空间智能新进展:教机器人组装宜家家具,首次实现操作步骤与真实视频对齐 | NeurIPS
涵盖1120个子步骤
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
斯坦福吴佳俊团队,给机器人设计了一套组装宜家家具的视频教程!
具体来说,团队提出了用于机器人的大型多模态数据集IKEA Video Manuals,已入选NeurIPS。
数据集涵盖了6大类IKEA家具,每种家具都包含完整的3D模型、组装说明书和实际组装视频。
而且划分精细,拆解出的安装子步骤多达1000多个。

作者介绍,该数据集首次实现了组装指令在真实场景中的4D对齐,为研究这一复杂问题提供了重要基准。
知名科技博主、前微软策略研究者Robert Scoble说,有了这个数据集,机器人将可以学会自己组装家具。

团队成员、斯坦福访问学者李曼玲(Manling Li)表示,这是空间智能领域的一项重要工作:
这项工作将组装规划从2D推进到3D空间,通过理解底层视觉细节,解决了空间智能研究中的一个主要瓶颈。

1120个子步骤详述组装过程
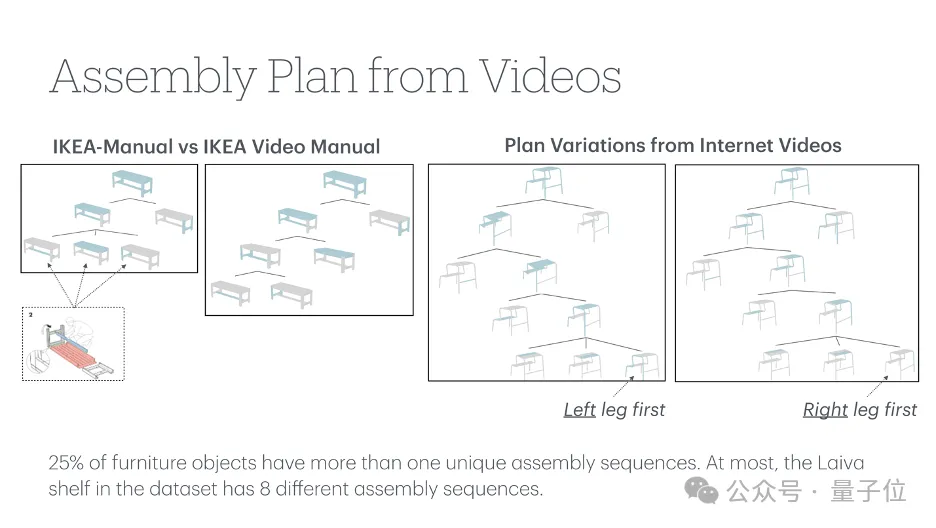
IKEA Video Manuals数据集中,涵盖了6大类36种IKEA家具,从简单的凳子到复杂的柜子,呈现了不同难度的组装任务。

