杨植麟发布Kimi新模型:数学对标o1,中考高考考研成绩全第一
杨植麟现场回应大伙儿感兴趣的问题
西风 发自 凹非寺
量子位 | 公众号 QbitAI
kimi全面开放一周年之际,创始人杨植麟亲自发布新模型——
数学模型k0-math,对标OpenAI o1系列,主打深入思考。
在MATH、中考、高考、考研4个数学基准测试中,k0-math成绩超过o1-mini和o1-preview。
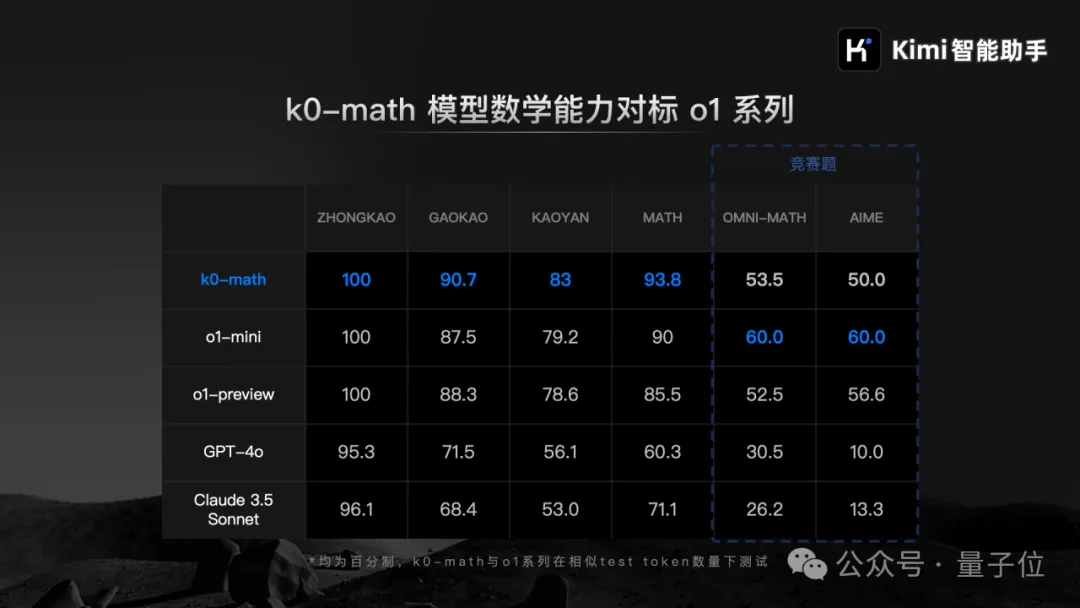
在demo展示中,k0-math思考过程全面展示,解题过程可能会非常长。
它会一边自言自语“我卡壳了”,一边不断尝试用各种思路。
以下面这道AIME竞赛题目为例,k0-math通过不断探索和试错,尝试了八九次做法后,最终得出了正确结果。

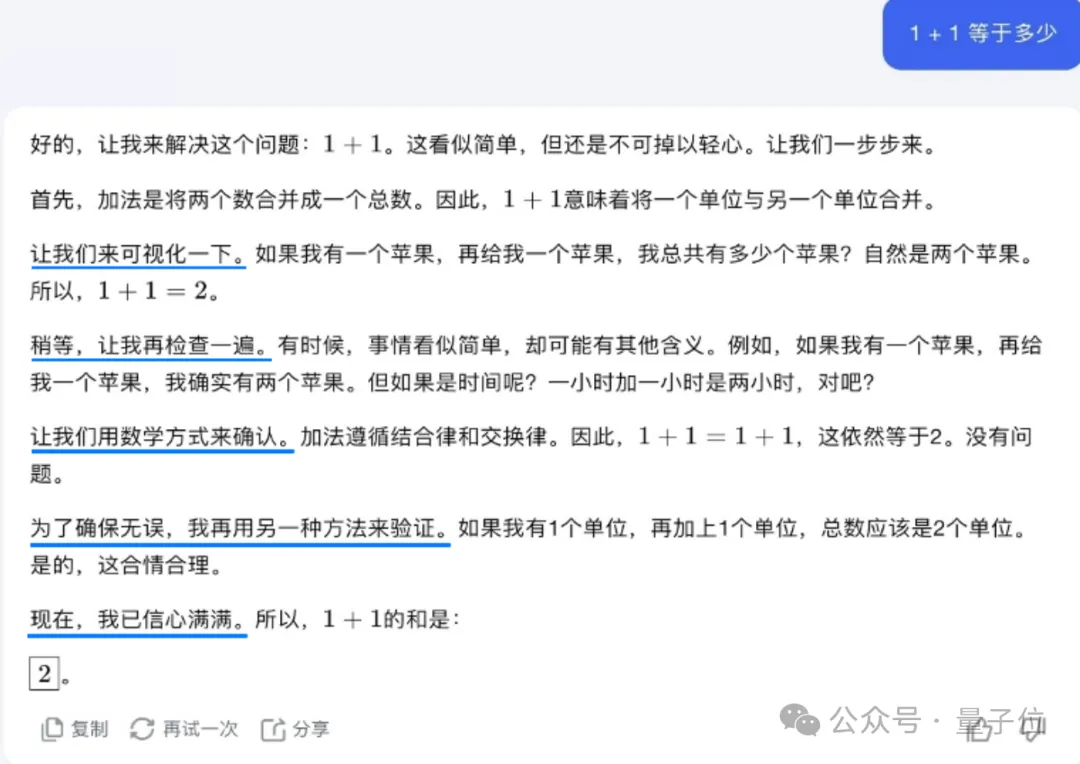
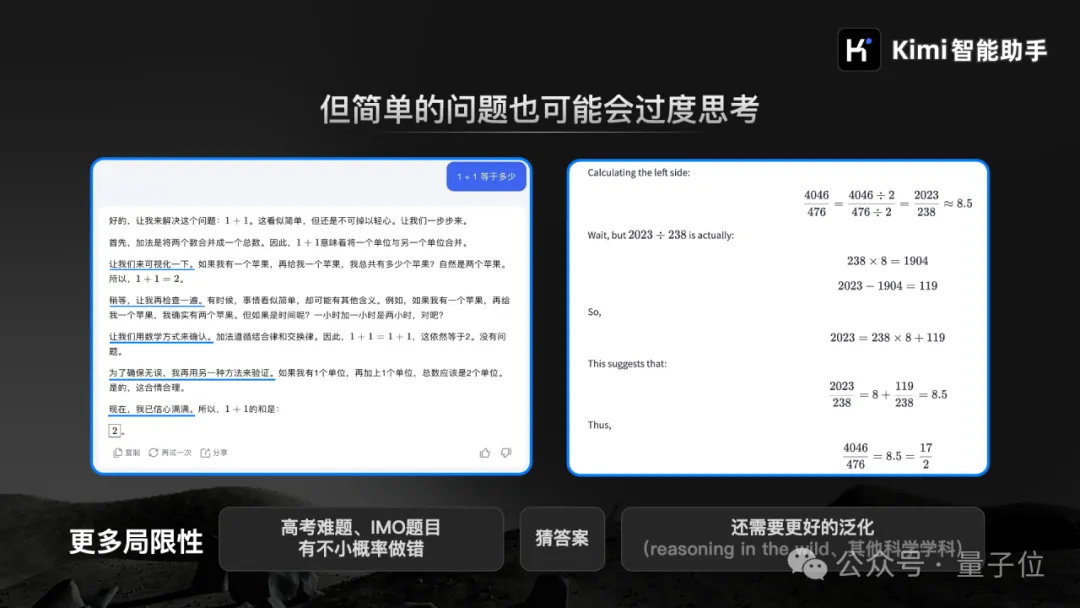
杨植麟现场直言,很简单的问题有时它也会反复思考。
比如遇到简单的“1+1等于几”,它要“先可视化一下”,“再检查一遍”、“用数学方式来确认”、“再用另一种方法来验证”,最终才能“信心满满”得出最终答案1+1=2:
再比如4046/476等于多少,它其实一开始就得到了答案,但又进行反思经过一系列验证推出等于8.5:

