用LLM一键生成百万级领域知识图谱!中科大新框架入选ACL 2024
以ChatGPT为基础模型,相比SOTA方法提升了20%
现在,用LLM一键就能生成百万级领域知识图谱了?!
来自中科大MIRA实验室研究人员提出一种通用的自动化知识图谱构建新框架SAC-KG,提升效果be like:
当使用ChatGPT作为基础模型时,SAC-KG达到了89.32%的准确率和81.25%的领域特异性,相对于SOTA方法提升了20%。

一直以来,知识图谱构建技术始终是研究热点。
不过对构建领域知识图谱来说,由于需要大量的专家知识和人工干预,其实际应用受到严重限制。
对此,最近基于大语言模型(LLM)的构建方法成为了一种新趋势。但仍存在一些问题,严重影响所构建领域知识图谱的可信度。
针对上述痛点,研究团队进一步提出了SAC-KG,相关论文已发表在CCF-A类人工智能顶级会议ACL 2024 Main。并开发部署领域知识图谱自动构建平台SAC-KG,支持输入大规模领域语料,一键生成高质量领域知识图谱。
SAC-KG是如何工作的
由于大语言模型出色的语义理解能力和生成能力,基于LLM的方法成为了一种新趋势。通过利用LLM中存储的先验知识,从原始语料中提取三元组。
然而,基于LLM的方法仍面临一些问题。输入中的上下文噪声和输出中的知识幻觉会导致错误或不相关的三元组生成,从而严重影响所构建领域知识图谱的可信度。
为了解决上述问题,该研究提出了一种全新的自动化知识图谱构建通用框架SAC-KG,利用大语言模型作为领域知识图谱的自动化构建专家,在给定领域语料的情况下,以自动化、精确性和可控性为目标提取三元组。
该框架包含三个组件:生成器、验证器和剪枝器。
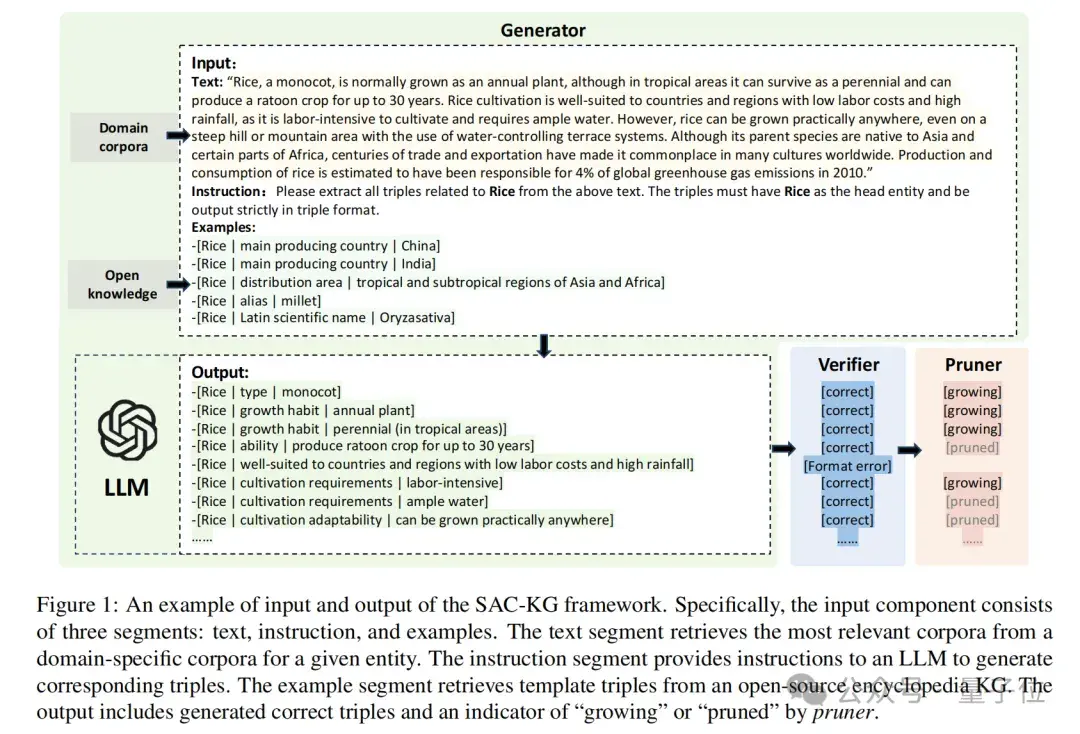
生成器
首先,生成器包括领域语料检索器和开放知识图谱检索器,分别为指定的实体从领域语料库和开放知识图谱中检索最相关信息。
