李开复回应一切:竞技场排名“让我们有信心继续做预训练”
从打榜,到追赶OpenAI,再到大模型应用的商用落地,我们和开复老师聊了聊
GenAI 发自 凹非寺
量子位 | 公众号 QbitAI
我们只落后OpenAI 5-6个月,但要进一步缩短这个时间差,大家的难度都很大。
国产大模型首次在国际最具挑战的“大模型竞技场”榜单上超过GPT-4o(5月版本),当零一万物的名字紧跟在OpenAI、Google之后,李开复却如是坦言。
就在“大模型六小强”叫停预训练的传闻甚嚣尘上之时,李开复旗下零一万物历时5月憋了个大招,用实际行动回应一切:
推出最新旗舰模型Yi-Lightning,性能超越GPT-4o-2024-05-13,冲上UC伯克利大模型竞技场(Chatbot Arena)总榜第6。
还把每百万token的价格打到了0.99元人民币——不到该版本GPT-4o的3%,相比于GPT-4o-mini百万token输入输出价格的均值,也降低了近2/3。

△以上数据截止10月26日
不仅大模型竞技场官方发帖盛赞,“这标志着中国大模型的强劲增长”。
也得到了大模型社区的广泛认可:
中国大模型正在迎头赶上!很高兴看到竞争仍在继续,这迫使谷歌和OpenAI等大公司继续开发他们的模型,更重要的是,发布这些模型。

而这样一个模型背后,另一点值得关注的是,李开复博士和他旗下的零一万物,对中国大模型创业公司的发展路径,又有了更清晰的认知。
就在与量子位的一对一对谈中,从打榜,到追赶OpenAI,再到大模型应用的商用落地,李开复博士坦诚畅聊一切,还与我们分享了来自硅谷的最新见闻。
具体细节,在此分享。
(以下为李开复观点呈现)
中国大模型创业公司要“换一种打法”
5-6个月的差距如何追赶
零一万物从去年11月提出Yi-34B,到今年5月的Yi-Large,再到现在10月的Yi-Lightning,大约是5-6个月出一个模型,每次的新模型基本都能够达到5-6个月之前世界第一的水平。
5-6个月代表着一个绝对的差距吗?
我觉得追赶有两种心态,一种心态是我要用一样的方法论去做一样的事情,消耗一样的资源往AGI去冲。如果是这种思路,那放弃追赶是正确的。
OpenAI在训练GPT-4的时候花了1亿美金,GPT-5花了10亿美金,GPT-6可能就要花100亿美金,越往下越是一个天文数字。国内没有一个创业公司能融这么多钱,大厂可能也不舍得花这么多钱。
我们必须要有一个认知:美国有一些投资人的心态是很独特的,无论三年内烧出AGI的概率有多低,都要去砸一下试试。像OpenAI,有非常好的口才能说服一批投资人投他们;像马斯克,他的名字可能就值几十亿美元;像Google,不甘心他们最先发明的技术风头被别人抢走,所以咬咬牙也会投入;Meta我觉得一定程度是在搅局,但反正他们最近的广告收益很高,花个10亿美金甚至100亿美金没什么问题。
我们是没有这样的巨量资源的。
所以一模一样的打法是难以复制到初创企业身上的。但我们可以换一种打法,就是找到独特的“多快好省”的打法后发制人,用最少的资源,训练出力所能及的最优秀的模型。