每一款家具,都包括以下三种模态:
- 安装说明书,提供了任务的整体分解和关键步骤;
- 真实组装视频,展示了详细的组装过程;
- 3D模型,定义了部件之间的精确空间关系。
并且这三种模态并非简单地堆砌在一起,作者通过对视频和操作步骤的拆解,将三种模态进行了精细的对齐。
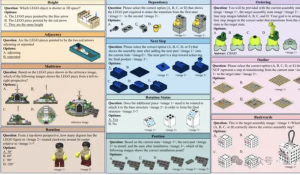
举个例子,在这样一条关于长凳的数据当中,包含了其基本概况、视频信息、关键帧信息,以及安装步骤。
从下图中可以看出,安装步骤当中有主要步骤和子步骤的划分,还标注了对应的视频位置。
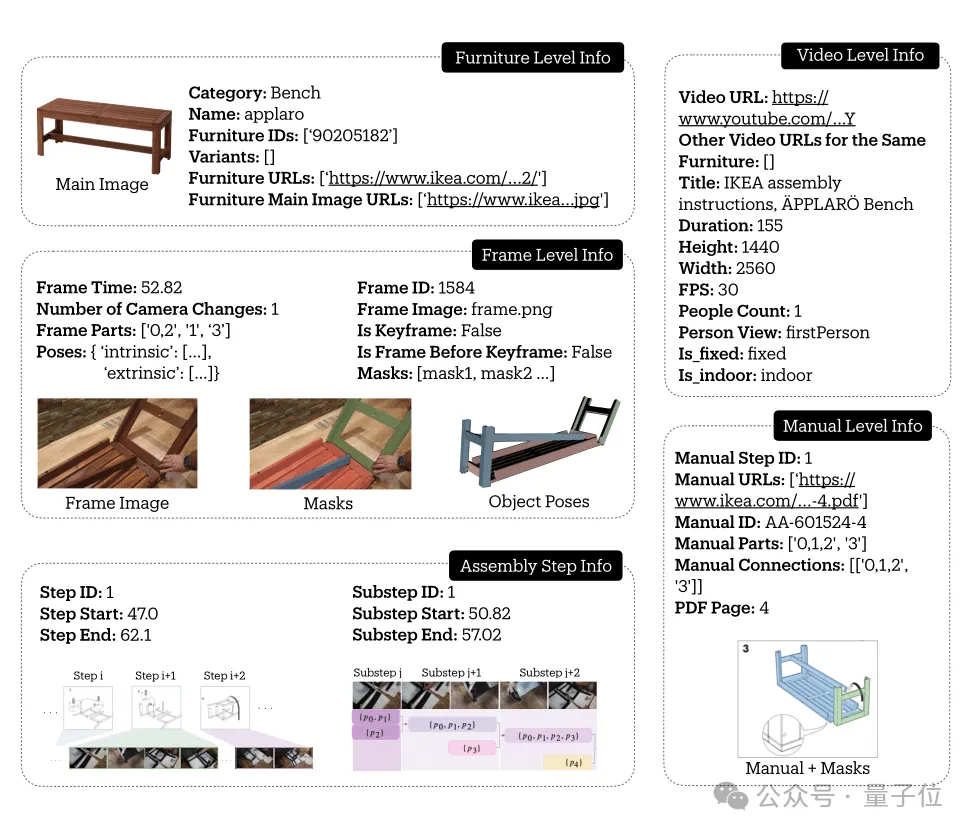
整个数据集中,共包含了137个手册步骤,根据安装视频被细分为了1120个具体子步骤,捕捉了完整的组装过程。
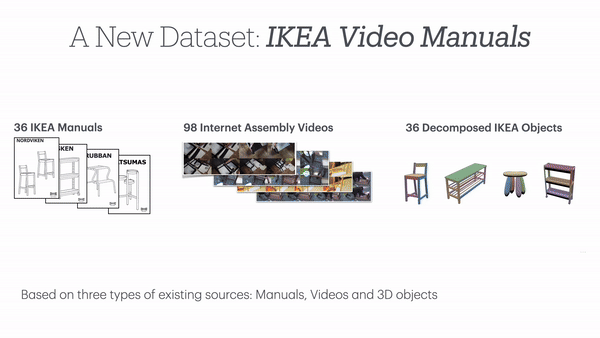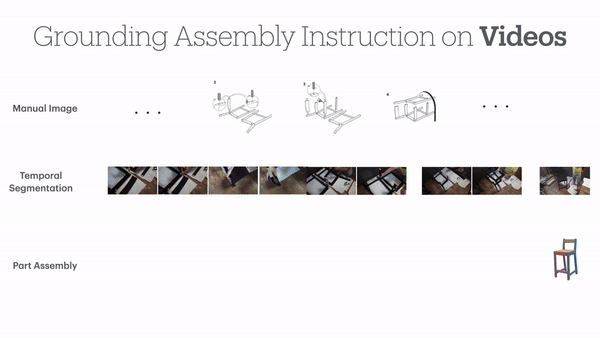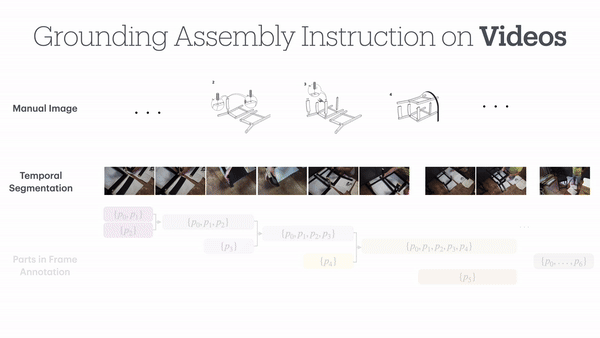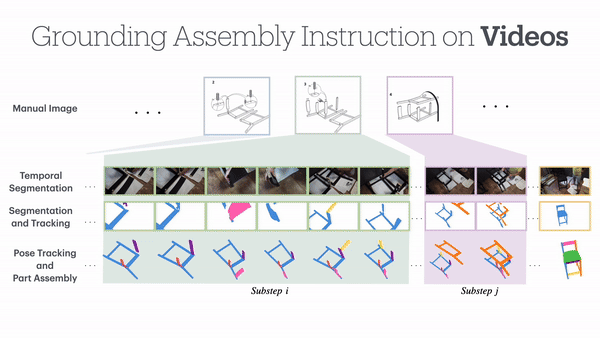
并且通过6D Pose追踪,每个部件的空间轨迹都被精确记录,最终在视频帧、家具组装说明书和3D模型之间建立了密集的对应关系。
时空信息精细标注
IKEA Video Manuals数据集是在IKEA-Manual和IKEA Assembly in the Wild(IAW)两个数据集的基础上建立的。
其中,IKEA-Manual数据集提供了模型及其对应说明书,IAW则包含了大量用户组装宜家家具的视频片段。
这些视频来自90多个不同的环境,包括室内外场景、不同光照条件,真实反映了家具组装的多样性。

