
DeepSeek版o1炸场,数学代码超越OpenAI,每天免费玩50次,后续将开源
新Scaling Laws是真的,计算时间越长,表现越强
西风 发自 凹非寺
量子位 | 公众号 QbitAI
DeepSeek版o1来了,发布即上线,现在就能玩!

模型名为DeepSeek-R1-Lite,预览版在难度较高数学和代码任务上超越o1-preview,大幅领先GPT-4o等。

据了解,DeepSeek-R1-Lite使用强化学习训练,推理含大量反思和验证,遵循新的Scaling Laws——
推理越长,表现更强。
如下展示,在AIME测试基准中,随着计算时间增加,其得分稳步提升。

值得一提的是,官方还表示,目前模型仍在开发阶段,经持续迭代,正式版DeepSeek-R1模型将完全开源,包括公开技术报告并提供API。
这下网友们纷纷坐不住,已齐刷刷码住开始实测了。
网友实测在此
登录官方网页,打开深度思考按钮,就能体验DeepSeek-R1-Lite预览版。
每天有默认50次的免费使用。

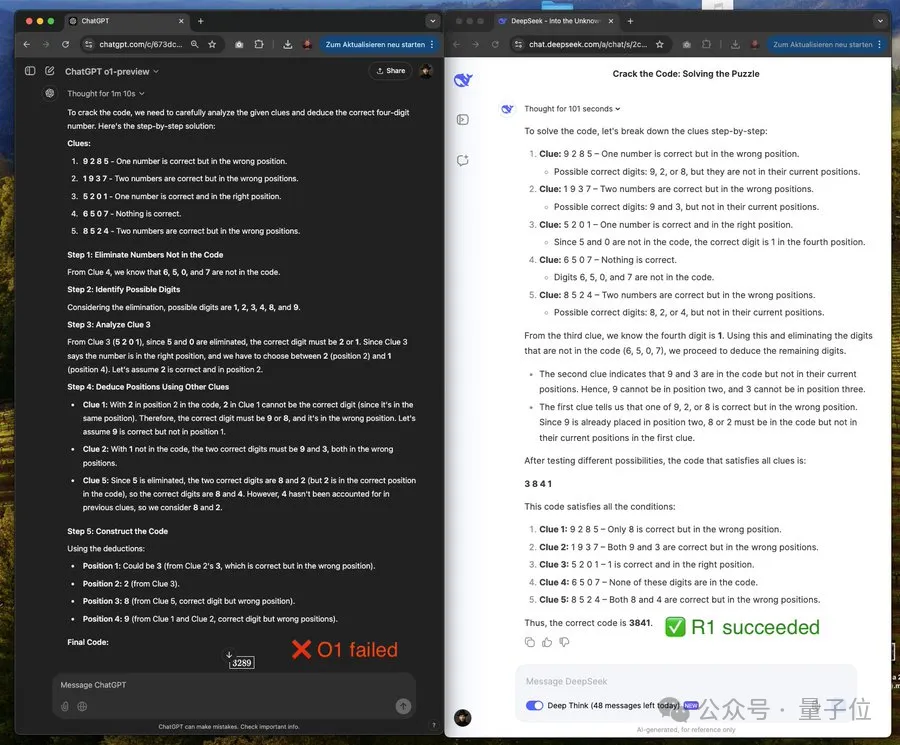
下面这位小哥让模型破解如下密码:
9 2 8 5 (一个数字正确但位置错误)
1 9 3 7 (两个数字正确但位置错误)
5 2 0 1 (一个数字正确且位置正确)
6 5 0 7 (没有数字正确)
8 5 24 (两个数字正确但位置错误)

没成想OpenAI o1-preview在这个测试中答错了(3289),而DeepSeek-R1-Lite-Preview推理正确,直接给出了正确答案3841。
还有网友来了个系统性测试,一通体验后感觉是:
数学能力:该模型在数学推理问题上看起来很有效。基准测试结果确实反映了模型在数学推理能力上的潜力。这是一个值得密切关注的模型。
编码任务:在解决编程问题时,表现稍显不足。例如,在生成用于转置矩阵的bash脚本这样的简单代码问题上,它未能成功解决,而o1模型可以轻松解决。
复杂知识理解:我还尝试了在一个更难的字谜游戏上测试它,但它表现得非常糟糕。公平地说,即使o1模型在这个需要现代知识引用的测试中也同样表现不佳。