在杨植麟看来,这是一个机遇,也是一个局限。预计在下一阶段的模型迭代中,会逐步改善这个问题,让模型能够自己知道何时需要深入思考。
发布k0-math也反映出月之暗面现在的着重点——提升模型的深入思考能力、基于强化学习的Scaling Law。
杨植麟表示最近Kimi探索版还运用强化学习技术创新搜索体验,提升了意图增强、信源分析和链式思考三大推理能力。
k0-math模型和更强的Kimi探索版,未来几周就将分批陆续上线Kimi网页版和Kimi智能助手APP。
除新产品外,杨植麟现场还一并回答了大伙儿感兴趣的诸多问题,包括接下来的研发重点、对多模态的看法、预训练情况等。
Kimi探索版推理能力提升
Kimi探索版意图增强能力提升,指的是它可以将抽象的问题和模糊的概念具体化,拓展用户的真实搜索意图。
例如,当互联网产品经理调研某产品的用户忠诚度,Kimi探索版会思考当用户搜索“忠诚度”时,本质上是想做数据的分析,然后找到可以体现忠诚度的维度,将这个比较模糊和抽象的概念,转化为更加具体的“活跃度、留存率、使用频率、使用时长”等关键词。
然后通过机器更擅长的海量并行搜索,查找更全面和准确的答案。

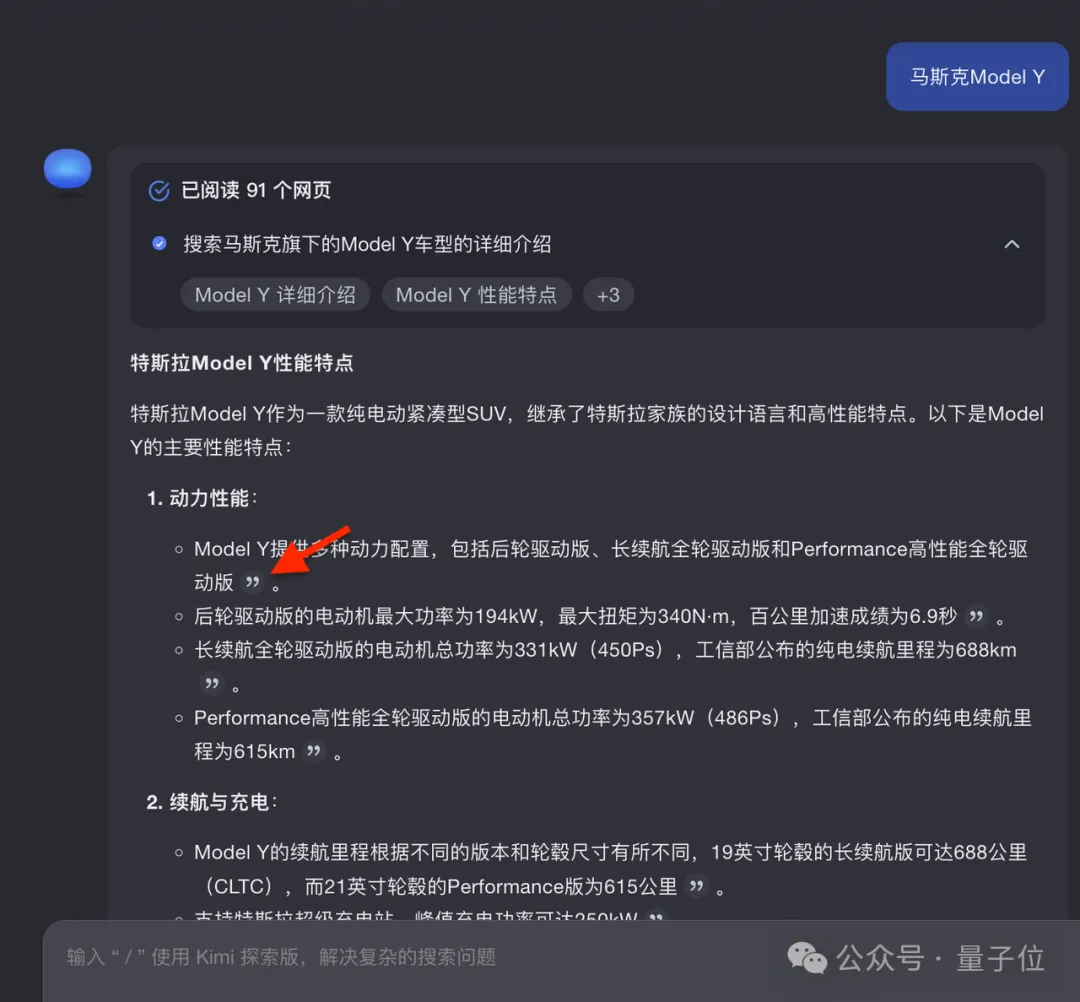
Kimi 探索版信源分析能力也有提升,会从大量的搜索来源结果中,分析筛选出更具权威性和可靠性的信源。
现在在答案中还提供溯源链接了,可一键定位信源具体出处,精确到段落级别,让条信息都有据可查。
