史上最严中文真实性评估:OpenAI o1第1豆包第2,其它全部不及格
淘宝天猫集团的研究者们提出了中文简短问答(Chinese SimpleQA)
允中 发自 凹非寺
量子位 | 公众号 QbitAI
新的大语言模型(LLM)评估基准对于跟上大语言模型的快速发展至关重要。
近日,淘宝天猫集团的研究者们提出了中文简短问答(Chinese SimpleQA),这是首个全面的中文基准,具有“中文、多样性、高质量、静态、易于评估”五个特性,用于评估语言模型回答简短问题的真实性能力。
研究人员表示,中文简短问答能够指导开发者更好地理解其模型的中文真实性能力,并促进基础模型的发展。
论文地址:https://arxiv.org/abs/2411.07140
引言
人工智能发展中的一个重大挑战是确保语言模型生成的回答在事实上准确无误。当前前沿模型有时会产生错误输出或缺乏证据支持的答案,这就是所谓的“幻觉”问题,极大地阻碍了通用人工智能技术(如大语言模型)的广泛应用。此外,评估现有大语言模型的真实性能力也颇具难度。例如,大语言模型通常会生成冗长的回复,包含大量事实性陈述。最近,为解决上述评估问题,OpenAI发布了简短问答基准(SimpleQA),其中包含4326个简洁且寻求事实的问题,使得衡量真实性变得简单可靠。
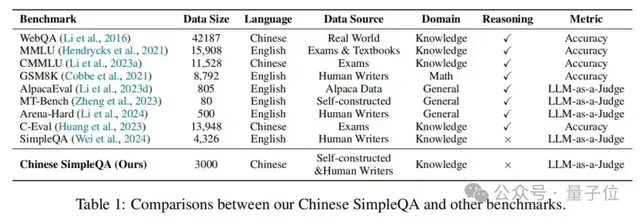
然而,简短问答基准主要针对英语,导致对大语言模型在其他语言中的能力了解有限。此外,受近期几个中文大语言模型基准(如C-Eval、CMMLU)的启发,为了评估大语言模型在中文语境下的真实性能力,淘天集团的研究人员提出了中文简短问答基准。该基准由3000个高质量问题组成,涵盖从人文到科学工程等6个主要主题。具体而言,中文简短问答的显著主要特征如下:
- 中文特性:专注于中文语言,能够全面评估现有大语言模型在中文语境下的真实性能力。
- 多样性:涵盖6个主题,即“中国文化”“人文”“工程、技术与应用科学”“生活、艺术与文化”“社会”和“自然科学”。这些主题总共包括99个细粒度的子主题,体现了中文简短问答的多样性。
- 高质量:实施了全面且严格的质量控制流程,以确保中文简短问答的质量和准确性。
- 静态性:与SimpleQA类似,为保持中文简短问答的常青特性,所有参考答案不会随时间改变。
- 易于评估:与SimpleQA类似,由于问题和答案都非常简短,通过现有大语言模型(如OpenAI API)进行评分的过程快速便捷。
研究人员在中文简短问答上对现有大语言模型进行了全面评估和分析,得出了以下一些有洞察力的发现:
- 中文简短问答具有挑战性:只有o1-preview和Doubao-pro-32k达到及格分数(在正确指标上分别为63.8%和61.9%),许多闭源和开源大语言模型仍有很大的改进空间。
- 模型越大效果越好:基于Qwen2.5系列、InternLM系列、Yi-1.5系列等的结果,作者观察到模型越大性能越好。
- 更大的模型更校准:作者观察到o1-preview比o1-mini更校准,GPT-4o比GPT-4o-mini更校准。
