
把Runway、Luma们一锅端了!这款视频模型上“杀手级”功能:一致性魔咒终于打破
视频模型拥有了“上下文记忆”
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
三张图攒一个毫无违和感的视频!

视频模型领域又沸腾了!
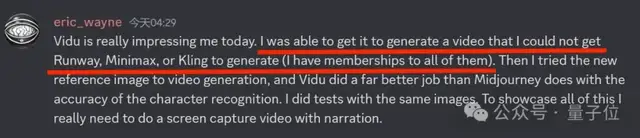
把Runway、LumaAI等一众视频模型都一锅端了。海外用户评价,一众视频模型都实现不了的能力,它竟然给攻破了,甚至在语义理解甚至比图像模型王者Midjorney还强。
这背后就是国产视频模型Vidu——全球最早对标Sora发布的视频模型。昨天新上的“杀手级”功能:多主体一致性。(传送门:www.vidu.studio)
这个功能上周六Vidu就在X上偷偷预热了,昨天正式上线。简单讲,这个功能支持上传1~3张参照,来实现对多主体的控制。
以官方发布的demo为例,丢入“黑人男子、机甲、城市街景”三张图,Vidu 能提取主体、服装、场景,将三者无缝融合, 输出一段“男子穿着机甲走在城市街道”的视频内容。

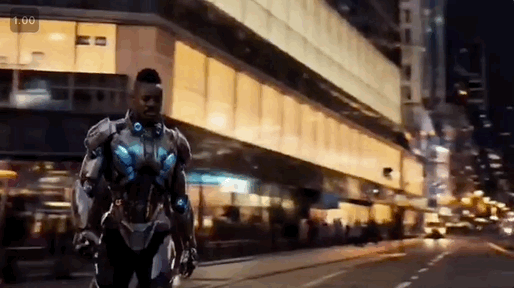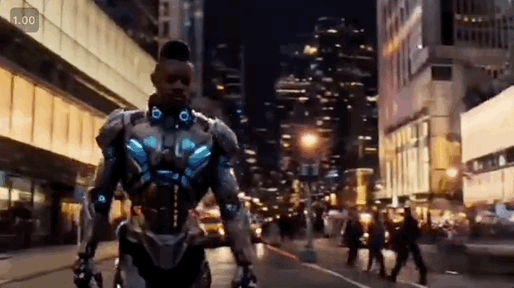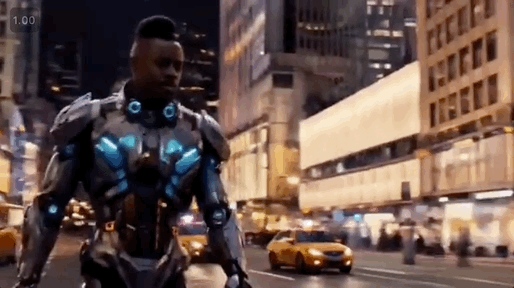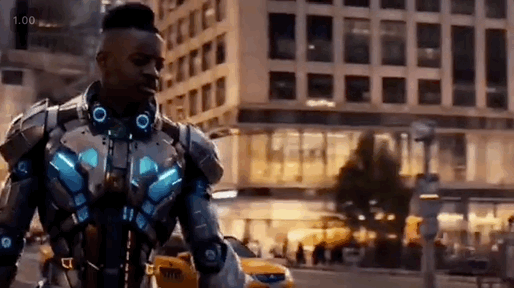
想不到啊!要知道,之前的视频模型理解一段promot都费劲,需要来回抽卡,现在用Vidu生成视频,已经可以跟写作文似的,明确地点、人物、行为、形象,就能实现精准控制和编辑。
海外用户更是直呼“改变了游戏规则”,未来“只要上传一张角色图+一张环境图”就可以创作连续的视频故事。


比如有用户上传一个女战士的形象图+战场场面,就可以生成堪称史诗级的战争画面。


更有上难度的,直接上群像图,一次上传十个主体(拼图放一块),让Vidu生成一段视频,但显然,这都没有难倒它。


这瞅着感觉以后生成水浒传108将群像也不是不可能嗷!
一致性魔咒,难死一众高手
前面提到,这是目前Runway、Luma AI等全球一众高手都不具备的能力,在功能层面,上述几家都仅仅支持单图输入。这背后其实就是“一致性控制”问题。
这是视频模型的老大难问题,在吐出生成结果的时候,模型往往难以确保主体(无论是人物还是物体)的外观、特征、风格保持一致。
你给它清秀小帅哥,秒变可怖伏地魔那是常有的事。
尤其是一上难度,涉及多主体时,模型更是很难对多个主体同时进行控制,更别提主体间还要保持自然连贯的交互。
就,脑壳痛。

