
腾讯发最大开源MoE模型,3890亿参数免费可商用,跑分超Llama3.1
与混元大模型“同宗同源”
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
腾讯拿出看家本领,来挤开源赛道,突然发布了市面上最大的开源MoE模型。
Hunyuan-Large,3890亿总参数,520亿激活参数。
跑分超过Llama 3.1 405B等开源旗舰,上下文长度支持也高出一档来到256k。

虽然Hunyuan-Large还不算腾讯内部的旗舰模型,但腾讯介绍底层技术与混元大模型“同宗同源”:
很多细节都是内部业务打磨好再开源出来的,比如用到了腾讯元宝App的AI长文阅读等功能里。
现在这样的一个模型彻底开源,免费可商用,算是很有诚意了。

这次腾讯Hunyuan-Large总共开源了三个版本:预训练模型、微调模型、FP8量化的微调模型。
在开源社区掀起一阵热议,HuggingFace首席科学家Thomas Wolf墙裂推荐并总结了几个亮点。
- 数学能力很强
- 用了很多精心制作的合成数据
- 深入探索了MoE训练,使用共享专家、总结了MoE的Scaling Law。

各路开发者中,有立马开始下载部署的动手派,也有人希望腾讯入局后,开源模型卷起来能迫使Meta造出更好的模型。
这次腾讯同步发布了技术报告,其中很多技术细节也引起讨论。
如计算了MoE的Scaling Law公式,C ≈ 9.59ND + 2.3 ×108D。
又比如用交叉层注意力节省KV缓存的内存占用。

下面送上发布会现场演讲和技术报告精华内容总结。
Hunyuan-Large技术报告
MoE的Scaling Law
直接上公式:
C ≈ 9.59ND + 2.3 × 108D
其中C表示计算预算(单位FLOPs),N表示激活参数数量,D表示训练数据量(单位tokens)。
与传统密集模型的计算预算公式C=6ND相比,MoE模型公式的差异主要体现在两个方面:
一是系数从6增加到9.59,反映了MoE额外的路由计算开销,包含专家切换的计算成本。
二是增加了常数项2.3×108D,反映了长序列MoE模型attention计算的额外开销。
为了确定最优激活参数量,团队投入大量成本展开实验:
训练一系列激活参数范围从10M到1B的模型,使用最高1000亿tokens的训练数据,覆盖100亿到1000亿tokens的不同数据规模。
使用isoFLOPs曲线,在固定计算预算下寻找最优点,同时考虑实际训练batch size的影响,分析不同参数量和数据量的组合,计算得出最优激活参数量约为58.1B。
而最终Hunyuan-Large选择了52B的激活参数量,主要考虑到最优点附近曲线平滑,在58.1B附近有较大容差空间,以及计算资源约束、训练稳定性要求和部署效率平衡等实践因素。

路由和训练策略
除了揭秘最优参数配比,技术报告中还详解了Hunyuan-Large独特的”MoE心法”。
混合路由策略:
Hunyuan-Large采用共享专家(shared expert)和特殊专家(specialized experts)相结合的混合路由。
每个token激活1个共享专家和1个专门专家,共享专家处理所有token的通用知识,而特殊专家则用top-k路由策略动态激活,负责处理任务相关的特殊能力。
回收路由策略:
传统MoE常因专家超载而丢弃过多tokens。Hunyuan-Large设计了专家回收机制,保持相对均衡的负载,充分利用训练数据,保证模型的训练稳定性和收敛速度。