- 检索增强生成(RAG)很重要:当将RAG策略引入现有大语言模型时,不同大语言模型之间的性能差距显著缩小。例如,对于GPT-4o和Qwen2.5-3B,使用RAG后性能差距从42.4%缩小到9.3%。
- 存在对齐代价:现有的对齐或后训练策略通常会降低语言模型的真实性。
- SimpleQA和中文简短问答的排名不同:几个专注于中文的大语言模型(Doubao-pro-32k和GLM-4-Plus)的性能接近高性能的o1-preview。特别是在“中国文化”主题上,这些中文社区大语言模型明显优于GPT或o1系列模型。
中文简短问答
概述
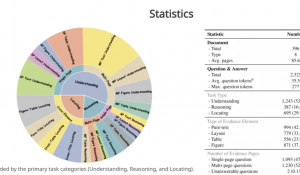
中文简短问答的类别分布,包含六个主要主题,每个主要主题包含多个二级子主题。在表1中,作者将中文简短问答与几个主流的大语言模型评估基准进行了比较,这表明中文简短问答是第一个专注于评估大语言模型中中文知识边界的基准。
数据收集
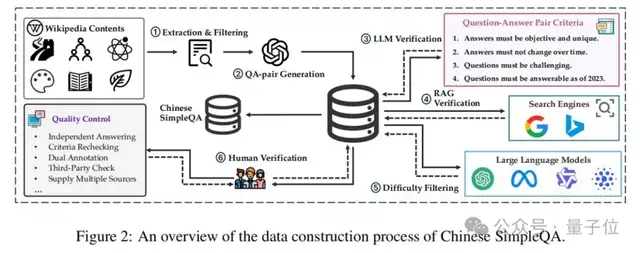
如图2所示,中文简短问答的数据收集过程涉及自动构建和人工验证。自动阶段包括:(1)提取和过滤相关知识内容,(2)自动生成问题-答案对,(3)根据预定义标准使用大语言模型验证这些对,(4)执行检索增强生成(RAG)验证,以及(5)进行难度筛选。
具体而言,首先,作者从各种知识领域(如维基百科)收集大量知识丰富的文本内容,并使用质量评估模型过滤掉低质量数据。然后,作者提示大语言模型使用这些高质量知识内容生成问题-答案对。之后,为确保中文简短问答的质量,作者使用大语言模型去除不符合预定义标准要求的样本。通过这种方式,可以获得大量初步筛选后的知识问题-答案对。同时,为了提高答案的质量,部署外部检索工具(即搜索引擎)来收集更多样化的信息,这引导大语言模型基于RAG系统评估答案的事实正确性。具体来说,应用LlamaIndex作为检索方法,以谷歌和必应的搜索结果作为数据源。关于生成和验证的详细信息可以在附录A中找到。此外,作者过滤一些简单样本以发现大语言模型的知识边界并提高中文简短问答的难度。具体来说,如果一个问题可以被四个大模型正确回答,则认为它是一个简单问题并将其丢弃。
值得注意的是,问题-答案对的构建基于以下标准:
- 答案必须客观且唯一:问题应与客观世界的事实知识相关,不受个人主观观点影响。例如,以“你认为……怎么样?”或“你如何评价……?”开头的问题是不合适的。此外,每个问题的答案必须是唯一的,排除多个正确答案的可能性。例如,“朱祁镇在哪一年登上皇位?”这个问题是不充分的,因为它有两个可能的答案:1435年和1457年。
- 答案必须不随时间变化:答案应始终反映永恒的事实,不受提问时间的影响。例如,“碳的原子序数是多少?”,答案“6”始终不变。相比之下,关于时事的问题,如“某个国家的现任总统是谁?”是不合适的,因为其答案会随时间变化。
- 问题必须具有挑战性:问题不应过于简单,设计的查询需要全面评估模型的知识深度。
- 问题必须截至2023年可回答:每个问题必须在2023年12月31日前可回答,以确保对在此日期后训练的数据的模型进行公平评估。
