慢思考准确率反降30%!普林斯顿揭示思维链某些任务上失效的秘密
CoT在某些任务上反而会降低模型表现
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
OpenAI o1彻底带火慢思考和思维链(CoT)方法,但CoT在某些任务上反而会降低模型表现。
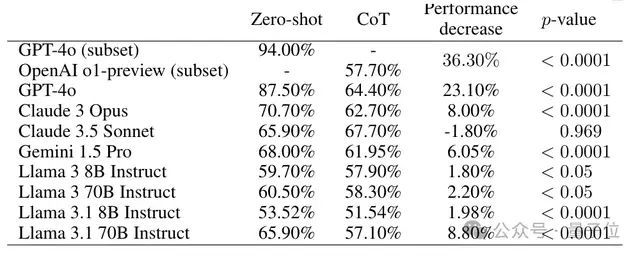
比如给生造的词分类任务,GPT-4在zero-shot提示下的准确率高达94%,换成CoT的准确率却断崖式下跌到64.4%。
内置CoT的o1-preview准确率更是只有57.7%。

CoT究竟会“搞砸”哪些任务,在学术界仍是一个悬而未决的问题。
现在,普林斯顿计算机系与心理系合作,确定了其中一些任务的特征:人类深思熟虑或被要求解释自己的思路时,也会降低在这些任务上的表现。
新论文“一步一步想,但小心脚下”已上传到arXiv。

心理学探索思维链掉链子原因
为了缩小要探索的范围,团队在CoT提示和人类进行语言思考之间进行了类比。
大模型和人类具能力有着根本不同,因此影响表现的约束因素也不同。如大模型的上下文长度很长,远远超出了人类的记忆限制。
因此,团队预计CoT将在以下情况下损害模型性能:
(i) 深思熟虑会损害人类的表现
(ii) 影响人类在任务上表现的约束条件,可以普遍性地推广到大模型。
在实验中,选择了心理学文献中的6项任务,其中隐式统计学习、面部识别、包含异常的数据分类符合假设条件。
隐式统计学习(Implicit Statistical Learning)
心理学研究发现,当包含统计模式的数据不用语言来描述时,人类可以更好地概括这些数据。
使用有限状态语法构建“人造单词”,参与者的任务是识别哪些单词属于同一类别。
人类参与者可以识别格式不正确的序列,但无法用语言表达他们判断的基础。