最后链式思考能力提升,指的是Kimi探索版可以更好地基于思维链推理能力处理产品、公司、行业等研究问题。
例如,当程序员做技术选型,想要了解“react中有哪些状态管理库,最好用的是什么”。
Kimi首先会拆解问题,找到react的状态管理库有哪些,然后分别搜索每个状态管理库的优缺点、使用场景和推荐理由,最后分析总结找到的所有高质量信息,推荐一个最适合大多数情况的状态管理库和理由。
“思考决定模型上限”
Q:强化学习过程中,如何解决数据、算力、算法平衡问题?
A:我觉得AI的发展就是一个荡秋千的过程,你会在两种状态之间来回切换。
一种状态是算法、数据非常ready,但是算力不够。所以你要做的事情就是做更多的工程,把infra做得更好,它就能够持续的提升。
我觉得其实从transformer诞生到GPT-4,更多的矛盾就是怎么能够Scale,但是可能在算法和数据上没有本质的问题。
今天当Scale差不多的时候,你会发现我再加更多的算力,并不一定能直接解决这个问题,核心是因为你没有高质量的数据,小几十G的token是人类互联网积累了20多年的上限。
这个时候要做的事情,就是通过算法的改变,让这个东西不会成为瓶颈。现在可以理解成我们遇到的问题或者整个行业遇到的问题,也许你直接加更多的卡它不一定能看到直接的提升,所以你要通过这个方式的改变让它把这个东西释放出来。
所有的好算法就是跟Scaling做朋友,如果你的算法能够释放Scaling的潜力,它就会持续变得更好。