其中,领域语料检索器提供最相关的文本语料作为LLM的输入,减少上下文噪声的引入;开放知识图谱检索器提供与实体最相关的三元组作为示例,帮助控制模型的输出格式。
LLM的输入包括与实体相关的上下文、三元组示例以及相应的提示,输出为生成的以指定实体为头实体的三元组。
验证器
由于LLM存在知识幻觉,可能生成错误三元组,因此由验证器负责检测并过滤掉由LLM生成的错误三元组。
这一过程分为两个步骤:错误检测和错误纠正。
在错误检测阶段,验证器会执行三种检查并进行标记:
- 数量检查:如果生成的三元组数量少于阈值(默认是3个),则标记为“数量不足”。
- 格式检查:如果三元组不符合预定义格式,则标记为“格式错误”;如果头实体不匹配预定义实体,则标记为“头实体错误”;如果头实体和尾实体相同,则标记为“头尾矛盾”。
- 冲突检查:验证器会检测三元组中的逻辑冲突。例如,确保一个人的出生时间早于死亡时间,且年龄不为负数。
在错误纠正阶段,根据检测到的错误类型提供相应的提示,并重新让LLM生成正确的输出。例如,如果是“格式错误”,会提示模型“请严格按照格式要求重新生成,注意三元组的格式”。
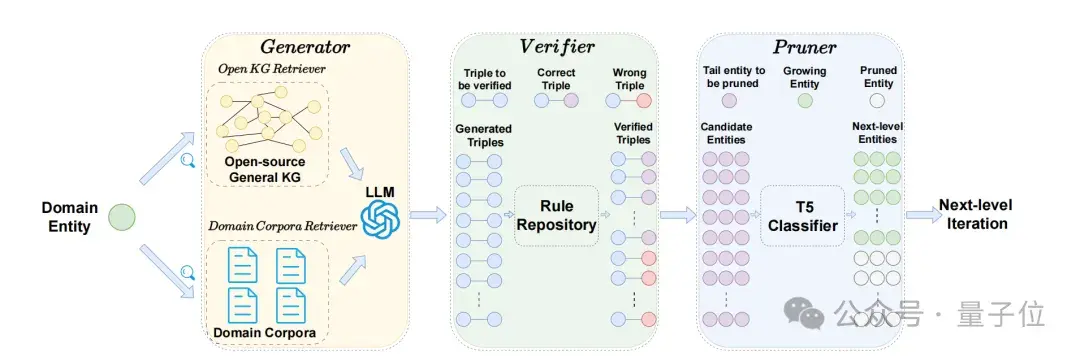
剪枝器
知识图谱的生长过程可以看作一棵树的逐层增长,从浅到深逐步获取领域知识,意味着下一层三元组的头实体是上一层三元组的尾实体。
在经过验证器验证后,将得到的正确三元组整合到生成的新层图谱中,并继续生成下一层三元组。
然而,并不是所有三元组都需要继续生成下一层。例如,“(稻米,最佳生长温度,20-25摄⽒度)”是正确的三元组,但尾实体“20-25摄氏度”不需要作为下一层的头实体进行进一步生成。
为了提高知识图谱的可控性,该研究引入剪枝器,这是一个在开源知识图谱DBpedia上微调的T5二分类模型。输入为每个正确三元组的尾实体,输出为“生长”或“修剪”,表示是否需要继续生成下一层图谱。
训练剪枝器时,从DBpedia收集训练数据,将部分头实体作为“生长”类的代表,尾实体则作为“修剪”类的代表。通过这些实体文本和对应标签进行微调。