不过这一“世纪难题”现在被Vidu 完美解决了!Attention please!上新期间每人3次免费机会,大家且玩且珍惜。

当然,对于“一致性”问题,Vidu领先业界布局已久。
早在7月底全球上线时,Vidu就推出了“角色一致性”功能,解决人脸一致性问题,对比看,近期可灵1.5刚上线人脸一致性功能。
在9月初,Vidu又全球首发了“主体一致性”功能,允许用户上传任意主体的一张图片,从“人脸一致”拓展到“主体一致”,例如人物的全身一致,不再局限于人脸,甚至动物、商品的一致性保持也不在话下。
短短两个月,Vidu又又又升级了,能实现对单主体的多角度一致,也能实现多主体交互控制、主体与场景融合控制。
如何正确打开(指南宝典)
废话不多说,上指南宝典。Vidu的打开如下:
单主体的一致性视频生成
首先单主体场景。
通过上传特定主体的不同角度或不同景别下的图片,能够能实现对单主体的100%精准控制。
具体来说,第一点是对复杂主体的精准控制。
那就上传几张欧洲古典美女玩玩吧(doge):

难点可不仅是还原少女的美貌,还有她的头饰、发型、服饰十分复杂,模型很容易犯脱离图片“自行脑补”的灾难。
但在Vidu生成的中景镜头视频中,美女姐姐转个圈圈(涉及背后、侧面视角),不同视角下,角色形象始终如一,保持得挺好。

不单单真实人物,这一能力对3D动画形象来说,通过上传三视图简直是手拿把掐。


第二点是人物面部特征和动态表情的自然一致。
通过上传多张人物特写图,Vidu能够确保人物面部的特征细节和表情变化自然流畅,不会出现面部僵硬或失真的现象。
这次的模特,有请这位小朋友。

从笑容转换到垂眸失落,过度自然,也没有失真:

多主体生成
这次新功能更妙的是能上传多个主体,实现多主体的一致性控制(业内独家)。
多个主体的组合,可以是人物+人物,也可以是人物+场景、人物+道具等,甚至是人物+道具+场景,并在视频生成中实现这些元素的自然交互。
首先是多主体交互,用户可以上传多个自定义角色,让它们在指定空间内进行交互。何不试试让AI界奥特曼和光之巨人迪伽奥特曼同框出镜?
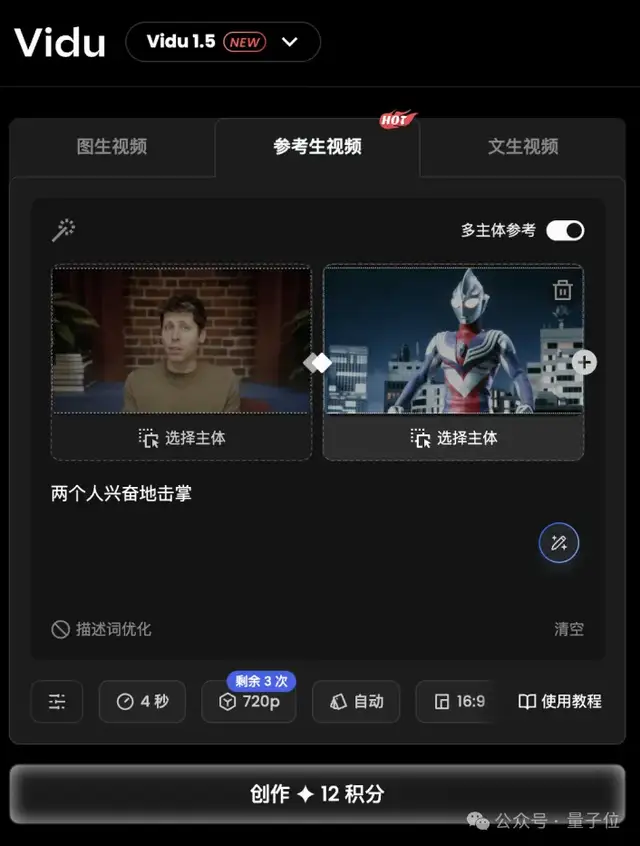
然后奥特曼届的名场面就此诞生:

这里还可以是融合不同主体特征,比如人脸融合,将角色A的正面与角色B的反面无缝融合。
试试穿10号球衣的马斯克。这简直是一键AI换脸神器!