专家特定学习率适配策略:
不同专家承载的tokens差异巨大,应设定不同学习率,如共享专家使用较大的学习率,确保每个子模型有效地从数据中学习并有助于整体性能。
高质量合成数据
混元团队开发了一套完整的高质量数据合成流程,主要包括四个步骤:指令生成、指令进化、回答生成和回答过滤。
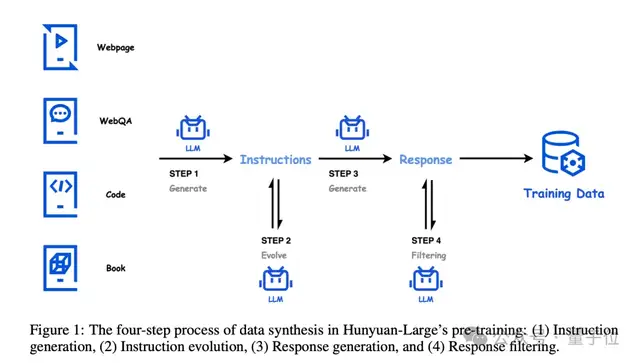
在指令生成阶段,混元团队使用高质量的数据源作为种子,覆盖多个领域和不同复杂度,确保指令的多样性和全面性。
接下来是指令演化阶段,通过提升指令的清晰度和信息量,扩充低资源领域的指令,并逐步提升指令的难度,使得指令更加丰富、精准和具有挑战性。
在回答生成阶段,混元团队采用专门的模型针对不同领域生成专业的答案。这些模型在规模和设计上各有不同,以确保生成的回答能够满足不同领域的要求。
最后是回答过滤阶段,混元团队采用critique模型对生成的回答进行质量评估,并进行自一致性检查,以确保输出的答案是高质量的。
通过这四步合成流程,混元团队能够生成大量高质量、多样化的指令-回答数据对,为MoE模型的训练提供了丰富、优质的数据支持。
这种数据合成方法不仅提高了模型的训练效率,也极大地促进了模型在多种下游任务上的表现。
长文能力优化
为了实现强大的长文本处理能力,混元团队在训练过程中采用了多项策略。
首先是分阶段训练,第一阶段处理32K tokens的文本,第二阶段将文本长度扩展至256K tokens。在每个阶段,都使用约100亿tokens的训练数据,确保模型能够充分学习和适应不同长度的文本。
在训练数据的选择上,25%为自然长文本,如书籍、代码等,以提供真实的长文本样本;其余75%为普通长度的数据。这种数据组合策略确保了模型在获得长文理解能力的同时,也能保持在普通长度文本上的基础处理能力。
此外,为了更好地处理超长序列中的位置信息,混元团队对位置编码进行了优化。他们采用了RoPE位置编码方法,并在256K tokens阶段将base frequency扩展到10亿。这种优化方式能够有效地处理超长序列中的位置信息,提升模型对长文本的理解和生成能力。
除了在公开数据集上进行评测,混元团队还开发了一个名为”企鹅卷轴”的长文本评测数据集。
“企鹅卷轴”包含四个主要任务:信息抽取、信息定位、定性分析和数值推理。

不同于现有的长文本基准测试,”企鹅卷轴”有以下几个优势:
- 数据多样性:”企鹅卷轴”包含了各种真实场景下的长文本,如财务报告、法律文档、学术论文等,最长可达128K tokens。
- 任务全面性:数据集涵盖了多个难度层次的任务,构建了一个全面的长文本处理能力分类体系。
- 对话数据:引入了多轮对话数据,模拟真实的长文本问答场景。
- 多语言支持:提供中英双语数据,满足多语言应用需求。
推理加速优化
为了进一步提升Hunyuan-Large的推理效率,混元团队采用了多种优化技术,其中最关键的是KV Cache压缩。
主要结合了两种方法:GQA(Grouped-Query Attention)和CLA(Cross-Layer Attention)。
GQA通过设置8个KV head组,压缩了head维度的KV cache;而CLA则通过每2层共享KV cache,压缩了层维度的内存占用。
通过这两种策略的组合,混元MoE模型的KV cache内存占用降低了约95%,而模型性能基本保持不变。这种显著的内存优化不仅大幅提升了推理效率,也使得模型更易于部署,适配各种实际应用场景。

后训练优化
预训练的基础上,混元团队采用了两阶段的后训练策略,包括监督微调(SFT)和人类反馈强化学习(RLHF),以进一步提升模型在关键领域的能力和人类对齐程度。
在SFT阶段,混元团队使用了超过100万条高质量数据,覆盖了包括数学、推理、问答、编程等多个关键能力领域。为了确保数据的高质量,团队采用了多重质量控制措施,包括规则筛选、模型筛选和人工审核。整个SFT过程分为3轮,学习率从2e-5衰减到2e-6,以充分利用数据,同时避免过拟合。
在RLHF阶段,混元团队主要采用了两阶段离线和在线DPO结合。离线训练使用预先构建的人类偏好数据集,以增强可控性;在线训练则利用当前策略模型生成多个回复,并用奖励模型选出最佳回复,以提高模型的泛化能力。
同时,他们还使用了指数滑动平均策略,缓解了reward hacking问题,确保了训练过程的平稳和收敛。
One More Thing
在发布会现场,腾讯混元大模型算法负责人康战辉还透露,Hunyuan-Large之后,还会考虑逐步开源中小型号的模型,适应个人开发者、边缘侧开发者的需求。

另外腾讯同期开源的3D大模型可移步这里了解。
- DeepSeek新数学模型刷爆记录!7B小模型自主发现671B模型不会的新技能2025-05-01
- 自动化所:基于科学基础大模型的智能科研平台ScienceOne正式发布2025-04-30
- 小扎回应Llama4对比DeepSeek:榜单有缺陷,等推理模型出来再比2025-04-30
- 蚂蚁数科发布智能体开发平台Agentar 金融机构可“零代码”搭建专业智能体应用2025-04-29