与在实验室环境下采集的数据相比,这些真实视频带来了更丰富的挑战:
- 部件经常被手或其他物体遮挡;
- 相似部件识别(如四条一模一样的桌子腿);
- 摄像机频繁移动、变焦,带来参数估计的困难;
- 室内外场景、不同光照条件下的多样性。

为了获得高质量的标注,应对真实视频带来的挑战,研究团队建立了一套可靠的标注系统:
- 识别并标注相机参数变化的关键帧,确保片段内的一致性;
- 结合2D-3D对应点和RANSAC算法进行相机参数估计;
- 通过多视角验证和时序约束保证标注质量。
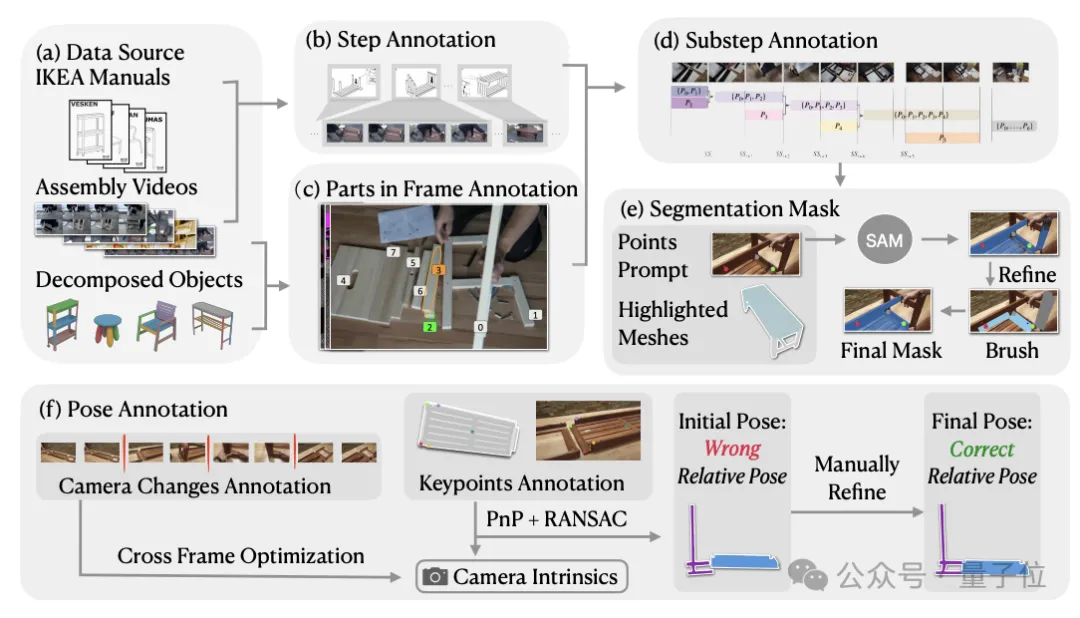
首先,研究者们首先定义了一套层次化的装配过程描述框架,将整个装配过程分为步骤、子步骤和视频帧等多个层级。
作者首先从IAW数据集中提取每个手动步骤的视频片段,并将每个视频片段分解为更小的间隔(子步骤)。
对于每个子步骤,作者以1FPS的速度采样视频帧,并在每个子步骤的第一帧中标注出家具部件。
为了在整个组装视频中对家具部件进行跟踪,作者还在采样帧中为3D部件注释了2D图像分割掩码。
为了促进注释过程,研究团队开发了一个显示辅助2D和3D信息的Web界面,同时该界面还可基于Segment Anything Model(SAM)模型进行交互式掩码注释。

