1行代码改进大模型训练,Llama训练速度升至1.47倍,华人团队出品
避免训练过程中损失回升
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
只要改一行代码,就能让大模型训练效率提升至1.47倍。

拥有得州大学奥斯汀分校背景四名华人学者,提出了大模型训练优化器Cautious Optimizers。
在提速的同时,Cautious能够保证训练效果不出现损失,而且语言和视觉模型都适用。
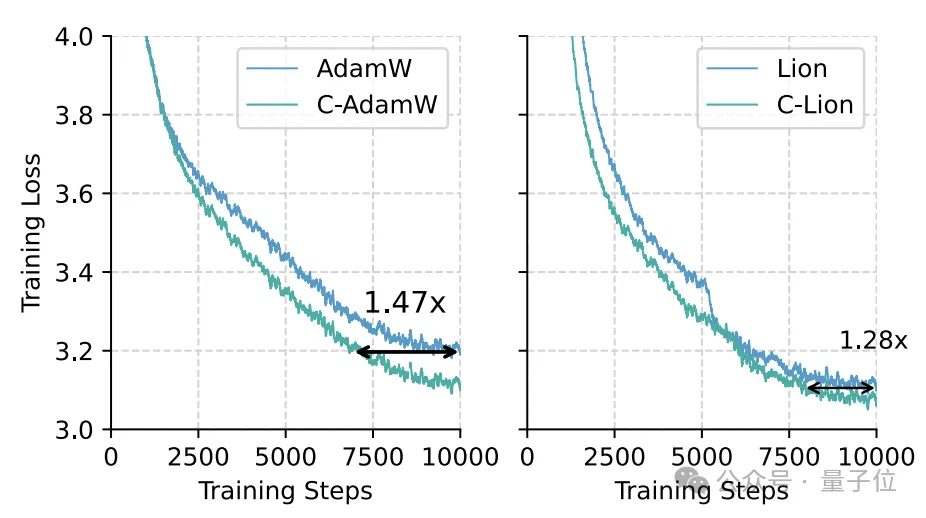
该优化器以哈密顿量和下降动力学为理论基础,在加速的同时不影响收敛特性。
作者在600M到1B不同参数规模的Llama模型上进行了试验,获得了最高47%的加速率。
该研究相关代码已经开源,在GitHub上有使用方法的详细讲解。
一行代码改进大模型训练
Cautious Optimizers在PyTorch当中增加的一行代码,核心思路是引入实现一种掩蔽机制,从而避免参数更新的方向与当前梯度方向相悖。

因为这两个方向一旦不一致,就有可能导致损失函数暂时增加,造成收敛速度的减缓。
不过作者并未在方向不一致的来源问题上过度纠结,而是引入了一种判断机制,在参数更新之前增加一步计算,从而过滤掉方向不一致的情形。
这也正是上面代码的直接作用。
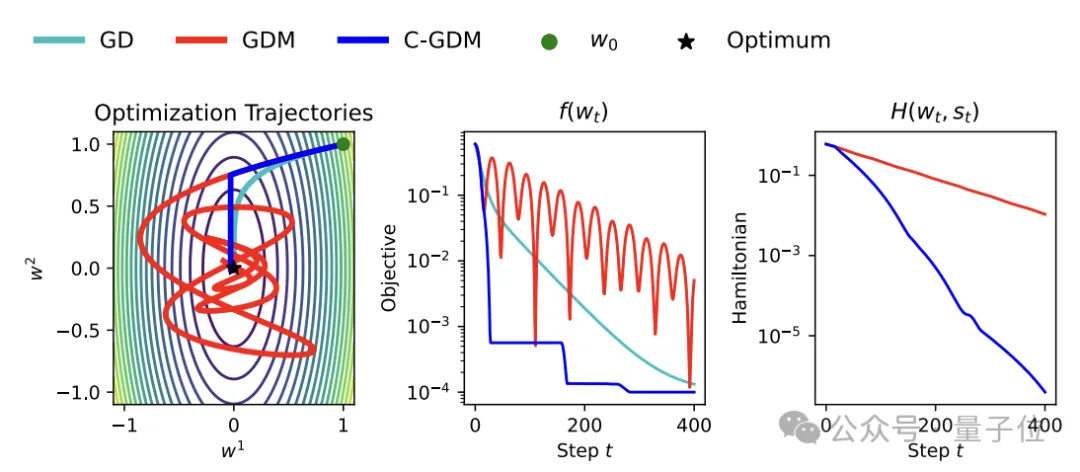 △GD:梯度下降,GDM:带动量的梯度下降,C-GDM:本项目
△GD:梯度下降,GDM:带动量的梯度下降,C-GDM:本项目具体来说,加入的两行代会对u和g两个向量求内积,u向量对应优化器给出的参数更新方向,而g向量对应当前时刻的梯度方向。
作者设计了一个对齐掩码函数ϕ,当u和g的内积小于0时(即方向不一致),ϕ的输出为0向量;当内积大于等于0时,ϕ的输出为全1向量。
而一旦ϕ为零向量时,w_t计算式中含u的项也会变为零向量,导致此项更新被跳过。