也可以是人物+道具 ,比如试试给人物换装,让马斯克穿礼服。很好……


终极难度就是,人物+道具+场景,用户可以上传主体、客体和环境的图片,创建定制角色身穿特定服装、在定制空间内自由动作的场景。
比如丢给它一张马斯克帅照、一件东北花袄、一辆电动小摩托,输入prompt:
男人穿着花袄在游乐园骑电动车。
他立马就开心得像个五十几岁的大男孩:

这视频来看,道具师、服装师可以双双下线了……
如果不走搞笑路线,来个正经的。这特效效果不止一点点震撼。


必须要提的一点是,以上这些能力的实现并不来自业界主流的LoRA(Low-Rank Adaptation)微调方案。
简单理解,过往的视频模型如果想实现上述换装、人脸融合等场景能力,均需要针对每一个场景设计进行微调。
LoRA效果虽不错,但通常需要20~100段视频,数据构造繁琐,且需要数小时甚至更久的训练时间成本为单次视频生成的成百上千倍;另外LoRA微调模型容易产生过拟合,导致对于动态的表情或肢体动作的变化,很难有效控制。
但Vidu选择在自身通用架构上持续迭代升级,通过提升基础模型带来更泛化的能力,无需专门的数据采集、数据标注、微调训练环节。
仅靠三张图就实现高可控的稳定输出,直接省去LoRA“炼丹”。好家伙,LoRA终结器嘛这不是!
视频模型拥有了“上下文记忆”
Vidu背后的研发团队生数科技也放出了技术架构的介绍,所谓统一化架构:
- 统一问题形式:将所有问题统一为(视觉输入,视觉输出);
- 统一架构:均用单个网络统一建模变长的输入和输出;
- 压缩即智能:从视频数据的压缩中获取智能。
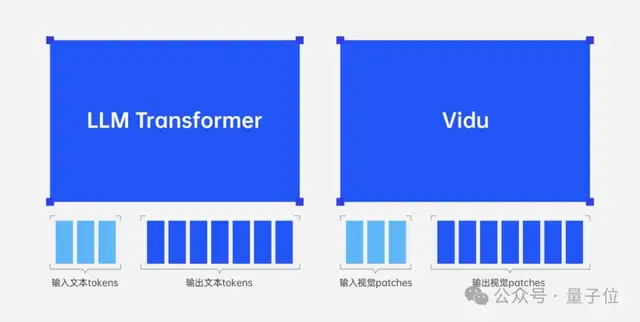
△图注:LLM和Vidu技术架构方案对比
细品,这不就是和LLM一致的“设计哲学”:将所有问题统一为简单输入输出,从压缩中获取智能,同样单个网络统一建模变长的输入和输出。
一旦接受了这个设定,再细品看,想必我们想到了同样的一个类似事件:ChatGPT的智能涌现。
相较于GPT-2、GPT-3,初代ChatGPT背后GPT-3.5之所以能够一炮轰出个AI新时代,正是因为OpenAI在其基础模型上大花功夫,带来通用模型能力的提升。
从开始的预训练+微调的路径,伴随不断的Scaling Up,最终基于一个通用基础模型实现泛化能力。
Vidu的提出让我们看到了,视频模型的训练范式也从“预训练+微调”的路径升级到了通用化的统一架构,并在任务层面实现泛化。
另外还有一点,则是上下文理解能力方面,GPT-3.5能够更好地处理复杂的指令和问题,理解更长的上下文信息,通过关联前后的文本、识别语句之间的关系,生成连贯且符合情境的回答或内容。
有意思的是,在Vidu这儿,我们也看到了“上下文记忆”能力。
此次升级,从单图输入到输入多张参考图像,Vidu能够理解多个输入图像的准确含义和它们之间的关联性,以及能够根据这些信息生成一致、连贯且有逻辑的输出。

这与大语言模型的“上下文学习”(In-Context Learning)能力具有显著相似性,通过上下文学习基于少量的示例或提示快速适应新任务。
至此,Vidu不再仅仅是从文本到视频的渲染工具,不仅仅具备了理解和想象的能力,还能够在生成过程中对上下文信息进行记忆管理。
曾经大语言模型的独有优势,现在在视觉模型中也得以体现。
视觉模型也出现了和语言模型一样的“大跨越”,AGI版图里的一块重要拼图,正在加速进化中。
传送门:www.vidu.studio
- 陶哲轩DeepMind梦幻联动,最强通用科学Agent来了!一口气解决芯片设计、矩阵乘法和300年几何难题2025-05-15
- GPT-4o不敌Qwen,无一模型及格!UC伯克利港大等提出多模态新基准2025-05-14
- 陶哲轩油管首秀:33分钟,AI速证「人类需要写满一页纸」的证明2025-05-12
- 蚂蚁数科企业级AI产品全线出海,首次在海外市场展现全栈产品矩阵2025-05-14