2.3质量控制
在自动数据收集之后,采用人工验证来提高数据集质量。具体来说,每个问题由两个人工注释者独立评估。首先,注释者确定问题是否符合上述预定义标准。如果任何一个注释者认为问题不符合要求,则丢弃该样本。随后,两个注释者都使用搜索引擎检索相关信息并制定答案。在此阶段,注释者应使用权威来源(如维基百科、百度百科)的内容,并且每个注释者必须提供至少两个支持性URL。如果注释者的答案不一致,则由第三个注释者审查该样本。最终注释由第三个注释者根据前两个评估确定。最后,将人工注释结果与大语言模型生成的回复进行比较,仅保留完全一致的问题-答案对。这个严格的人工验证过程确保了数据集保持高准确性并符合既定标准。
在构建和注释中文简短问答的整个过程中,许多低质量的问题-答案对被丢弃。具体来说,最初生成了10000对。经过使用不同模型进行难度评估后,大约保留了6310对,其中约37%的较简单数据被丢弃。在此之后,经过基于规则的验证和基于模型的RAG验证,又删除了2840个样本,这意味着仅剩下约35%的原始生成数据。最后,经过彻底和严格的人工审查,仅保留了约3000个样本,约占原始数据集的30%。
2.4数据集统计
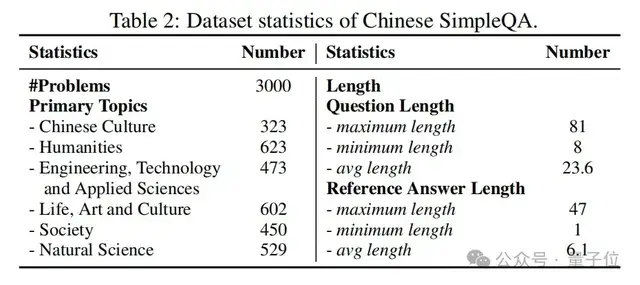
表2展示了中文简短问答的统计数据。共有3000个样本,中文简短问答在六个主要主题上的数据分布相对均衡,这可以有效地评估大语言模型在各个领域的知识边界。此外,该数据集中问题和参考答案的长度分布都非常短,这是基于知识查询的特点。值得注意的是,使用中文简短问答评估模型需要最少的输入和输出标记,从而导致非常低的评估计算和时间成本。
2.5评估指标
与SimpleQA类似,中文简短问答也采用以下五个评估指标:
- 正确(CO):预测答案完全包含参考答案,且不引入任何矛盾元素。
- 未尝试(NA):预测答案未完全给出参考答案,但与参考答案不存在矛盾元素。
- 不正确(IN):预测答案与参考答案矛盾,即使矛盾可以解决。
- 尝试后正确(CGA):该指标是在尝试回答的问题中准确回答问题的比例。
- F分数:该指标表示正确和尝试后正确之间的调和平均值。
3.实验
3.1基线模型
作者评估了17个闭源大语言模型(即o1-preview、Doubao-pro-32k、GLM-4-Plus、GPT-4o、Qwen-Max、Gemini-1.5-pro、DeepSeek-V2.5、Claude-3.5-Sonnet、Yi-Large、moonshot-v1-8k、GPT-4-turbo、GPT-4、Baichuan3-turbo、o1-mini、Doubao-lite-4k、GPT-4o-mini、GPT-3.5)和24个开源大语言模型(即Qwen2.5系列、InternLM2.5系列、Yi-1.5系列、LLaMA3系列、DeepSeek系列、Baichuan2系列、Mistral系列、ChatGLM3和GLM-4)。
3.2主要结果
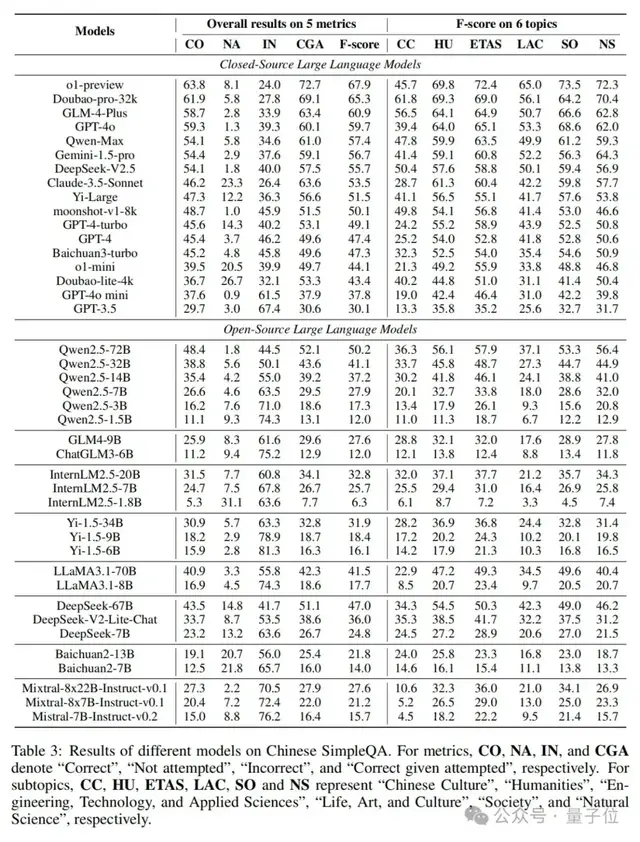
如表3所示,论文提供了不同大语言模型在中文简短问答上的性能结果。具体来说,与SimpleQA类似,作者提供了五个评估指标的总体结果。