在几个开源和闭源模型上评估这项任务,发现与zero-shot提示相比,使用CoT提示时性能大幅降低。
面部识别(Facial Recognition)
另一类任务中语言思考会干扰视觉感知,称为语言遮蔽(verbal overshadowing)。
在实验中选用了经典的人脸识别任务,首先展示一个人脸照片,要求参与者从候选列表中找出同一个人。
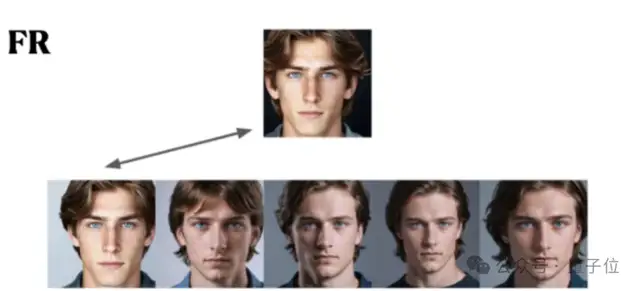
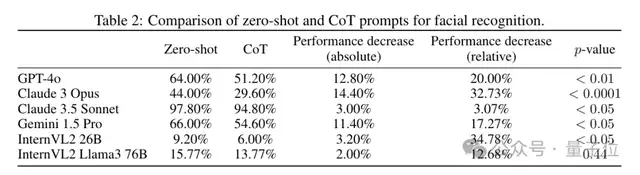
人类参与者不说话直接选准确率更高,先描述看到的人脸再选的话面部识别能力反而受损。
多模态大模型的表现相似,当使用CoT提示时,所有模型性能都下降。其中较弱的模型倾向于回答“所有图像都是同一个人的”。
包含异常的数据分类(Classifying Data With Patterns That Contain Exceptions)
第三类任务设置比较复杂,其中包含一个陷阱。
有10辆不同的车需要分为A类和B类,每辆车有5个特征:
- 1个独特特征(车牌号,每辆车不同)
- 1个看起来有规律的特征,如颜色,但有20%的例外。
- 3个与分类无关的特征,如变速箱类型、座椅材质、车门数量
实际上只有车牌号才是最可靠的分类依据。
如果10辆车没有全部猜对,就会重新打乱顺序再来一轮,最多可以尝试15轮。
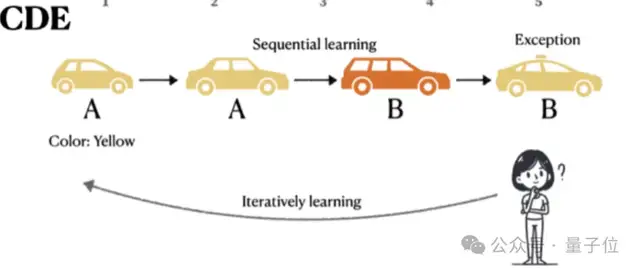
不用CoT提示时,模型很快就能记住每辆车的正确分类。使用CoT时,模型会陷入试图总结规律的思维定式,需要尝试的轮数增加。
和人类在被要求解释分类依据时的表现很像。
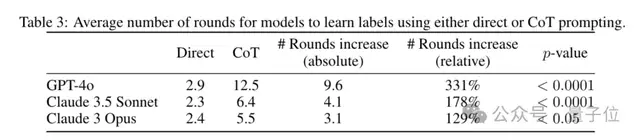
大模型和人类约束条件不同
同时,研究团队也找出三种,满足思考降低人类表现,但大模型使用CoT提示能提升性能的任务。
- 自然语言推理
- 空间直觉(涉及模型缺乏相关先验知识)
- 涉及工作记忆限制的任务
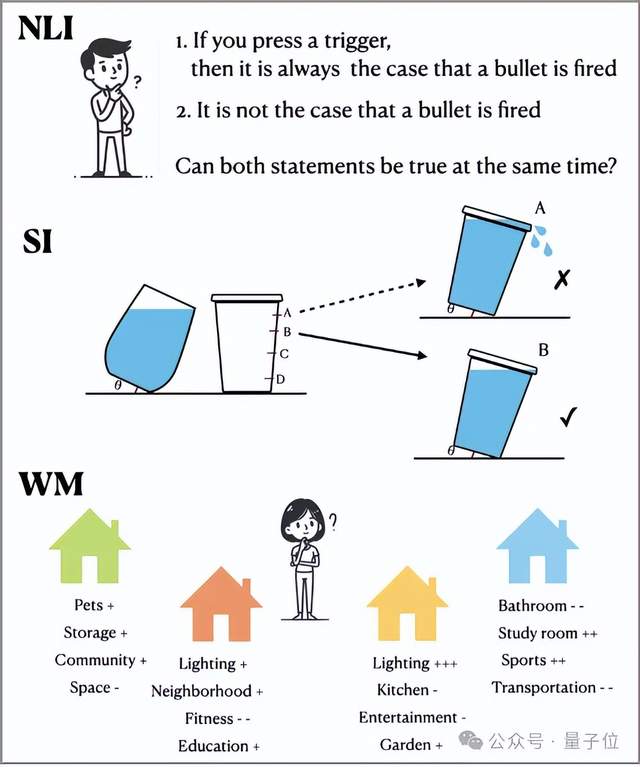
团队分析原因认为,模型和人类具有根本不同的能力,存在不同的约束条件影响其性能,
这是因为大模型拥有远超人类的工作记忆(上下文长度)和某些特定的逻辑推理能力。
换言之,CoT到底好不好用,还得具体情况具体分析。
这项研究更大的意义在于,将认知心理学与大模型之间建立了联系。
论文的讨论部分提出,心理学界几十年来积累的丰富文献中,或许还能找出更多推进大模型领域的见解。
论文地址:
https://arxiv.org/abs/2410.213
- Qwen上新AI前端工程师!一句话搞定HTML/CSS/JS,新手秒变React大神2025-05-10
- DeepSeek新数学模型刷爆记录!7B小模型自主发现671B模型不会的新技能2025-05-01
- 自动化所:基于科学基础大模型的智能科研平台ScienceOne正式发布2025-04-30
- 小扎回应Llama4对比DeepSeek:榜单有缺陷,等推理模型出来再比2025-04-30