这样就可以判断参数更新和梯度方向是否一致,如果不一致则不会用于参数更新,避免了训练过程中损失函数的回升。
训练效率提升47%
为了评估Cautious Optimizers的具体效果,作者分别在语言模型Llama和视觉模型MAE上进行了试验。
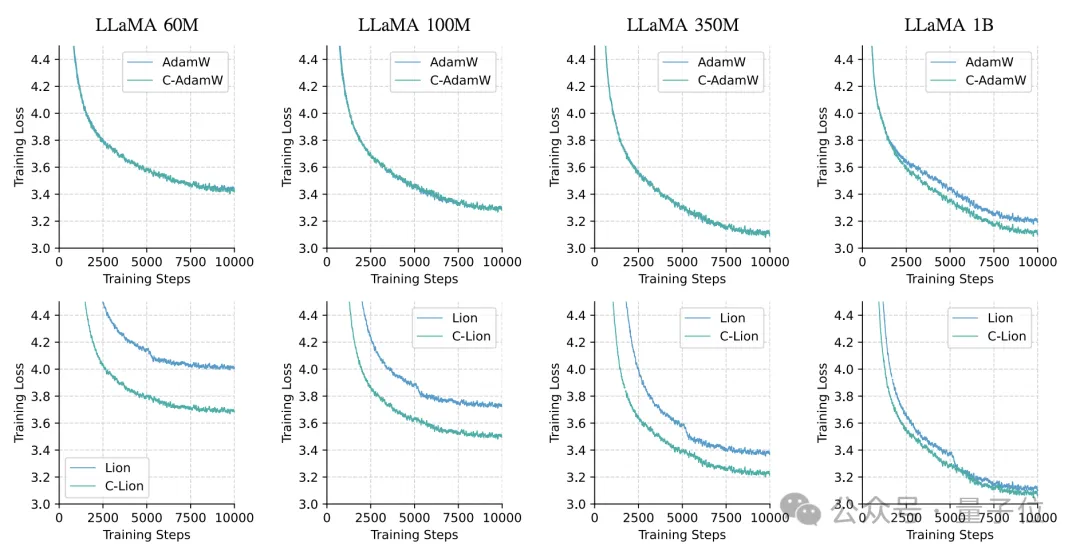
作者选取了60M、100M、350M和1B四种参数规模的Llama模型,在C4语料库上进行预训练。
优化器选用了AdamW和Lion,以及它们对应的Cautious版本:C-AdamW和C-Lion,每个实验中进行1万步迭代。
结果C-AdamW和C-Lion在所有规模上都表现出明显的收敛加速效果。
尤其是在1B规模上,相比原版的AdamW和Lion,它们的样本效率分别提高了47%和28%,这表明Cautious Optimizer能有效减少训练震荡,使收敛更平稳高效。
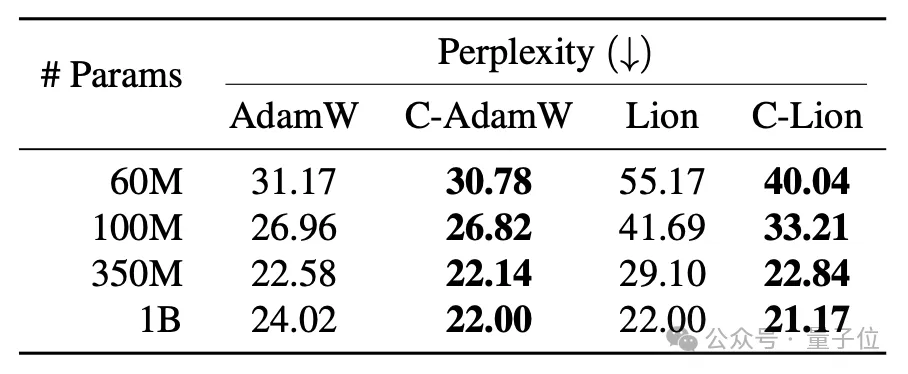
并且,Cautious Optimizer在所有情况下都取得了更低的困惑度,印证了其出色的泛化性能。
为了评估模型的实际效果,研究者在语句匹配、文本蕴含、情感分类等6个GLUE下游任务上测试了AdamW和C-AdamW优化后1B模型的表现,
结果表明,C-AdamW的平均得分比AdamW高出2%,在大多数任务上都取得了进步,说明Cautious跳过部分参数更新的方式不会引起模型性能下降。