此外,论文还报告了六个主题的F分数,以分析这些大语言模型的细粒度真实性能力。在表3中,有以下有洞察力和有趣的观察结果:
- o1-preview表现最佳:o1-preview在中文简短问答上取得了最佳性能,并且几个近期专注于中文的闭源大语言模型(Doubao-pro-32k和GLM-4-Plus)的性能结果与o1-preview非常接近。
- “mini”系列模型表现较差:很明显,“mini”系列模型(o1-mini、GPT-4o-mini)的结果比相应的更大模型(o1-preview、GPT-4o)低,这也表明这些“mini”系列模型不注重记忆事实性知识。
- 模型越大性能越好:基于许多模型系列(如GPT、Qwen2.5、InternLM2.5、Yi-1.5),我们可以得出更大的大语言模型会导致更好的性能这一结论。
- 小模型在“未尝试”上得分较高:小型大语言模型通常在“未尝试(NA)”上得分较高。o1-mini、InternLM2.5-1.8B的NA分数分别为20.5和9.3,远高于相应更大模型的分数(o1-preview为8.1,Qwen2.5-72B为1.8)。
- 不同子主题性能差异显著:不同大语言模型在不同子主题上存在显著的性能差异。值得注意的是,中文社区大语言模型(如Doubao-pro-32k、GLM-4-Plus、Qwen-Max、Deepseek)在“中国文化(CC)”子主题上明显优于GPT或o1模型。相比之下,o1在与科学相关的子主题(如“工程、技术与应用科学(ETAS)”和“自然科学(NS)”)上具有显著优势。
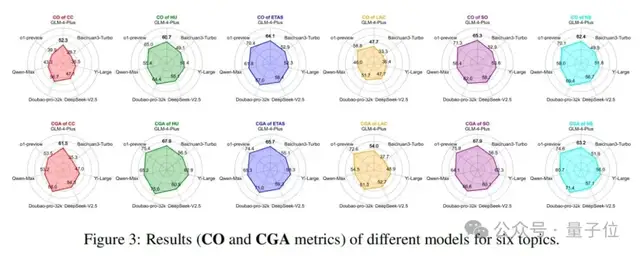
此外,论文还在图3中提供了六个主题的详细结果(CO和CGA指标)。
3.3进一步分析
3.3.1校准分析
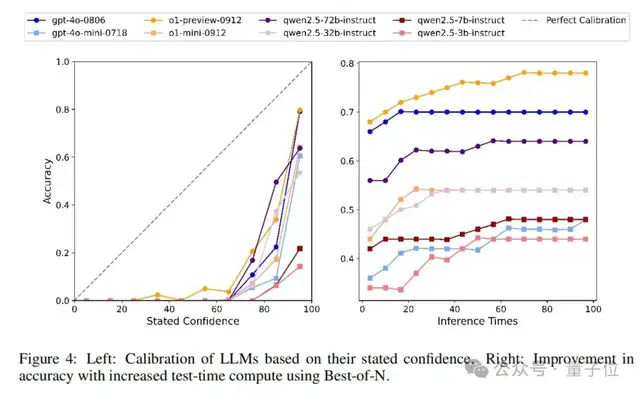
对于不同大语言模型的校准,与SimpleQA类似,作者指示模型在回答问题时提供相应的置信水平(从0到100),以衡量模型对其答案的信心(见附录B中的提示)。我们知道,一个完美校准的模型的置信度(%)应该与其答案的实际准确性相匹配。图4中的左图说明了校准性能,这表明GPT-4o比GPT-4o-mini校准得更好,o1-preview比o1-mini校准得更好。对于Qwen2.5系列,校准顺序为Qwen2.5-72B>Qwen2.5-32B>Qwen2.5-7B>Qwen2.5-3B,这表明更大的模型尺寸会导致更好的校准。此外,对于所有评估模型,它们在置信度>50的范围内的置信度低于完美校准线,这意味着它们都高估了其回复的准确性,存在过度自信的情况。
3.3.2测试时间计算分析
论文还评估了不同模型在增加测试时间计算时与回复准确性的关系。具体来说,从中文简短问答中随机抽取50个样本,对于每个样本,模型被要求独立回答100次。然后,使用最佳N法随着推理次数的增加获得模型的回复准确性。结果如图4中的右图所示。作者观察到,随着推理次数的增加,所有模型的回复准确性都有所提高,并最终达到一个上限。这对于中文简短问答来说是合理的,因为它专门用于探测模型知识的边界。
