李飞飞吴佳俊团队推出具身智能决策能力评价基准,o1-preview登顶
更深入了解大模型优势和缺陷
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
大模型的具身智能决策能力,终于有系统的通用评估基准了。
李飞飞吴佳俊团队新提出的评估框架,对具身智能决策的四项关键子能力来了个全面检查。
这套基准已经被选为了NeurIPS数据和测试集(D&B)专栏Oral论文,同时也被收录进了PyPI,只要一行代码就能快速调用。
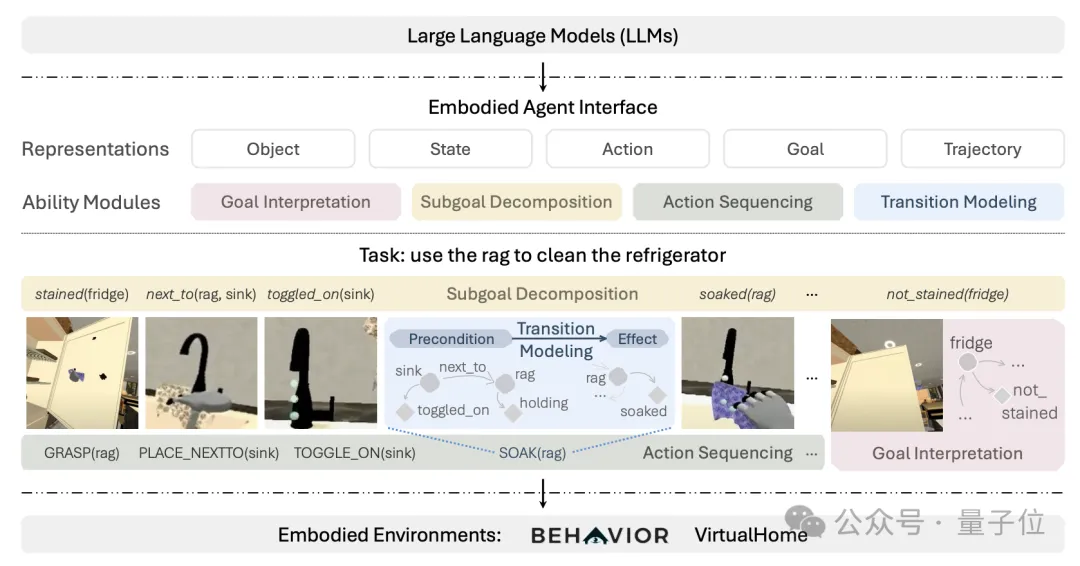
该框架名为Embodied Agent Interface(简称EAI),提供了连接不同模块和基准环境的标准接口。
利用这套框架,作者对18款主流模型进行了测试,形成了一篇超百页的论文。
测试结果显示,在已公开的大模型当中,o1-preview的综合成绩位列第一。
李飞飞本人表示,对这项合作研究感到非常兴奋。

有网友评价说,这项成果为大模型具身智能决策塑造了未来。
四项子能力全面评估
首先,EAI提供了一种统一的目标表示方法,能够兼容不同类型的目标,并支持复杂约束的描述。
团队认为,现有的具身决策任务通常针对特定领域设计目标,缺乏一致性和通用性。
例如,BEHAVIOR和VirtualHome都是具身智能体的评测基准和模拟环境,用于研究智能体在复杂环境中完成任务的能力。
但二者又有所区别,BEHAVIOR使用基于状态的目标,而VirtualHome使用时间扩展的目标。
EAI则通过引入线性时态逻辑(LTL),实现了目标表示方式的统一,提高了模块之间的互操作性,便于比较不同模型在同一任务上的表现。

在具体的评估过程当中,EAI采用了模块化的评估方式,并将评估指标进行了更细粒度的划分。
以往的研究通常将大模型作为整体进行评估,很少关注其在具身决策各个子任务上的表现;
同时,这些现有基准通常只关注任务的最终成功率,很少深入分析模型的错误类型和原因。
