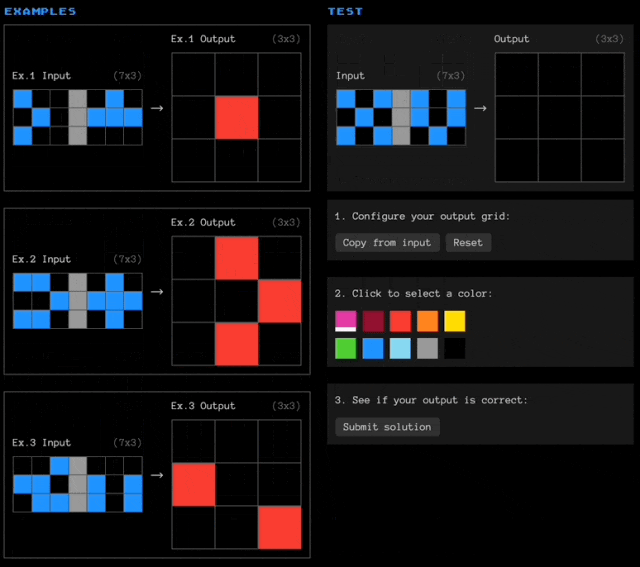
这几个示例比较简单,但实际面临的问题可能是这样的:
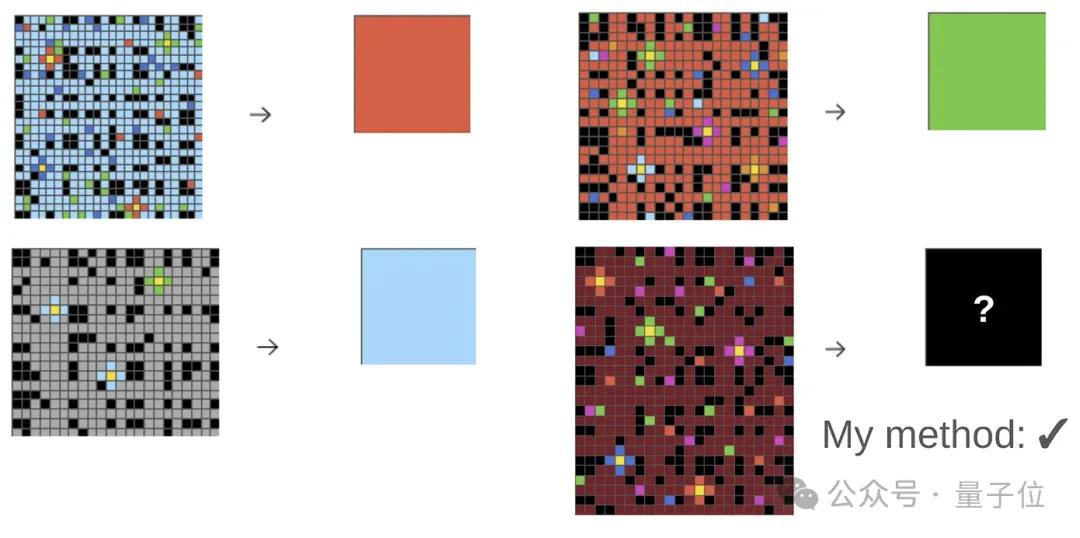
ARC-AGI测试集一共包含400道公开试题和100个私有问题。
在公开问题中,o3高效率版的准确率为82.8%,消耗了1.11亿Token,平均每个任务成本为17美元。
低效率版本(计算量是高效版的172倍),准确率高达91.5%,不过消耗的Token数也达到了惊人的95亿。
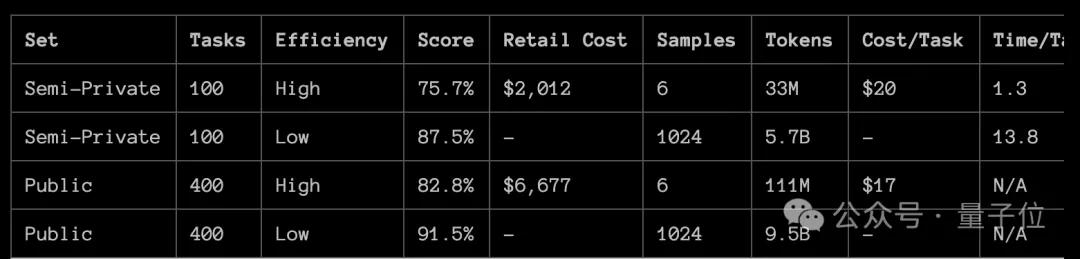
另外OpenAI还做了一个专门针对ARC-AGI的版本,使用了75%的公开数据集进行了训练。
这个版本拿到私有测试集上测试,结果地计算量模式取得了76%的准确率,高计算量模式则为88%。
并且,低计算量版本的成本在ARC-AGI-Pub的规则范围内(<$10k),成为了公共排行榜上的第一名。
88%的高计算量版本则过于昂贵,但仍然表明新任务的性能确实随着计算量的增加而提高。
在此之前,GPT-3的准确率是零,GPT-4o为5%,o1最好也刚刚超过30%。
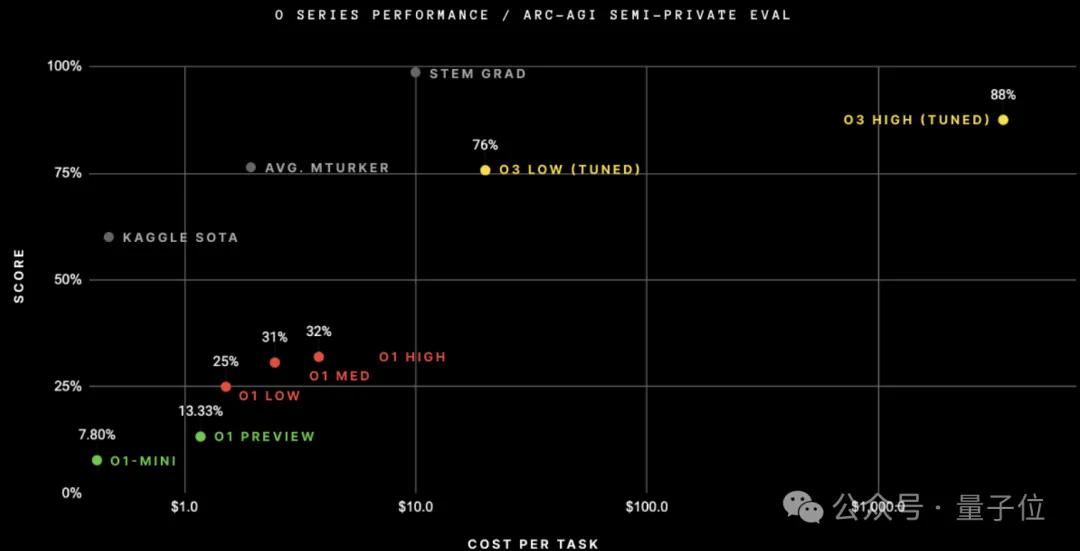