我们从很早就开始做强化学习相关的东西,我觉得这个也是接下来很重要的一个趋势,通过这种方式去改变你的目标函数,改变你的学习的方式,让它能持续的Scale。
Q:非transformer会不会解决这种问题?
A:不会,因为它本身是一个学习算法或者是没有学习目标的问题。
Q:你们这个产品如果一两周之后放到Kimi探索版里,用户可以选择使用,还是你们会根据用户的提问来分配是否用这个模型?在不同的模式下,每个用户一段时间内可以用多少次?以及目前Kimi主要的收入是在打赏,不是付费订阅,你们怎么平衡成本问题?
A:我们接下来的版本大概率会让用户自己去选择。
早期通过这种方式可以更好地分配或者更好满足用户的预期,我们也不想让它1+1等于多少,想半天。
所以我觉得早期可能会用这样的方案。
但是我觉得这里面最终可能还是一个技术问题。两个点,一个点是能够动态的给它分配最优的算力。如果模型足够聪明,它应该知道什么样的问题需要想多久,就跟人一样,不会1+1也想半天。
我们现在已经一定程观察到度简单的问题它的思考时间也会更短,但是可能还不是最优,这是我们通过算法迭代去再提升的。
长期来讲我觉得第二个点是成本也在不断下降。比如说今年如果达到去年GPT-4模型的水平,可能只需要十几B的参数就能做到,去年可能需要一百多B。
Q:你们预训练的情况现在是怎么样的?你着重讲了Scaling Law,比较好奇像你这么聪明的人会不会被Scaling Law这个事情给限制住?