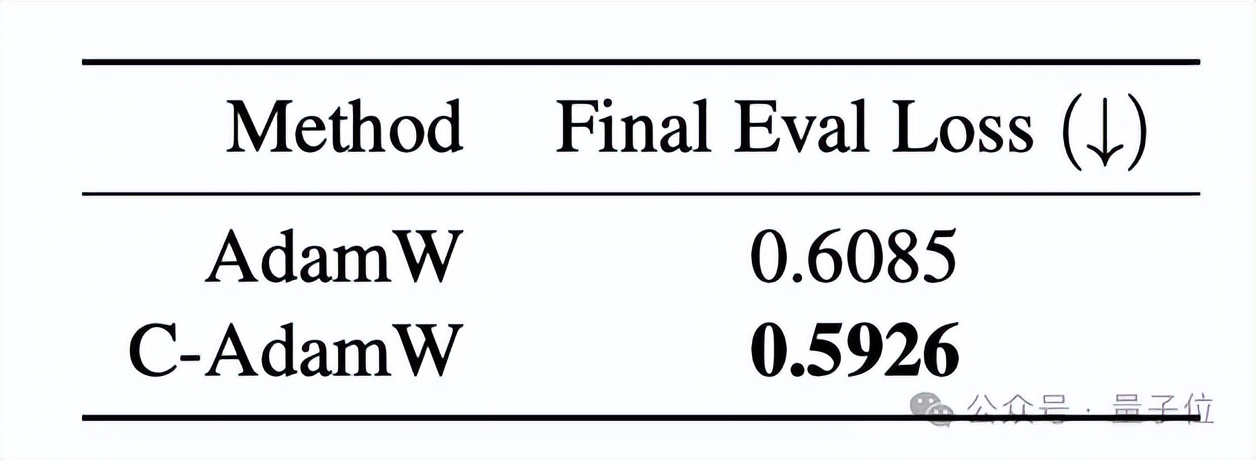
对于视觉模型,作者以ViT为骨干网络,在ImageNet-1K数据集上预训练了MAE模型。
由于视觉任务的特殊性,训练过程采用了随机遮挡图像块并重建的范式,因此优化目标是最小化重建误差,而非通常的分类损失。
作者对比了AdamW和C-AdamW的表现,即训练50轮后的最终重建误差,结果C-AdamW的误差为0.5926,低于AdamW的0.6085。
一作曾在一周内复刻o1
本项目是由四名华人学者共同打造的。
第一作者Kaizhao Liang,是AI推理加速服务商SambaNova公司的一名高级ML工程师。
在o1模型发布一周内,该公司就推出了一个类似o1模型思考过程的开源平替,主要作者正是Liang。

其他三名作者是得州大学奥斯汀分校CS助理教授Qiang Liu,以及他的两名博士生,Lizhang Chen和Bo Liu。
此外,Liang的人工智能硕士学位也是从该校获得。
论文地址:
https://arxiv.org/abs/2411.16085
GitHub:
https://github.com/kyleliang919/C-Optim
- 马斯克擎天柱机器人大秀走姿,背后大佬集体现身喊话招人2025-04-03
- AI Agent来,传统BI危2025-03-28
- Claude团队开盒Transformer:AI大脑原来这样工作2025-03-28
- 7499拿下纯血鸿蒙+DeepSeek,华为“小宽折叠”手机:帮接电话,眼动翻页2025-03-20