ARC挑战的发起者之一、前谷歌资深工程师、Keras之父François Chollet认为,o3能够适应以前从未遇到过的任务,可以说在ARC-AGI领域接近人类水平。
当然成本也十分昂贵,即使是低计算量模式,每个任务也需要17-20美元,而发起方雇佣真人解决此类问题的成本,平均到每个问题只有5美元。
但抛开成本问题,Chollet指出,o3对GPT系列的改进证明了架构的重要性,认为无法在GPT-4上通过投入更多计算来获得这样的成绩。
所以,通过ARC-AGI测试,意味着o3实现AGI了吗?Chollet认为并不是。
通过测试发现,o3在一些非常简单的任务上仍然失败,这表明其与人类智能存在根本差异。
另外,ARC-AGI的下一代ARC-AGI-2也即将推出,早期测试表明其将对o3构成重大挑战,即使在高计算量模式下,其得分也可能会降低到30%以下(而聪明人仍然能够得分超过95%)。
但无论是否达到AGI,o3能够实现的成绩都是前所未有的,甚至有人认为,针对ARC这样的任务而言,人类的优势其实是在于视觉推理,如果改成像模型看到的那样用文本形式描述图形,那人类做的不一定会比AI好。
并且,针对o3“没能成功”的一个案例,还有人质疑是标准答案错了。