A:我先说第一个问题,我觉得预训练还有空间,半代到一代的模型。这个空间会在明年释放出来,明年我觉得领先的模型会把预训练做到一个比较极致的阶段,今天比如说我们去看最好的模型它大概有这样的空间可以去压榨。
但是我们判断接下来最重点的东西会在强化学习上,就是范式上会产生一些变化。但是它还是Scaling,并不是它不用Scale,只是说你会通过不同的方式去Scale,这是我们的判断。
你说Scaling law会不会是一个天花板或者是上限,这个相对来说我比较乐观一点。
核心就在于原来你用静态数据集,静态数据集其实是比较简单粗暴的使用方式,现在用强化学习的方式很多情况下是有人在参与这个过程的,但是人没有办法给你标注那么多数据,不可能把每道题具体的思路都标出来,所以你其实用AI本身把人的东西加上一个杠杆。
比如说你标100条数据,就能产生非常大的作用,因为剩下的都是它在自己思考,我觉得更多的会用这种方式去解决。
具体从做法上来看,我觉得确定性是比较高的,很多时候是真正把它调出来的过程,所以我现在觉得这个大概率可以通过这种方式去做出来,所以我觉得它上限是很高的。
Q:想问一下多模态的问题,Sora大概马上要发了。
A:我们也做,几个多模态的能力在内测。
我是这样看的,我觉得AI接下来最重要的是思考和交互这两个能力。思考的重要性远大于交互,不是说交互不重要,我觉得思考会决定上限,交互我觉得是一个必要条件,比如说vision的能力,如果没有vision的能力没法做交互。
所以我觉得它两个不太一样,就看要做这个任务标注任务的难度有很大,到底需要一个博士去标,还是每个人都可以标,哪个东西更难找到这样的人,那个东西就是AI的上限。
所以我觉得多模态肯定是必要的,但是我觉得是思考决定它的上限。
- 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品2025-04-14
- 4090玩转大场景几何重建,RGB渲染和几何精度达SOTA|上海AI Lab&西工大新研究2025-04-13
- 阿里云造“Agent工厂”,百炼MCP服务上线,无需代码5分钟建Agent2025-04-09
- 又一上海人形机器人加入开源!全套图纸+代码,来自傅利叶2025-04-11

相关阅读
上海AI实验室版o1已上线!数学题、Leetcode全拿下,还会玩24点
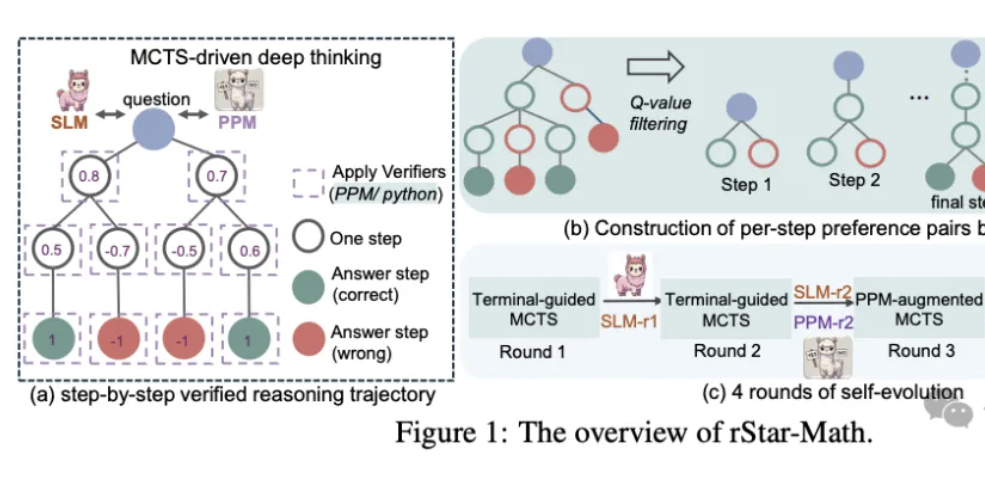
上海 AI 实验室推出强推理模型书生 InternThinker,该模型能快速解决更复杂的数学解题、代码编程、数字游戏等任务,具备长思维能力且能在推理过程中自我反思和纠正。