我们说只落后OpenAI 5-6个月,如果说要再进一步缩短这个时间差,包括我们在内的中国同行们,难度都很大。零一万物的想法是,我们要做一个世界一流的模型,现阶段的策略会晚于第一个做到的模型5-6个月,不过我们会争取做得比它成本更低、速度更快——这样可用性反而是更高的。
中国公司很擅长把一件事情做到极致,用更低的成本,实现更高的效率。成本低了能够带来更多应用的爆发。
衡量模型能力很重要
我认为不能衡量的事情就没法进步,所以打榜不是为了像高考一样看能得第几名,而是去了解你在全球这么多厉害的公司和人当中,处在什么样的位置,是不是还有资格继续往前冲,还是已经掉队了。这一点非常重要。
各种榜单衡量的东西不一样。比如MMLU衡量的是“天花板”,问题是盖一个天花板100米高的房子,而你最高只能跳几米,上面的80米完全跳不上去,那有什么意思?
所以我们更看重如何去衡量模型的能力,以及是否被用户认可。UC伯克利大模型竞技场的评估方式,是让人来公平地评价,这是我们和全球巨头一直关注这个榜单的原因。
我们认可的不是打榜、刷榜的概念,而是用一个公平的,可以和最终用户对接、让他们来评分的这样一个方法,来给我们反馈。
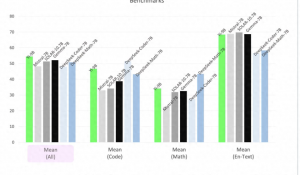
举个例子,这次榜单上我们提交了两个模型,看它们不同的得分,我们就能学到很多东西。
我们在这个榜单上是全球范围排第三名的公司,只在OpenAI和Google之后。让我们很欣慰的是我们知道自己肯定处在世界第一梯队上,这一点对我们来说非常重要,让团队非常振奋,因为我们知道自己的模型是可以打国内、国外市场的,谁都不用怕。
这对我们团队来说是一个正反馈,让我们有信心往前冲,继续做模型,继续做预训练。
另外很重要的是,跟排我们前面五名和后面五名的模型相比,Yi-Lightning的速度都比它们快。

AI应用进入商业化拐点
现在国内进入了一个可以做AI应用的时间点。
为什么早前AI应用比较难做呢?其实就一个原因:好的模型推理成本太高。一年半前,中国就没有一个模型是可以做出PMF(产品市场匹配)来的。
过去做移动应用,用户从10万增长到100万,虽然也会增加带宽、服务器等成本,但公司们不会因此破产。而在AI时代,如果一次推理就要几块钱,当用户10倍增长时,创业公司们马上就会破产。
今年,国内达到世界一流水平的模型已经有几个了,并且有些成本已经足够低。比如我们的Yi-Lightning,每百万token的价格是0.99元人民币,就已经可以支持一个AI搜索应用:每次搜索成本只要1-2分钱,即使用户达到百万级别,每人每天搜5次,成本也还是可控的。
这就是为什么要等到有一个性价比足够高的世界级模型,才能像移动互联网时代那样去做应用的原因。

国内ToC的应用目前还没有出现一个Super APP,不是因为用户不需要,而是因为之前足够好的模型会把任何一个创业者烧破产。到今天好的模型足够便宜,情况就大大改变了,对ToC我是非常乐观的。并且我相信,中国的创业者在做PMF方面是超过美国的,就好像美团做得比DoorDash好,抖音做得比Instagram好一样。
不过做应用可能还有一个挑战,就是用户的获取成本。
国内大厂很强势,创业公司获取用户的成本会比较高。所以对创业者来说,除了要有信心,模型够好够便宜,下一个就是怎么去找到机会,用比较少的钱撬动比较多的流量,或者是解决用户的强需求。
对于ToB的应用,我觉得本质是大模型代表的AI 2.0时代跟AI 1.0时代是有差别的。AI 1.0是项目制,你要做什么我全部帮你进场去做,做一单赔一单。在今天很多ToB的公司还是做一单赔一单,这个是让人担忧的。
但比较乐观的是,当你拥有大模型的能力,项目可以更便宜地做出来。有大模型的底座,不用收集那么多数据,它本身的能力就已经很强了。
大模型还有很多过去未有的能力,无论是做Agent、多模态内容生成,还是做Copilot、直播,这些能力都是AI 1.0时代没有的,是值得一试的。
走ToB路线特别要当心的是,首先,不要做一单赔一单。
其次,要认识到客户对模型没有需求,对解决方案才有需求。
第三,应该努力去找到合适的行业,能够快速让模型的本质融合行业的特质,实现省钱或者赚钱,最好是赚钱。
对于零一万物来说,我们会逐渐释放我们的产品。在ToC方面,我们还是会延续国外先尝试,再回到国内市场的路线。主要是我们已经在海外建立了一些实操经验,积累了一些对海外市场的理解,而且有些应用在海外收费比较容易被用户接受。
ToB的话我们在零售、政务、金融、能源等领域做出了一些有利润的单子。但是坦诚地说也还在不断验证,如何去建立可持续的优势。
当你在某个行业里拿下一单,它是一个不可复制的特例,还是可以重复再做第二单、第三单?在第二单、第三单中技术的重复使用能不能让你的利润率变得更高?这都还需要验证。我们的第二年,会聚焦在从技术到应用实践的商业化验证。