这位网友最后还补充道:
我认为该模型在代码和数学任务上表现出色,这可能得益于DeepSeek团队在这些领域的明确优化。然而,在“推理”步骤上仍有改进空间。
在某些情况下,模型似乎能够在生成推理步骤时自我纠正,表现出类似原生“自我反思”的能力。不过,没有训练数据、模型架构和技术报告/论文的细节,很难确认这一点。
期待未来的开源模型和API!
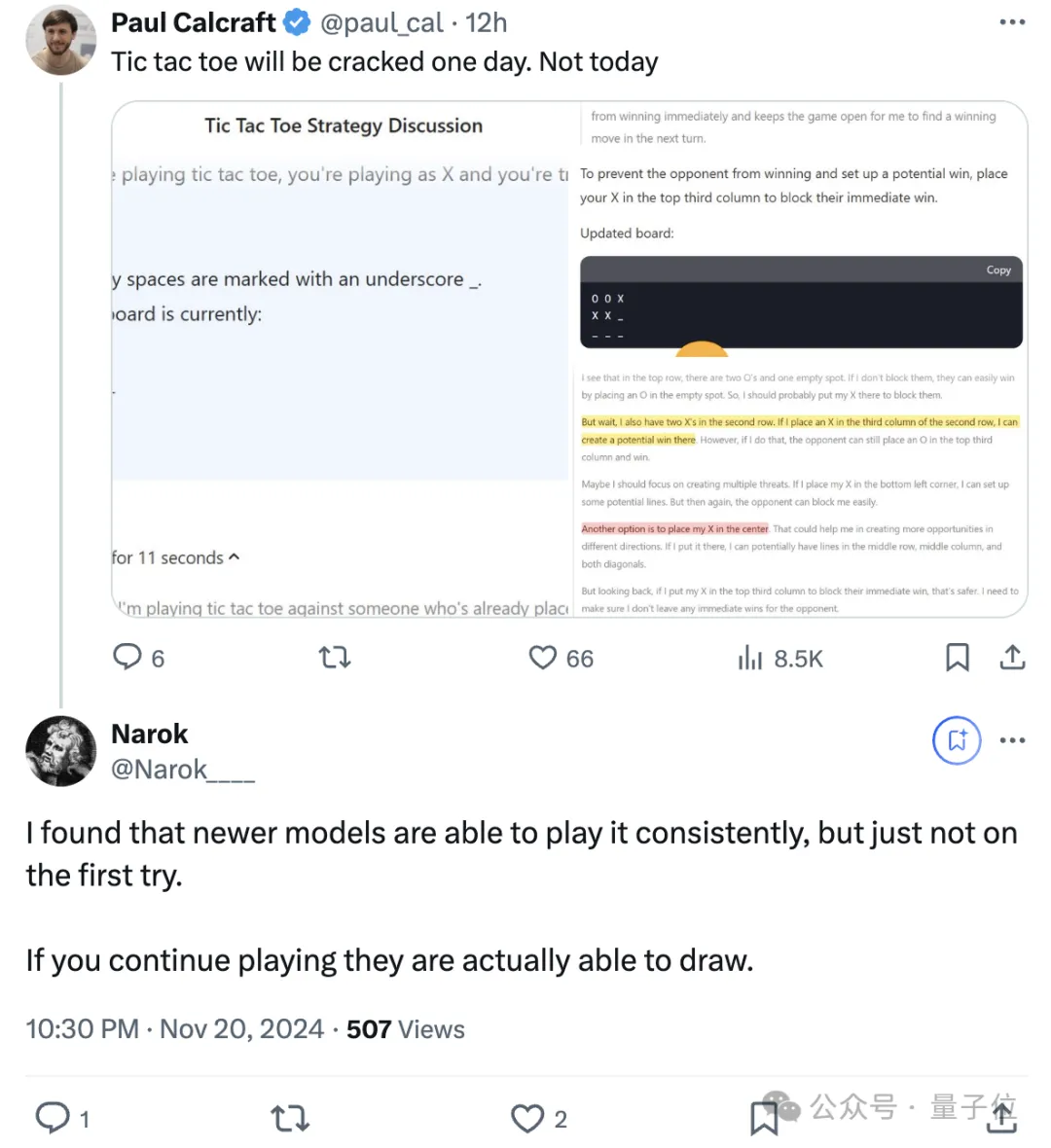
除此之外,也有网友在测试中发现,模型玩井字棋(tic tac toe)还是不太行。


不过,有网友反馈现在的一些新模型能够稳定地玩这个游戏,但不能在第一次尝试时就成功。
如果继续尝试,它们实际上可以画出正确的结果。
好了,感兴趣的童鞋赶紧自己实测一波吧~
官网:https://chat.deepseek.com/
参考链接:
[1]https://x.com/deepseek_ai/status/1859200141355536422
[2]https://x.com/_philschmid/status/1859203470059811298
[3]https://x.com/omarsar0/status/1859373413439066590
- 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品2025-04-14
- 4090玩转大场景几何重建,RGB渲染和几何精度达SOTA|上海AI Lab&西工大新研究2025-04-13
- 阿里云造“Agent工厂”,百炼MCP服务上线,无需代码5分钟建Agent2025-04-09
- 又一上海人形机器人加入开源!全套图纸+代码,来自傅利叶2025-04-11

相关阅读
上海AI实验室版o1已上线!数学题、Leetcode全拿下,还会玩24点
上海 AI 实验室推出强推理模型书生 InternThinker,该模型能快速解决更复杂的数学解题、代码编程、数字游戏等任务,具备长思维能力且能在推理过程中自我反思和纠正。








