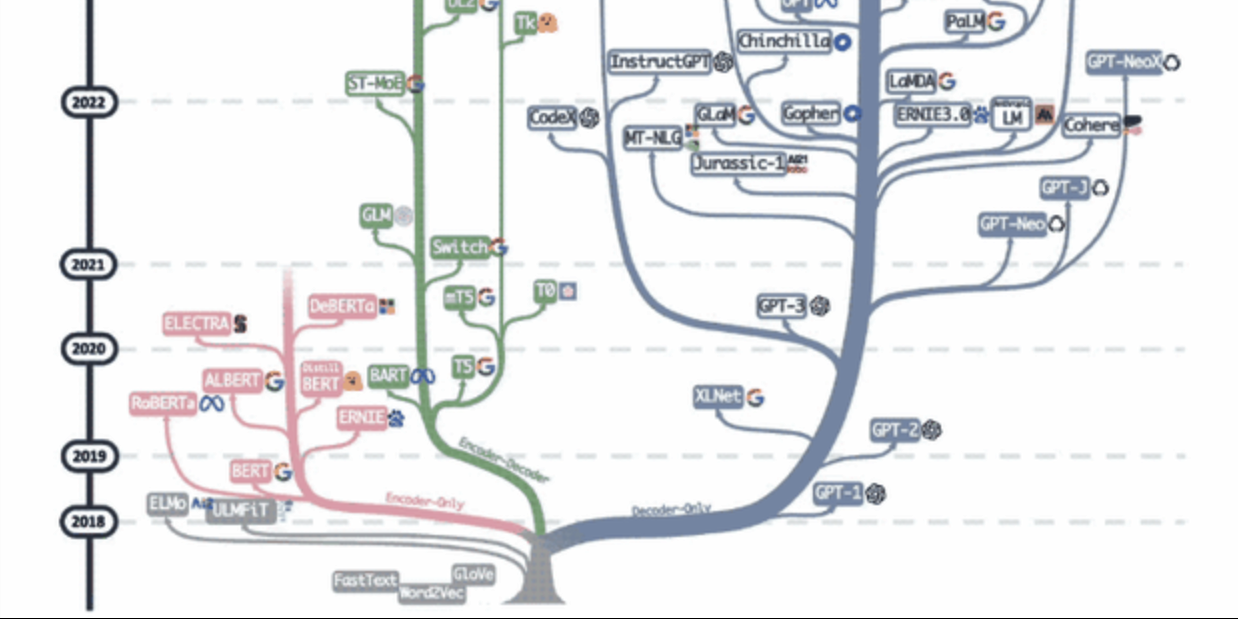
智源举办2024具身与世界模型专题峰会,产学研共促技术创新与产业应用
探索具身端到端以及大小脑分层结构的不同技术路线
允中 发自 凹非寺
量子位 | 公众号 QbitAI
2024年11月5日,北京智源人工智能研究院主办的“智源论坛·2024具身与世界模型专题峰会”在智源大厦举行,智源研究院理事长黄铁军、智源研究院院长王仲远、智源研究院副院长林咏华出席大会。

智源具身多模态大模型研究中心负责人、北京大学研究员仉尚航,智源具身智能研究中心负责人、北京大学助理教授、银河通用创始人王鹤,Google DeepMind研究科学家,谷歌RT1、2,SayCan作者Ted Xiao以及来自清华大学、香港大学、康奈尔大学、UC Berkeley、英国曼彻斯特大学、大湾区大学(筹),中国科学院等知名高校和研究机构的学者专家,加速进化、傅利叶、乐聚机器人、星尘智能等具身智能头部企业的创始人、CEO围绕具身智能和世界模型的前沿方向、技术实践进行了主题分享与深度探讨。

具身智能的发展,无论是硬件稳定性,数据采集与仿真,具身大小脑模型分层架构或者端到端技术路线,还是终端使用场景,都面临诸多挑战,需要产学研深度协同与广泛联动。
智源研究院院长王仲远在开幕式致辞中表示,智源研究院将依托多模态大模型技术优势资源,联合北大、清华、中科院等高校院所以及银河通用、乐聚、加速进化、宇树等产业链上下游企业,建设具身智能创新平台,重点开展数据、模型、场景验证等研究,共同打造具身智能创新生态。
智源具身多模态大模型研究中心创新地设计了面向机器人具身基础模型的快慢系统框架,快系统能够高效快速的预测末端执行器位姿,慢系统则是在面对复杂和错误行为时更加深入地思考和纠错,不断提升机器人大脑的能力。
为了实现该快慢系统框架,智源探索了具身端到端以及大小脑分层结构的不同技术路线,进行开放世界泛化物体操作,并基于大脑模型进行语义理解与常识推理,实现零样本物体导航。
无论是端到端模型还是分层结构,最终都是为了让机器人能更好地理解物理世界规律,更好地与环境交互,更好地执行时序上的准确行为。因此,智源同时提出了四维世界模型Robo4D,为世界模型构建四维时空,以解决机器人在开放世界中任务操作的物体泛化以及场景泛化等问题。
相关研究被国际旗舰会议NeurIPS 2024、ICML 2024接收。
智源具身多模态大模型研究中心利用世界模型预测机器人与环境交互后的未来事件,从而生成准确的行为,提前预测行为是正确还是失败。智源设计的世界模型的技术路径是,首先将世界模型启动和响应模态设置为视频模态,给定关于动作的语言指令和当前机器人的状态去生成机器人执行完动作后的完整视频。
针对给定的任务,模型可以完整预测任务执行的过程,从物理世界中学习规律,生成视频之后,通过模型将视频转换成机器人的行动。其中,任务到视频生成以及视频到行动的过程,利用了智源原生多模态世界模型Emu3将理解和生成大一统的技术思路,形成自我反思的思维链。