实验及结果
主实验
在同一领域的知识图谱自动构建中,研究团队使用GPT-4进行自动和高效的评估。
如表1所示,SAC-KG表现优异,超越了多个基线模型。
四个基线模型包括OpenIE6、StanfordOIE、DeepEx和PIVE,其中前两者为基于规则的三元组抽取方法,而DeepEx结合了Bert模型与规则技术,PIVE则直接使用ChatGPT构建知识图谱。
SAC-KG在知识图谱构建上始终优于这些方法,尤其在准确率和领域特异性上表现突出。
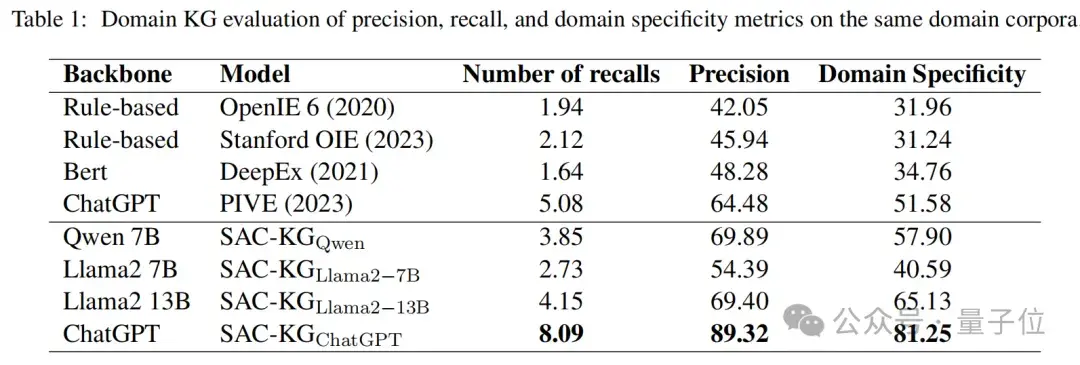
当使用ChatGPT作为基础模型时,SAC-KG达到了89.32%的准确率和81.25%的领域特异性,显著优于基于规则的方法,相对于SOTA方法提升了20%。
消融实验
消融实验中,研究团队每次迭代中计算这些指标,以获得更细致的结果。
他们将没有开放知识图谱检索器的SAC-KG记作SAC-KGw/oprompt,没有领域语料检索器的记作SAC-KGw/otext,没有验证器的记作SAC-KGw/overifier,没有修剪器的记作SAC-KGw/opruner。
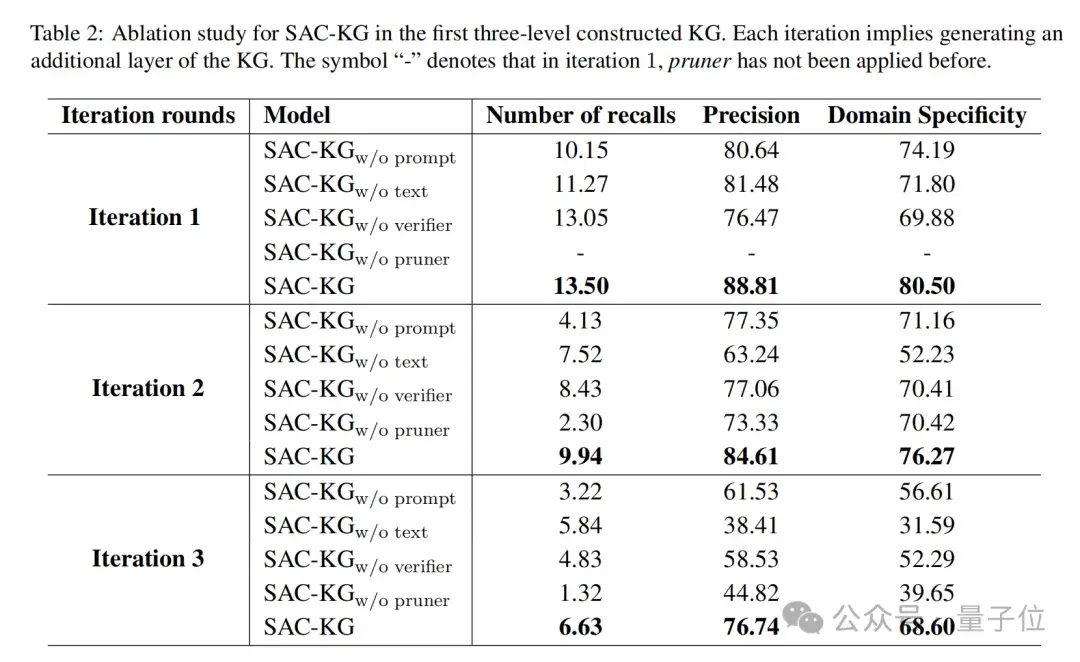
如表2所示,SAC-KG中的任一组件缺失都会导致整个框架性能下降。
特别是,修剪器和开放知识图谱检索器对SAC-KG的性能影响更为显著。这两个组件分别控制生成方向和添加示例,表明在知识图谱构建过程中提升可控性的重要性。

研究团队进一步可视化了SAC-KG每个消融版本生成的前三层知识图谱。如图所示,完整的SAC-KG版本表现出最佳的整体结果,且每一层中的错误三元组数量没有显著差异。这一现象表明,在领域知识图谱的迭代生成过程中,错误传播并不明显。相反,去除了文本处理模块(SAC-KGw/o text)和剪枝模块(SAC-KGw/o pruner)的版本显示出明显的错误传播,导致在第三层生成的错误三元组数量显著增加。而去除了提示模块(SAC-KGw/o prompt)和验证模块(SAC-KGw/o verifier)的版本仅能提取较少的三元组,这意味着语言模型在缺乏示例和错误纠正过程的情况下难以从领域语料中总结知识。这些结果进一步证实了框架内每个组件对构建过程的重要贡献。