什么应用是值得去做的?2009年我做过一次演讲,当时说到移动互联网的应用到来的顺序会和PC应用成长的顺序相关。比如先是读取内容、撰写内容,然后是搜索管理内容,再能够去把内容做得更加多元化、更丰富,之后能够在内容之外拓展付费行为,包括广告、支付、电商、社交等等。内在逻辑是人的需求其实就是这些。
一个新的时代到来,应该也是这样的。AI内容的阅读和生产,是ChatGPT、Midjourney、可灵。那下一个阶段就是AI搜索,然后是多模态社交/娱乐,再走到本地生活&电商等等。
健康的大模型生态是倒三角结构
“ChatGPT火爆之后,钱都让英伟达赚走了”,这个观点是一个客观的事实。
一个主要因素是英伟达的主要客户是超级大厂,他们一买就买十万张、几十万张卡,这一下就让英伟达赚了很多钱。
这些公司的想法是要成为第一个做出AGI的公司,所以花多少钱买GPU都是值得的。这个心态就会导致钱都流向英伟达,也可能导致他们做出来的模型很厉害,但都很大、很昂贵。
对于我们来说其中的机会就是做更小的、推理成本更低的模型,去推动应用的发展。
要突破这个现状,我觉得就是要有足够多的公司了解到这样一个生态系统:
底层是GPU,中间是各种模型平台,模型平台之上是应用。这个结构一定要是上层最大、底层最小的倒三角,才是健康的。
另一个因素是,英伟达实在太强了,利润非常高。如果有两三家芯片厂商能与之竞争,他们的整个盘子可能就没有那么大,我们买到的GPU也可能变得更便宜。但短期来看,英伟达还是业界最强。
硅谷新见闻
o1引入了一个非常新的思维方式:不是所有智能都来自于预训练和微调。
以后大模型技术的发展应该会有三条路线:
第一还是怎么做好预训练;
第二是怎么做好post-training;
第三是怎么在推理之中加入思考。
o1最让我惊讶的是,我在美国碰到一位经济学教授,他跟我说,他用o1等于能少招一个博士生。
他有什么想法不用等到博士生每周跟他1 on 1的时候再来讨论,而是可以随时打开电脑去问o1。虽然有时候会有错误,但教授给它指出后,o1居然会学习,有时候还能反过来纠老师的错。所以这件事就变成,o1可能比一个博士生还能增强老师的能力。
当时我跟他聊的时候还有OpenAI的人在旁边。OpenAI的人就很兴奋地加入进来问,教授你愿意花多少钱买o1的服务?教授说很简单,我招博士生一年是10万美元,那我愿意付这10万美元给o1。

另外一件大家都在讨论的事是OpenAI的融资。
OpenAI的这次融资有点辛苦,融到66亿美元,看起来很多了,但要考虑到OpenAI的估值是1570亿美元。
挑战来自于哪里?我的理解是GPT-5是不太好训练的。理论上GPT-5应该已经出来了,但现在推延了,会推延多久大家并不知道。
但OpenAI可怕的地方在于,他们内部藏了很多类似o1这样的项目。他们并不着急推出,第一是怕竞争对手会学习进步,第二是要等到融资的节点,回应竞争对手的节点再拿出来用。
可以观察到的是,一年前,投资人们还在疯狂投各种模型,到今年,大家已经意识到,从纯财务投资的角度来讲,花很多钱去训练一个并没有产生太大商业价值的模型,几个月以后它就可能被取代,钱就白烧了。
我讲这个事情最主要的一点是想说:
投资人已经开始用商业思维来评估这个领域了。
— 完 —
- 粉笔CTO:大模型打破教育「不可能三角」,因材施教真正成为可能|中国AIGC产业峰会2025-04-18
- GPT-4.1淘汰了4.5!全系列百万上下文,主打一个性价比2025-04-15
- SOTA自动绑骨开源框架来了!3D版DeepSeek开源月大礼包持续开箱ing2025-04-11
- 语音界Deepseek!百度最新跨模态端到端语音交互,成本最高降90%2025-04-02