智源具身多模态大模型研究中心负责人仉尚航认为,近期的一系列工作展现出具身基础模型的广泛前景,中心将继续探索具身多模态大模型与大数据构建,践行机器人领域的Scaling Law。实现真实世界的四维时空世界模型是迈向机器人整体AGI的重要一步。四维世界模型将作为机器人的世界基础模拟器,同时具备时间与空间智能,拥有长短期记忆与物理概念学习等能力,与真实物理世界进行交互并从中得到反馈。
智源具身多模态大模型研究中心在近期的研究中将世界模型从二维拓展至四维,采用先验引导的3D Gaussian Splatting算法,基于单一视角的视频片段生成四维世界空间。采用多轮世界空间映射模型将不同位置的世界空间映射到视频域,最终应用于下游任务,生成式数据提升了机器人操作的泛化性。

智源具身智能研究中心负责人、北京大学助理教授、银河通用创始人王鹤在特邀报告中强调,空间智能要注重三维信息的使用,否则对空间几何的理解非常有限,还需注重交互智能,而交互智能背后所需的大量数据应该用合成数据替代真实世界的数据采集,才能达到大模型所需要的数据规模,实现真正的泛化性。
目前,智源具身智能研究中心展开了一系列技能的泛化研究和具身端到端大模型的训练研究。
首先把二维真实世界看到的二维图像升维到三维,用扩散模型预测视差。并自研了大规模动作数据的仿真合成技术,覆盖了桌面物体摆放、桌面纹理、光照等各种空间形态和位置关系,在仿真器中对光线折射和反射进行仿真并进行渲染。
目前团队最新的进展是完成了10亿规模的灵巧抓取数据集DexGraspNet 2.0,覆盖了基于各种物体的大规模的抓取标签生成,在这样的大规模数据上训练的灵巧手抓取模型率先实现了泛化场景真机成功率90%以上。
在端到端模型研发方面,团队训练了全球首个基于视频流的端到端导航大模型NaVid,无需建图,也不依赖于深度信息和里程计信息等其它传感器信号,完全依靠机器人摄像头采集的单视角RGB视频流,通过Sim2Real的方式,实现在真实世界室内场景甚至是室外场景的zero-shot真机泛化。
近期,智源在导航大模型加入了三维模态,提出了端到端空间导航大模型NaVid-4D,该模型在一系列有更高要求的自然语言指令导航任务中实现了进一步突破。

大会期间,智源研究院院长王仲远主持具身智能技术与应用发展前沿展望圆桌讨论,清华大学自动化系教授,加速进化联合创始人赵明国,智源具身智能研究中心负责人、北京大学助理教授、银河通用创始人王鹤、傅利叶创始人兼CEO顾捷,乐聚创始人冷晓琨,中科院自动化所研究员王鹏,UC Berkeley潘家怡,围绕具身智能的本体形态、数据、泛化能力、产业落地前景等议题分享了最新的思考与观察。

此外,下午的空间智能和世界模型圆桌讨论由智源研究院副院长林咏华主持,清华大学机械工程系助理研究员陈睿,清华大学电子工程系副教授代季峰,星尘智能创始人兼CEO来杰,香港大学助理教授李弘扬 ,北京通用人工智能研究院研究科学家黄思远,分别就机器人的世界模型技术路线、关键技术要点以及面临的核心挑战等问题进行了不同视角的解读。

在闭幕致辞中,智源研究院理事长黄铁军指出,智能是环境的产物。人类智能来源于对环境的适应演化以及对世界的抽象。智能应该是大大小小各种形态的,不能变成一个完全统一的智能。具身智能的发展是必然趋势,无论是人形还是其他形态的机器人,未来需要庞大的产业群配套,促进具身智能的关键部件与材料,软件与硬件协同发展。
- 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品2025-04-14
- 4090玩转大场景几何重建,RGB渲染和几何精度达SOTA|上海AI Lab&西工大新研究2025-04-13
- 阿里云造“Agent工厂”,百炼MCP服务上线,无需代码5分钟建Agent2025-04-09
- 又一上海人形机器人加入开源!全套图纸+代码,来自傅利叶2025-04-11