3.3.3检索增强生成(RAG)效果分析
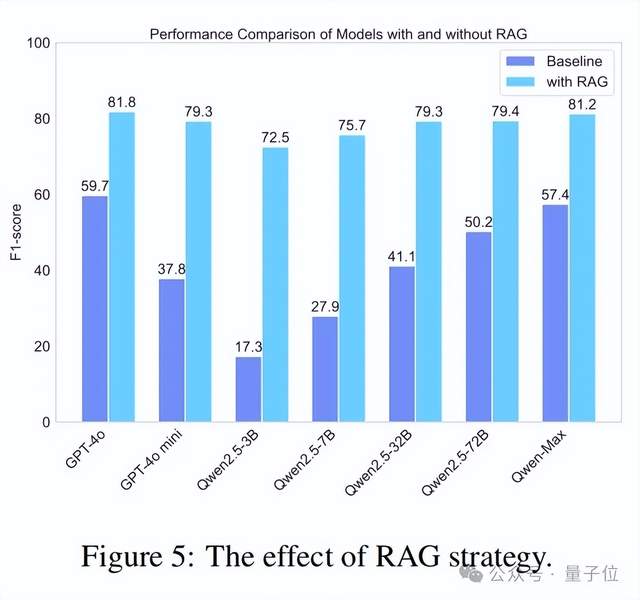
在这项研究中,论文探索了检索增强生成(RAG)策略在提高大语言模型在中文简短问答数据集上的事实准确性方面的有效性。具体来说,作者基于LlamaIndex重现了一个RAG系统,并整合了谷歌搜索API。如图5所示,所有模型在使用RAG后准确性都有显著提高。例如,Qwen2.5-3B的性能提高了三倍多。值得注意的是,几乎所有使用RAG的模型都优于原生的GPT-4o模型。同时,RAG的应用也显著降低了模型之间的性能差距。例如,使用RAG的Qwen2.5-3B与使用RAG的Qwen2.5-72B之间的F分数差异仅为6.9%。这表明RAG大大缩小了模型之间的性能差距,使较小的模型在使用RAG增强时也能实现高性能。总体而言,这表明RAG是提高大语言模型真实性的有效捷径。
3.3.4对齐代价分析
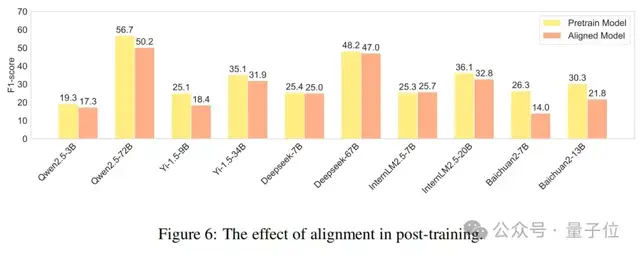
最近,先前的研究(OpenAI,2023;Song等人,2023)发现,对齐可能会导致语言模型能力的下降,即所谓的“对齐代价”。为了说明对齐对真实性的影响,作者对预训练模型和经过监督微调(SFT)或强化学习从人类反馈(RLHF)训练的对齐模型进行了比较性能分析。如图6所示,不同模型在训练后表现出不同的趋势,但大多数模型都有显著下降。其中,Baichuan2系列模型下降最为显著,Baichuan2-7B和Baichuan2-13B的F分数分别降低了47%和28%。这反映出当前大多数大语言模型的对齐训练在产生知识幻觉方面仍然存在明显缺陷,这进一步反映了此次数据集的必要性。
3.3.5子主题结果分析
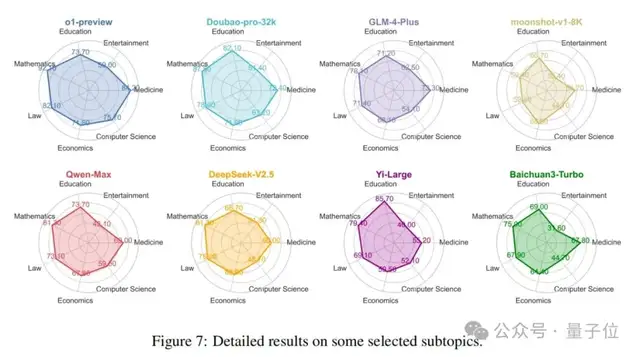
如2.2节所述,该基准涵盖了总共99个子主题,可以全面检测模型在各个领域的知识水平。图7展示了o1模型和七个著名的中文社区模型在几个常见领域内的性能比较。首先,从整体上看,o1-preview模型在这些领域中表现出最全面的性能,Doubao模型紧随其后。相比之下,Moonshot模型总体性能最弱。其次,在具体领域方面,中文社区模型和o1模型在计算机科学和医学等领域存在显著差距。然而,在教育和经济等领域,这种差距最小。值得注意的是,在教育领域,一些中文社区模型优于o1-preview,突出了它们在特定垂直领域取得成功的潜力。最后,在具体模型方面,Moonshot模型在数学、法律和娱乐等领域明显较弱,而Baichuan模型在娱乐领域也表现不佳。Yi-Large模型在教育领域表现出色,o1模型在其他领域保持最强性能。评估模型在基准数据集内不同领域的性能使用户能够确定最适合其特定需求的模型。
3.3.6中文简短问答与SimpleQA的比较
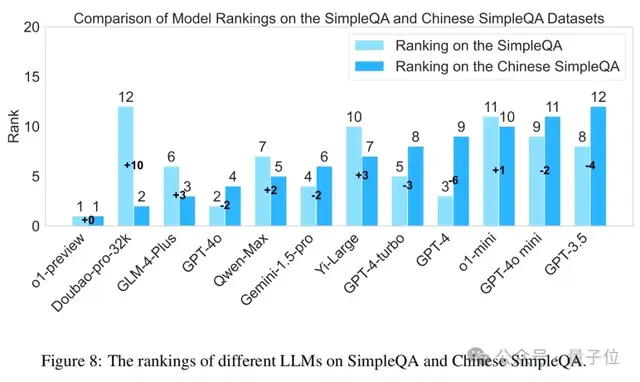