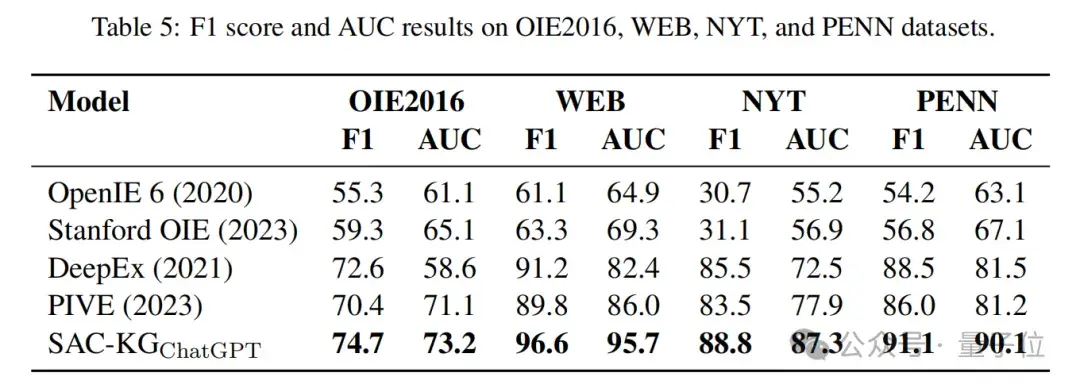
OIEbenchmarks
SAC-KG在传统的开放信息抽取任务中的有效性和广泛适用性通过多个开源基准数据集的实验得到了验证。
实验结果显示,SAC-KG在这些传统OIE基准数据集上,显著优于现有的最先进方法。
特别是,在与基于规则的方法(如OpenIE6和StanfordOIE)和基于大规模语言模型的方法(如DeepEx和PIVE)的比较中,SAC-KG始终达到最佳结果,证明了其在传统OIE任务中的有效性和鲁棒性。
小结
针对大规模领域知识图谱构建成本高、精度低这一复杂的实际问题,本研究提出了基于大模型的迭代式领域/常识图谱通用构建框架。
该框架实现了多源领域语料中的精准知识检索,并结合开源图谱实现了自适应提示机制,通过模拟树生长过程,成功构建了百万级的高质量领域图谱。
论文发表在CCF-A类人工智能顶级会议Annual Meeting of the Associationfor Computational Linguistics(ACL 2024 Main)。
论文作者第一作者陈瀚铸是中国科学技术大学2021级硕博连读生,师从王杰教授,主要研究方向为知识图谱与大语言模型,数据合成等。曾获KDDCup全球高校团队第一等荣誉。
- 轻松健康集团高玉石:AI产品和用户走得够近才能挖到新需求丨中国AIGC产业峰会2025-04-23
- AI火花集|10位AI火花先锋揭晓,看AI应用如何“改写”商业世界?2025-04-17
- 中杯o3成OpenAI“性价比之王”?ARC-AGI测试结果出炉:得分翻倍、成本仅1/202025-04-23
- 人形机器人半马冠军,为什么会选择全尺寸?2025-04-20