这道题当中,变化规律是将处于同一行或列的两个蓝色格子连成线,并把穿过的红色区域整块涂蓝。
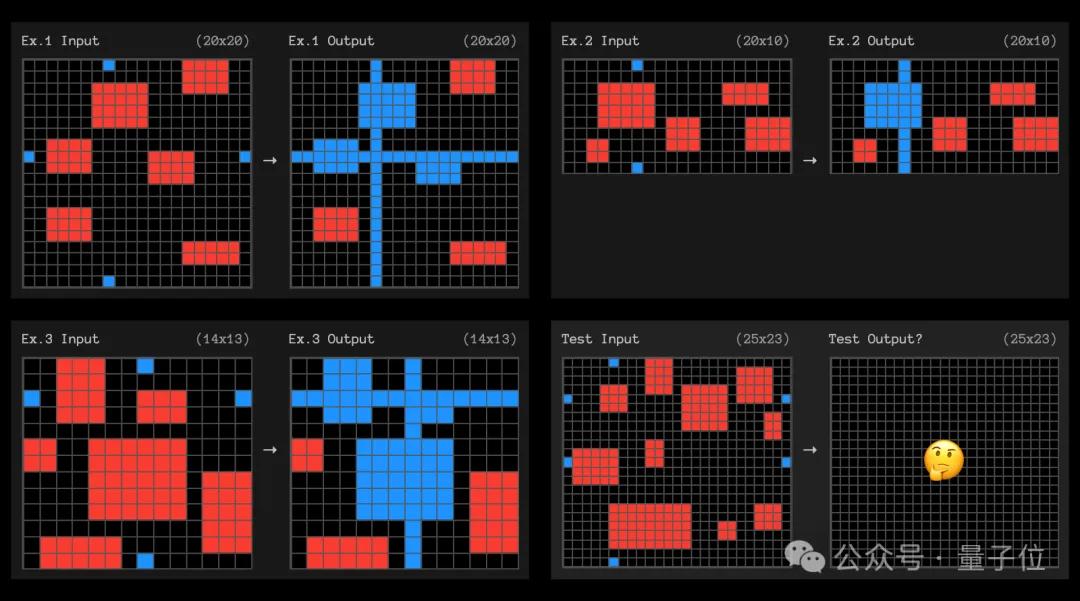
这道题的“标准答案”和o3的尝试,区别就是绿色框中的部分是否被涂成蓝色:
在三个示例当中,由红变蓝的部分都是被连线从中间穿过,但在这道题中连线是从这个3×4的红色区域下方经过,o3因此认为不该把这块区域涂蓝。

那么,o3又是怎么实现的呢?
有人认为是通过提示词,但ARC挑战负责人Greg Kamradt和OpenAI的研究人员Brandon McKinzie均否认了这一说法,表示给o3的提示词非常简单。
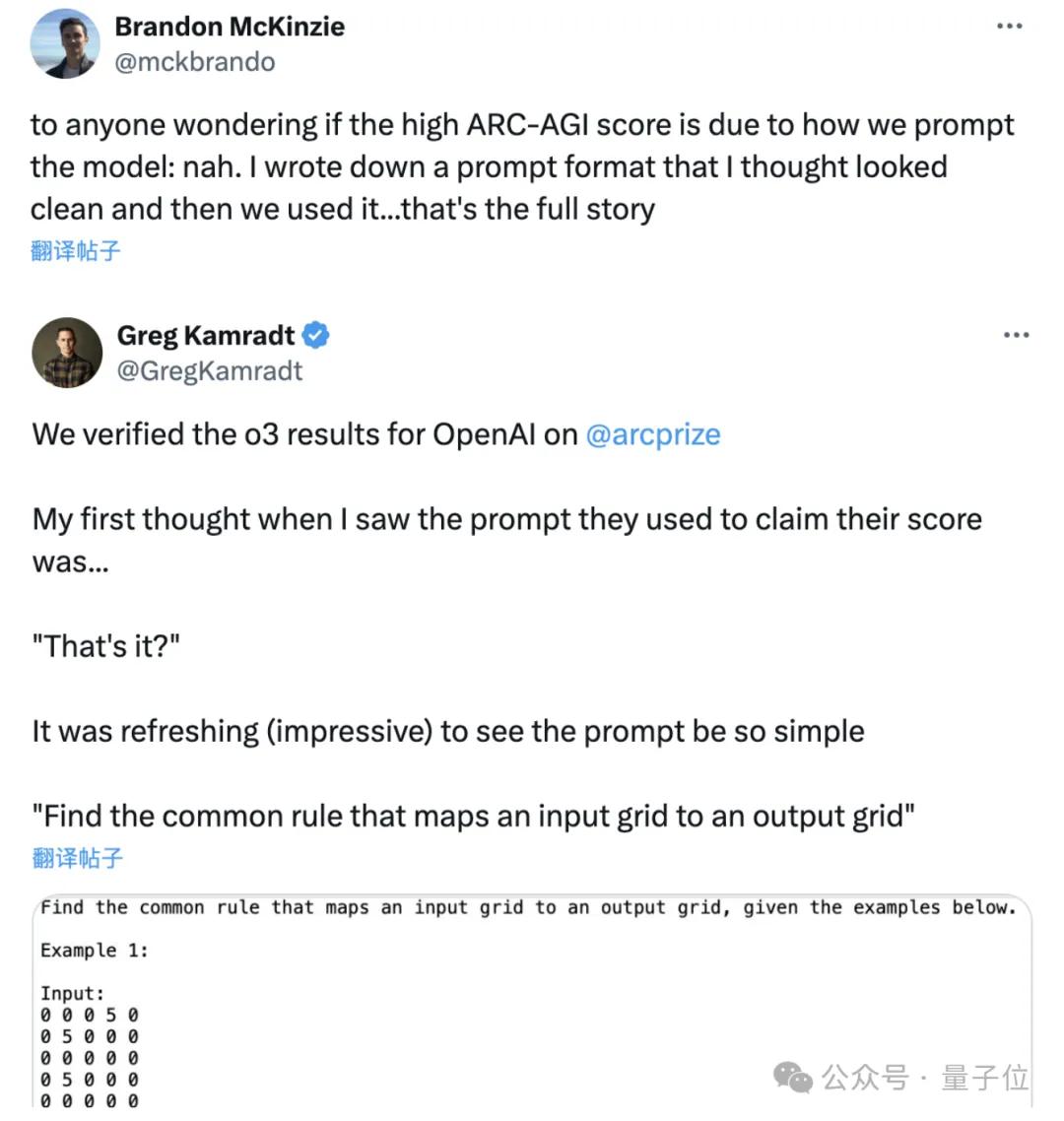
另外Chollet推测,o3的核心机制似乎是在Token空间内搜索和执行自然语言程序——在某种评估器模型引导下,搜索可能的描述解决任务所需的步骤的思维链空间。
按照Chollet的观点,o3实现了在测试时的知识重组,总之,o3构建出了一种通向AGI的新的范式。
英伟达AI科学家范麟熙(Jim Fan)认为,o3的本质是“放松单点RL超级智能,以覆盖有用问题空间中的更多点”。
也就是用深度换取广度,放松对于个别任务的强化学习,换得在更多任务上的通用性。