为了更深入理解大模型的行为模式和优劣势分布,EAI提出了四个关键能力模块,并设计了一系列细粒度的评估指标:
- 将模型能力分为四个关键模块;
- 定义了清晰的输入输出接口;
- 从轨迹可执行性、目标满足度、逻辑匹配性等多个角度评估模型的性能;
- 引入了丰富的注释(如目标状态、关系、动作),以实现自动化的错误分析。
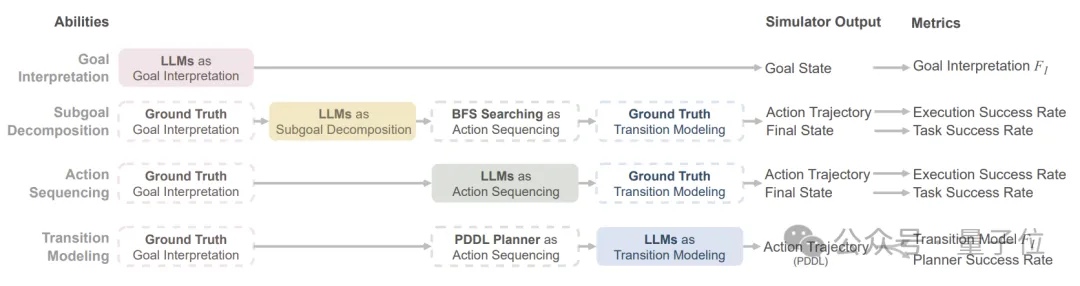
具体来说,四个关键模块及内容分别是:
- 目标解释(Goal Interpretation):将自然语言表述的任务目标转化为形式化的LTL目标公式;
- 子目标分解(Subgoal Decomposition):将任务目标分解为一系列子目标,每个子目标也用LTL公式表示;
- 动作序列规划(Action Sequencing):根据任务目标生成动作序列,在环境中执行以达成目标状态;
- 转换建模(Transition Modeling):为每个动作或操作符生成前提条件和效果,形成环境转换模型。
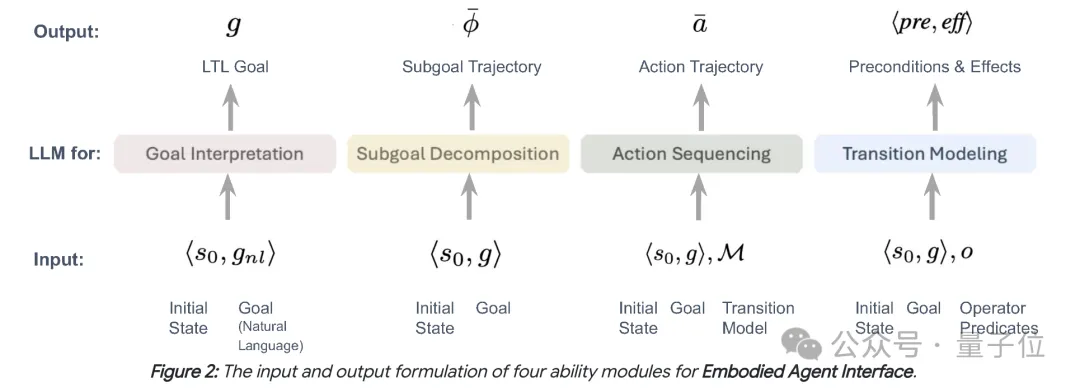
另外,EAI选取了两个具有代表性但特点迥异的环境,也就是前面提到的BEHAVIOR和VirtualHome。
相比于单一环境评估,EAI更能考察大模型跨领域的泛化能力,有助于全面理解其适用范围和局限性。
o1-preview综合成绩第一
利用EAI这套标准,研究团队对GPT、Claude、Gemini等18款主流模型(型号)的决策能力进行了评估。
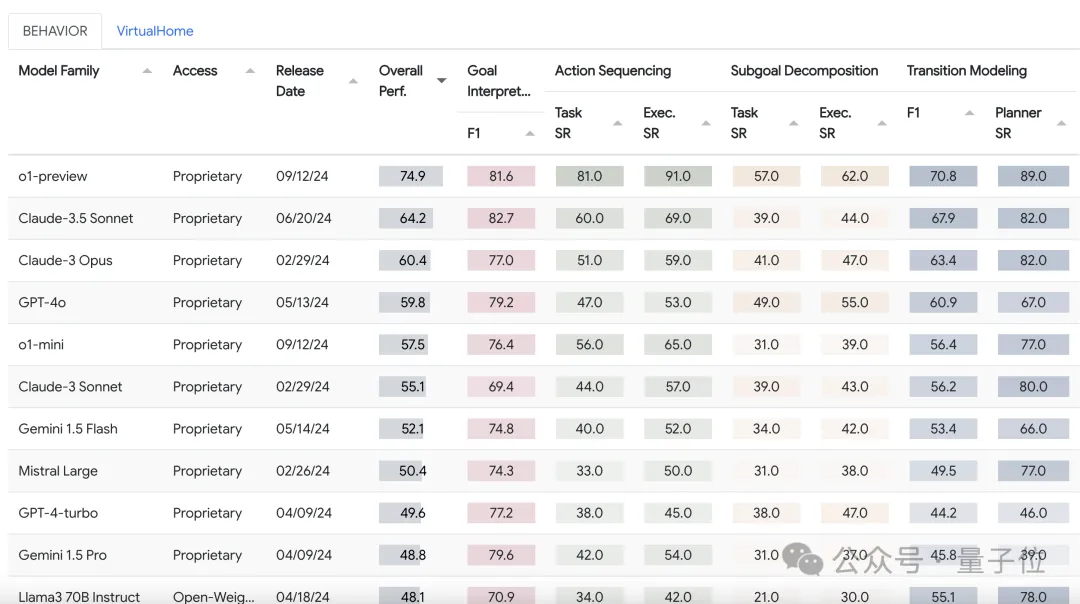
在BEHAVIOR和VirtualHome环境下,o1-preview均获得了排行榜综合成绩第一名。
其中在BEHAVIOR环境中,o1-preview得分为74.9,比第二名的Claude 3.5 Sonnet高了10多分,排在之后的是60分左右的Claude 3 Opus和GPT-4o。