标注过程中,标注人员会在3D模型上选中零件,然后在2D视频帧上指示其大致位置,并将其输入到SAM模型中以实时生成2D分割掩码。
为了解决SAM在提取具有相似纹理的部分之间或低光区域的边界方面的固有局限,作者还允许标注人员使用画笔和橡皮擦工具进行手动调整。
此外,作者还要估计视频中的相机参数,为此研究者们首先人工标记出视频帧中可能出现相机运动(如焦距变化、切换视角等)的位置,然后标注出视频帧和3D模型之间的2D-3D对应关键点。
最后,结合这两类标注信息,研究者们使用PnP (Perspective-n-Point)算法估计出每段视频的相机内参数,得到相机参数的初始估计后,利用交互式工具来细化每个视频帧中零件的6D姿态。
空间模型能力评估
基于IKEA Video Manuals数据集,团队设计了多个核心任务来评估当前AI系统在理解和执行家具组装,以及空间推理(spatial reasoning)方面的能力。
首先是基于3D模型的分割(Segmentation)与姿态估计 (Pose Estimation)。
此类任务输入3D模型和视频帧,要求AI准确分割出特定部件区域,并估计其在视频中的6自由度姿态。
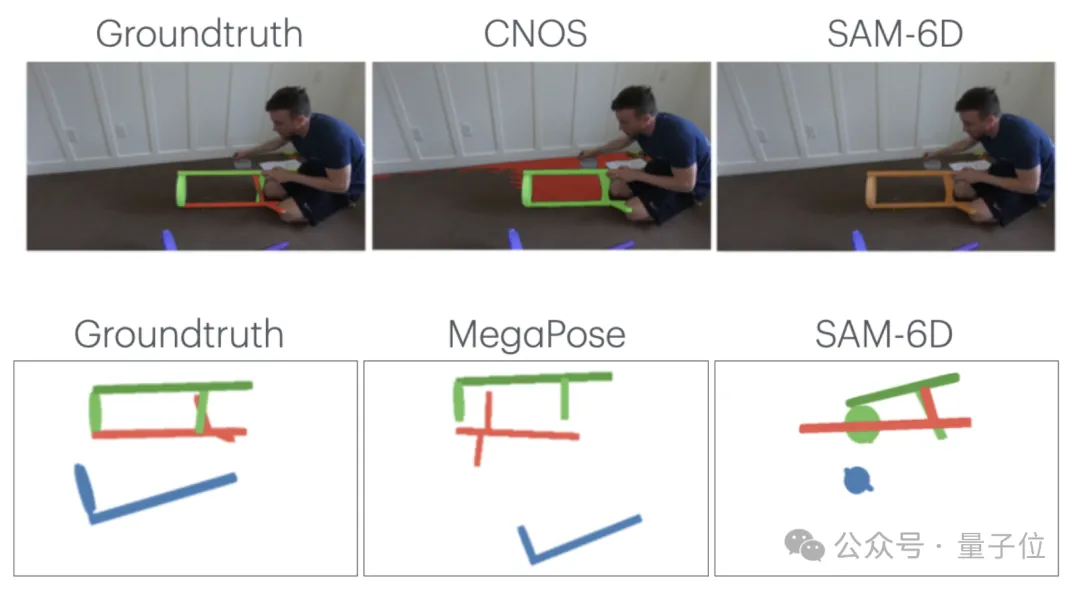
△上:基于3D模型的分割,下:基于3D模型的姿态估计
实验测试了最新的分割模型(CNOS, SAM-6D)和姿态估计模型(MegaPose)。
分析发现,它们在以下场景表现不佳:
- 遮挡问题:手部遮挡、近距离拍摄导致部分可见、遮挡引起的深度估计误差;
- 特征缺失:缺乏纹理的部件难以分割、对称部件的方向难以判断;
- 特殊拍摄角度(如俯视)导致的尺度误判。