范麟熙举例说,像AlphaGo、波士顿动力电子地图集都是超级人工智能,在特定的任务上表现非常出色。
但o3不再是像这样只能应付单点任务的专家,而是一个在更大的有用任务集都表现优异的专家。
不过范麟熙也表示,o3仍然无法涵盖人类认知的所有分布,我们仍然处于莫拉维克悖论之中。
(莫拉维克悖论认为,人类所独有的高阶智慧能力只需要非常少的计算能力(例如推理),但是无意识的技能和直觉却需要极大的运算能力。)
ARC挑战发起方的发现——o3在一些非常简单的任务上失败,似乎刚好印证了这一观点。
最后,关于AGI,范麟熙表示,我们已经实现了巨大的里程碑,并且有清晰的路线图,但还有更多事情要做。

One More Thing
作为12天发布的一部分,OpenAI在最后一天发布o3的同时,也发了一篇关于安全问题的论文。
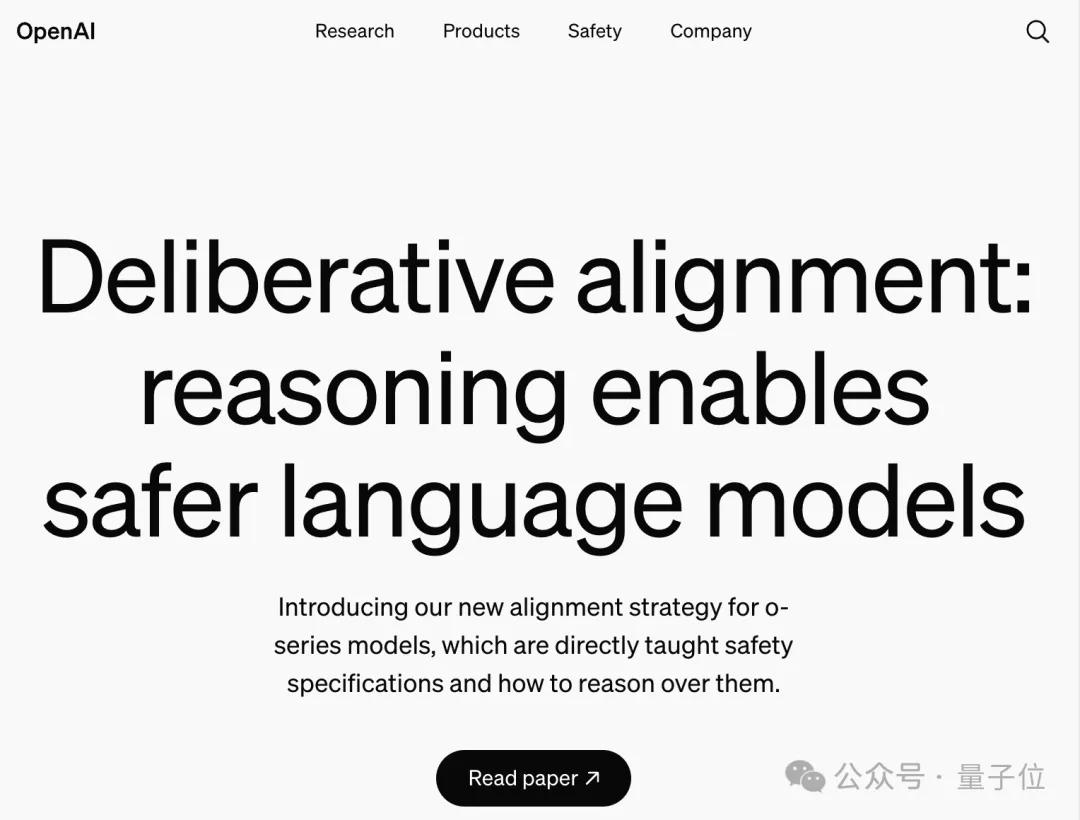
论文引入了一种名为慎重对齐(deliberative alignment)的对齐方式,直接向推理模型传授人工编写、可解释的安全规范,并训练他们在回答之前对这些规范进行明确的推理。
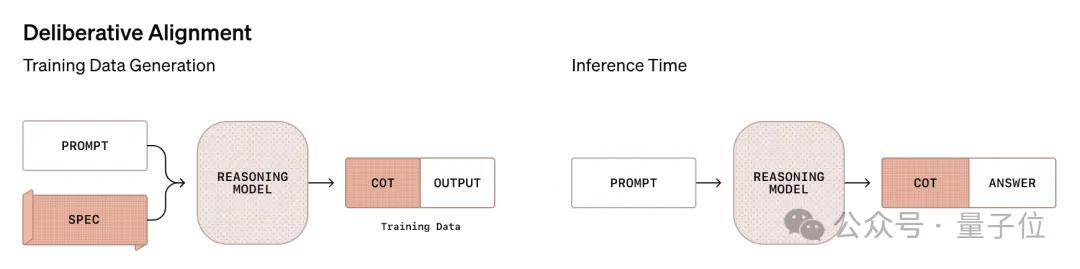
结果,训练出的模型不需要人工标记的CoT或答案,就可以高度精确地遵守OpenAI的安全政策。
OpenAI发现,o1在一系列内部和外部安全基准方面显著优于GPT-4o等其他最先进模型 ,并且在许多具有挑战性的(安全)数据集上的性能达到饱和。
这一发现,揭示了推理将成为提高模型安全性的一条新途径。
参考链接:
[1]https://www.wsj.com/tech/ai/openai-gpt5-orion-delays-639e7693?st=ng5hBi
[2]https://x.com/mckbrando/status/1870285050555810198
[3]https://x.com/DrJimFan/status/1870542485023584334
[4]https://arcprize.org/blog/oai-o3-pub-breakthrough
- Git诞生20周年!大佬Linus十天写出的项目,彻底变革全球软件开发2025-04-08
- AIGC第一股年报详解:AIGC业务暴涨88.5%营收2.2亿,95%智能硬件交付出海,跑通规模化「软件订阅+出海」2025-03-30
- 面壁发布首个纯端侧智能助手,构建汽车超性能端侧大脑2025-03-30
- AI战略锁定增长确定性,粉笔2024年净利润2.4亿元2025-03-28