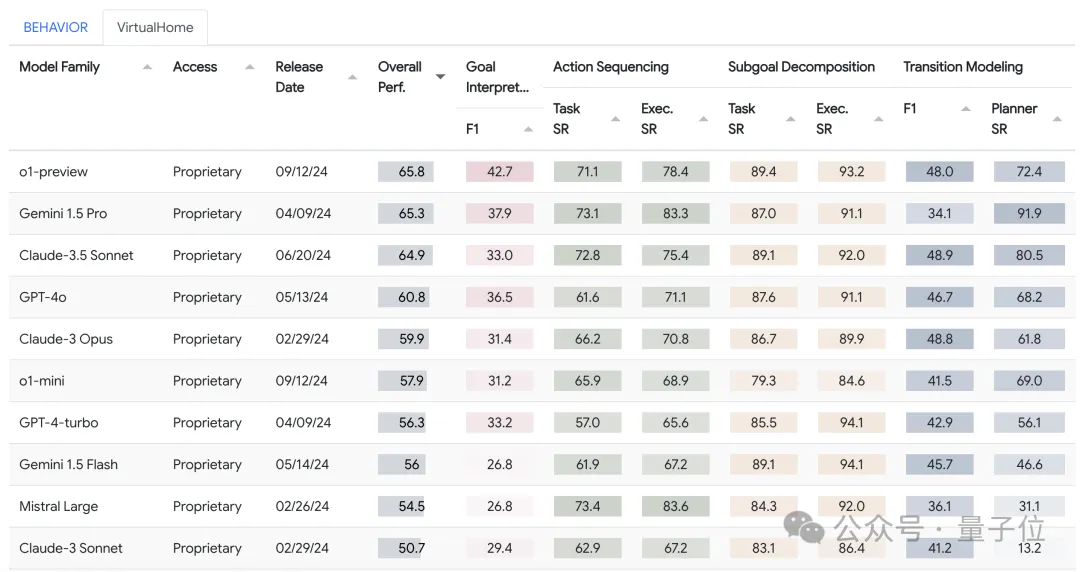
到了VirtualHome环境下,依然是o1-preview领先,但前三名的成绩相对接近。
同时Gemini 1.5 Pro变成了第二名,不过整体来看排行靠前的几个模型和BEHAVIOR环境类似。
当然如果比较单项能力,不同模型也体现出了各自不同的优势项目。
比如在BEHAVIOR环境中,总分排第二的Claude 3.5 Sonnet,目标解释能力略高于总分排第一的o1-preview。
在VirtualHome环境中,总分相对靠后的Mistral Large,在动作序列规划上取得了第一名。
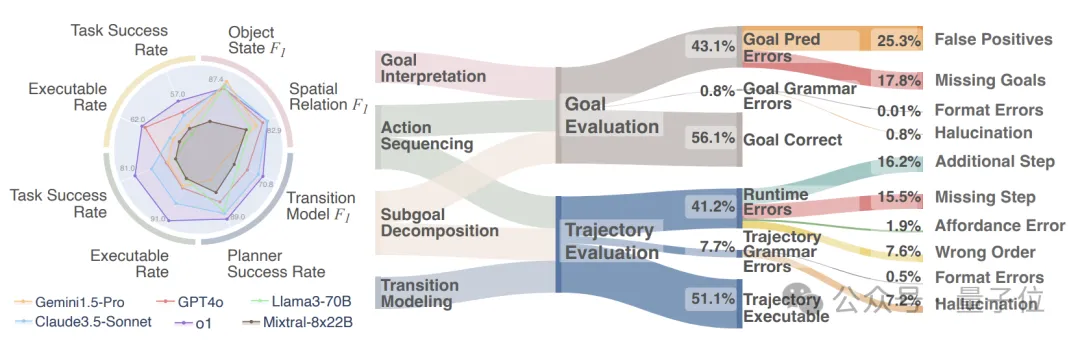
作者还对各模型的失败情况进行了深入分析,发现了将中间状态误识别为最终目标状态、对隐含的物理关系理解不足、忽略重要的前提条件等具体问题。
这些发现能够让研究人员对模型的优缺陷进行更深层的了解,为之后的研究提供了重要参考。
项目主页:
https://embodied-agent-interface.github.io/
论文:
https://arxiv.org/abs/2410.07166
代码:
https://github.com/embodied-agent-interface/embodied-agent-interface
数据集:
https://huggingface.co/datasets/Inevitablevalor/EmbodiedAgentInterface
- Claude网页版接入MCP!10款应用一键调用,开发者30分钟可创建新集成2025-05-02
- 1450亿!马斯克xAI与X合并后再寻资金,将成史上第二大初创企业单轮融资2025-04-27
- 挤爆字节服务器的Agent到底啥水平?一手实测来了2025-04-23
- 电视装了智能体,只凭台词就能找到剧集了2025-04-24