Llama版o1来了,来自上海AI Lab,强化学习代码已开源,基于AlphaGo Zero范式
上交大团队也有新进展
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
复刻OpenAI o1推理大模型,开源界传来最新进展:
LLaMA版o1项目刚刚发布,来自上海AI Lab团队。
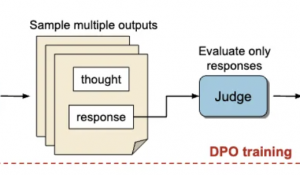
简介中明确:使用了蒙特卡洛树搜索,Self-Play强化学习,PPO,以及AlphaGo Zero的双重策略范式(先验策略+价值评估)。

在2024年6月,o1发布之前,团队就开始探索蒙特卡洛树搜索提高大模型数学能力,积累了一些关注。
这次最新开源代码,也在开发者社区引起热议。
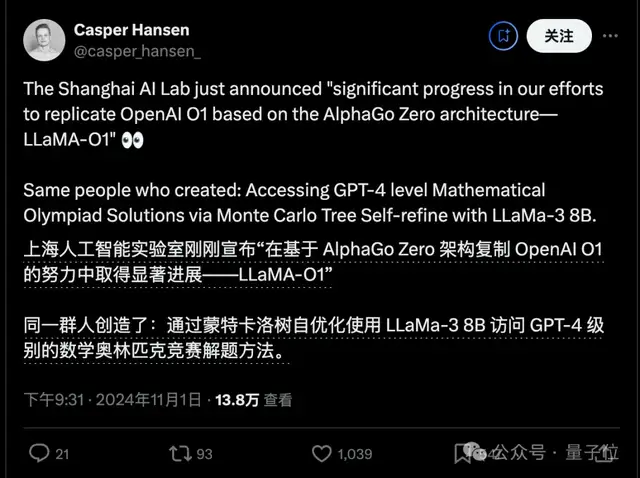
OpenAI o1系列发布后,团队开始升级算法,专注于数学奥赛问题,作为OpenAI草莓项目的开源版本。
10月初,团队上传新论文,使用成对优化(不直接给出绝对分数,而是比较两个答案的相对优劣)提高Llama模型数学奥赛能力。
在最难的AIME2024基准测试30道题中,原版LLaMA-3.1-8B-Instruct做对2道,优化后做对8道,超过了除o1-preview和o1-mini之外的其他商业闭源方案。

10月底,团队宣布在基于AlphaGo Zero架构复刻OpenAI o1的努力中取得了重大进展:
已成功使模型在学习过程中通过与搜索树交互获得高级思维能力,无需人工标注。
不到一周时间,项目便开源了。

LLaMA版o1最新进展
目前已开源内容包括:预训练数据集、 预训练模型、强化学习训练代码。
OpenLongCoT-Pretrain数据集,包含10万+条长思维链数据。
每条数据包含一个完整的数学问题推理过程,包含思考内容和评分结果。
例如一个几何问题,包含了问题描述、图形坐标、计算过程和结论推导等完整的推理链路,以及对各个推理步骤的批评和验证内容,对推理过程进行评价和指导。

在此数据集继续预训练后,模型可读取和输出类似o1的长思维链过程。
预训练代码尚未发布,目前推荐使用LLaMaFactory代替。
有意思的是虽然项目名为LLaMA-O1,但目前官方给的预训练模型基于谷歌Gemma 2。

目前在预训练模型基础上,可以继续进行强化学习训练,从代码中可以看出训练过程如下:
- 使用蒙特卡洛树搜索进行自我对弈(self-play)以生成经验
- 将经验存储在优先经验回放缓冲区中
- 从缓冲区采样批次数据进行训练
- 更新模型参数和经验优先级
论文中也给出了训练过程的图示。
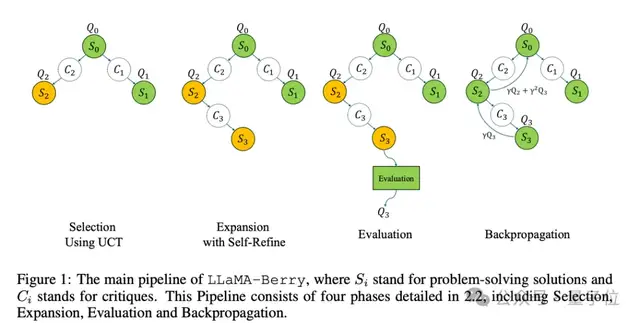
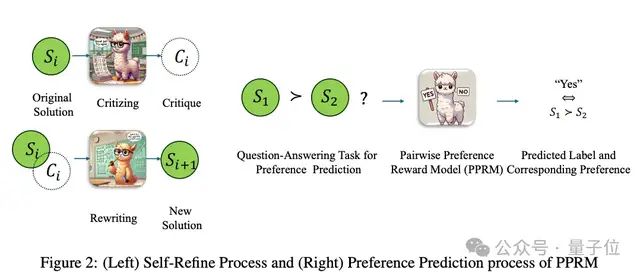
同时训练代码中使用了以下关键技术点:
- 使用LoRA进行参数高效微调
- 使用PPO算法作为策略优化方法
- 实现了GAE(Generalized Advantage Estimation)算法用于计算优势函数
- 使用优先经验回放提高训练效率
最后,LLaMA-O1代码发布在名为SimpleBerry的GitHub账号下,并没有特别简介,还比较神秘。
其他与SimpleBerry有关的账号和官网中,只能看出性质是一个研究实验室,也并未透露更多研究方向信息。
其他o1复刻项目进展
除LLaMA-O1之外,另一个公开进展的o1复刻项目O1-Journey来自上交大团队。
团队在十月初发布了第一份进展报告,其中介绍了创新Journey Learning范式,以及第一个成功将搜索和学习整合到数学推理中的模型。

O1-Journey核心开发团队主要由上交大大三、大四本科生,以及上交大GAIR实验室(生成式人工智能研究实验室)的一年级博士生组成。
指导教师包括上交大副教授刘鹏飞,姚班校友、斯隆奖得主李远志等。
LLaMA-O1:
https://github.com/SimpleBerry/LLaMA-O1
相关论文:
https://arxiv.org/abs/2406.07394
https://arxiv.org/abs/2410.02884
O1-Journey:
https://github.com/GAIR-NLP/O1-Journey/
- 扩散模型还原被遮挡物体,几张稀疏照片也能”脑补”完整重建交互式3D场景|CVPR’252025-04-23
- 3D高斯泼溅算法大漏洞:数据投毒让GPU显存暴涨70GB,甚至服务器宕机2025-04-22
- PPIO姚欣:让免费成为可能,AI时代开启“提速降费”|中国AIGC产业峰会2025-04-22
- o3/o4-mini幻觉暴增2-3倍!OpenAI官方承认暂无法解释原因2025-04-21