△上:遮挡问题,左下:特征缺失,右下:特殊角度
第二类任务是视频目标分割,作者对比测试了两个最新的视频追踪模型SAM2和Cutie。
结果显示,在真实组装场景中,这些模型同样面临着三大挑战。
一是相机的运动,可能导致目标丢失。

二是难以区分外观相似的部件(如多个相同的桌腿)。

最后,保持长时间追踪的准确度也存在一定难度。
第三类任务,是基于视频的形状组装。
团队提出了一个创新的组装系统,包含关键帧检测、部件识别、姿态估计和迭代组装四个步骤。
实验采用两种设置:
- 使用GPT-4V自动检测关键帧:结果不理想,Chamfer Distance达0.55,且1/3的测试视频未能完成组装;
- 使用人工标注的关键帧:由于姿态估计模型的局限性,最终Chamfer Distance仍达0.33。

这些实验结果揭示了当前AI模型的两个关键局限:
- 视频理解能力不足:当前的视频模型对时序信息的分析仍然较弱,往往停留在单帧图像分析的层面;
- 空间推理受限:在真实场景的复杂条件下(如光照变化、视角改变、部件遮挡等),现有模型的空间推理能力仍显不足。
作者简介
本项目第一作者,是斯坦福大学计算机科学硕士生刘雨浓(Yunong Liu)目前在斯坦福SVL实验室(Vision and Learning Lab),由吴佳俊教授指导。

她本科毕业于爱丁堡大学电子与计算机科学专业(荣誉学位),曾在德克萨斯大学奥斯汀分校从事研究实习。
斯坦福大学助理教授、清华姚班校友吴佳俊,是本项目的指导教授。

另据论文信息显示,斯坦福大学博士后研究员刘蔚宇(Weiyu Liu),与吴佳俊具有同等贡献。

此外,Salesforce AI Research研究主任Juan Carlos Niebles,西北大学计算机科学系助理教授、斯坦福访问学者李曼玲(Manling Li)等人亦参与了此项目。



项目主页:
https://yunongliu1.github.io/ikea-video-manual/
论文地址:
https://arxiv.org/abs/2411.11409
- Grok4全网玩疯,成功通过小球编程测试,Epic创始人:这就是AGI2025-07-11
- “英伟达显卡就是一坨*”!博主6000字檄文怒批:烧接口、缺单元、驱动变砖还威胁媒体2025-07-07
- 数学题干带猫AI就不会了!错误率翻300%,DeepSeek、o1都不能幸免2025-07-05
- 腾讯3D生成模型上新!线稿可变“艺术级”3D模型,鹅厂内部设计师也在用2025-07-09