论文还比较了各种模型在SimpleQA和中文简短问答上的排名差异。如图8所示,这些两个基准上的模型性能存在显著差异。例如,Doubao-pro-32k在中文简短问答上的排名显著提高,从第12位上升到第2位(+10)。相反,GPT-4在中文简短问答上的性能下降,从第3位下降到第9位(-6)。这些差异强调了在不同语言的数据集上评估模型的重要性,以及研究优化模型在不同语言环境中性能的必要性。值得注意的是,o1-preview在两个数据集上始终保持领先地位,表明其对不同语言上下文的稳健性和适应性。此外,大多数中文社区开发的模型(如Qwen-Max、GLM-4-Plus、Yi-Large、Doubao-pro-32k)在SimpleQA上的表现优于在简短问答上的表现,展示了它们在中文任务上的竞争力。
4.相关工作
–大语言模型真实性:大语言模型真实性是指大语言模型产生遵循事实内容的能力,包括常识、世界知识和领域事实,并且这些事实内容可以通过权威来源(如维基百科、教科书)得到证实。最近的作品探索了大语言模型作为事实知识库的潜力(Yu等人,2023;Pan等人,2023)。具体而言,现有研究主要集中在对大语言模型真实性的定性评估(Lin等人,2022;Chern等人,2023)、对知识存储机制的研究(Meng等人,2022;Chen等人,2023)以及对知识相关问题的分析(Gou等人,2023)。
–真实性基准:已经提出了许多真实性基准(Hendrycks等人,2021;Zhong等人,2023;Huang等人,2023;Li…等人,2023b;Srivastava等人,2023;Yang等人,2018)。例如,MMLU(Hendrycks等人,2021)用于测量在各种不同任务上的多任务准确性。TruthfulQA(Lin等人,2022)专注于评估语言模型生成答案的真实性。此外,HaluEval(Li等人,2023c)用于检查大语言模型产生幻觉的倾向。最近,SimpleQA(Wei等人,2024)被提出用于测量大语言模型中的简短事实性。然而,SimpleQA仅关注英语领域。相比之下,中文简短问答旨在全面评估中文语境下的真实性。
结论
为了评估现有大语言模型的真实性能力,淘天集团的研究者们提出了第一个中文简短事实性基准(即中文简短问答),它包括6个主要主题和99个子主题。此外,中文简短问答主要具有五个重要特征(即中文、多样性、高质量、静态和易于评估)。基于中文简短问答,研究人员全面评估了现有40多个大语言模型在真实性方面的性能,并提供了详细分析,以证明中文简短问答的优势和必要性。在未来,研究人员将研究提高大语言模型的真实性,并探索将中文简短问答扩展到多语言和多模态设置。
论文地址:https://arxiv.org/abs/2411.07140
- 手机实现GPT级智能,比MoE更极致的稀疏技术:省内存效果不减|对话面壁&清华肖朝军2025-04-12
- 7B小模型写好学术论文,新框架告别AI引用幻觉,实测100%学生认可引用质量2025-04-11
- 字节新推理模型逆袭DeepSeek,200B参数战胜671B,豆包史诗级加强?2025-04-11
- Llama 4发布36小时差评如潮!匿名员工爆料拒绝署名技术报告2025-04-07