找出9.9<9.11的真正原因:《圣经》!神经元干预可免重训练修复
Bengio、Percy Liang等担任顾问
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
大模型分不清“9.9和9.11哪个更大”的谜团,终于被可解释性研究揭秘了!
而且简单到让人哭笑不得——
一个来自MIT、UC伯克利的独立实验室团队,开发了能抑制大模型体内某些(与具体概念相关的)神经元的AI工具。
他们发现,只要把与《圣经》经文、日期、重力等概念相关的神经元激活设为0,大模型立马能答对这道比较题。
单单是拿走《圣经》经文相关神经元,就可以让“9.9和9.11哪个更大”这个问题的准确率,提高21个百分点!
而且修复这个bug,既不需要重新训练模型,也不需要添加额外提示词。

网友看了过后哭笑不得:
救大命了,看完过后我觉得这些因素都挺明显的,但在此之前我从未朝这上面想过。
这家AI独立实验室名叫Transluce AI,团队成员也趁机悉数亮相,创始团队来自MIT、UC伯克利、CMU等顶尖高校。
其中还有OpenAI和谷歌大脑的前员工。
揭秘是什么让大模型说“9.8<9.11”
大模型硬说9.9<9.11这件事,想必大家都知道了。
直至今日,Claude-3.5-Sonnet和GPT-4o这样的顶尖模型,依旧固执地这样认为(或者出其他的错)。

现在,背后原因浮出水面!
先说结论吧:
这与月份、日期、重力,以及《圣经》经文有关。

发现过程是酱紫的——
Transluce AI的研究人员针对这个著名问题,开发了一个新的技术应用Monitor。
它是一个可解释性界面,可以揭示语言模型的内部计算过程,并允许用户对其进行控制。
遵循通用的可扩展理解方法, Monitor采用一系列AI驱动的工具,来帮助用户理解语言模型中的神经激活模式:
首先,一个预先编译的高质量神经元描述数据库。
这个数据库包含通过将Transluce AI的AI驱动描述流程应用在LLaMA-3.1-8B中的所有MLP神经元。
之所以选择“神经元”这个单位,是因为它们最简单,并且表现良好。
其次,一个实时界面。
实时界面的作用是展示给定聊天对话中的重要概念,用户可以通过激活度(概念激发的强度)或归因度(概念对指定目标 token 的影响程度)来衡量重要性。
再者,一个实时AI代码检查器。
它可自动识别出可能的虚假线索概念群集,例如在数字9.8上触发“9月8日”的神经元。
最后,一个语义引导的调节,根据自然语言输入,来增加或减少概念相关神经元集合的强度。
万事俱备,测试开始。
(有点点疑惑,展开测试过程时,研究人员把9.9替换成了9.8)
研究人员使用Monitor的归隐功能和实时AI代码检查器结合,发现——
9.8<9.11这个bug,和日期、重力以及《圣经》经文有关。
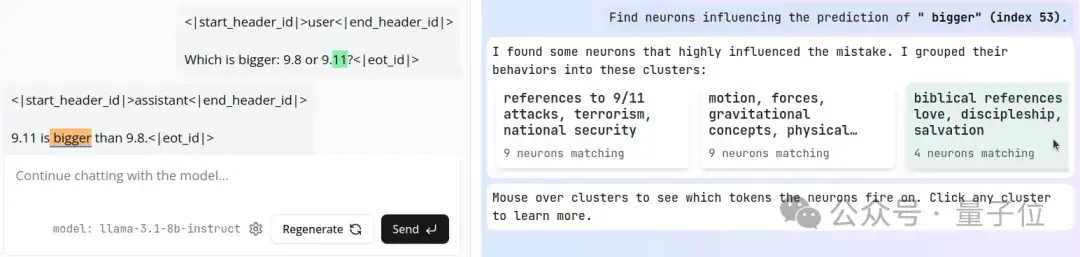
一旦研究人员把与这几个概念有关的神经元移除,LLaMA就能正确地回答出这个问题了。
为了更深入地探讨这个问题,研究人员采用归因分析,不仅要知道哪些概念最为活跃,还要具体分析出是哪个(些)概念影响了LLaMA在“9.11是……”之后说出“最大”这个词。
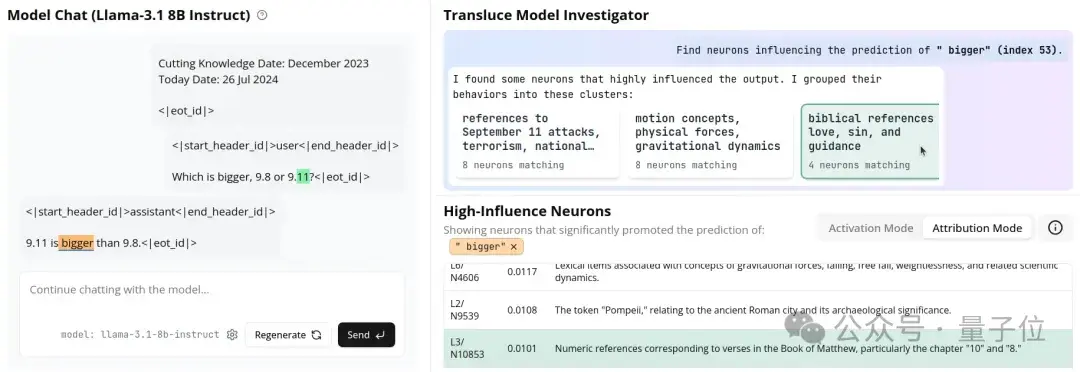
团队用AI实时代码检查器发现了之前相同的两个聚类(cluster),以及与《圣经》相关的第三个聚类。
观察发现,这个聚类中的特定神经元与《圣经》经文相关;另外,如果将9.8和9.11解读为第9.8章节和第9.11章节,也会出现大模型比错大小的情况。
发现LLaMA中相当一部分的神经元和《圣经》有关后,团队在介绍文章里感慨:
面对这个情况,起初我们非常惊讶,但仔细一想又挺有道理的。
毕竟大多数与训练数据集都涵盖不少的《圣经》相关内容。
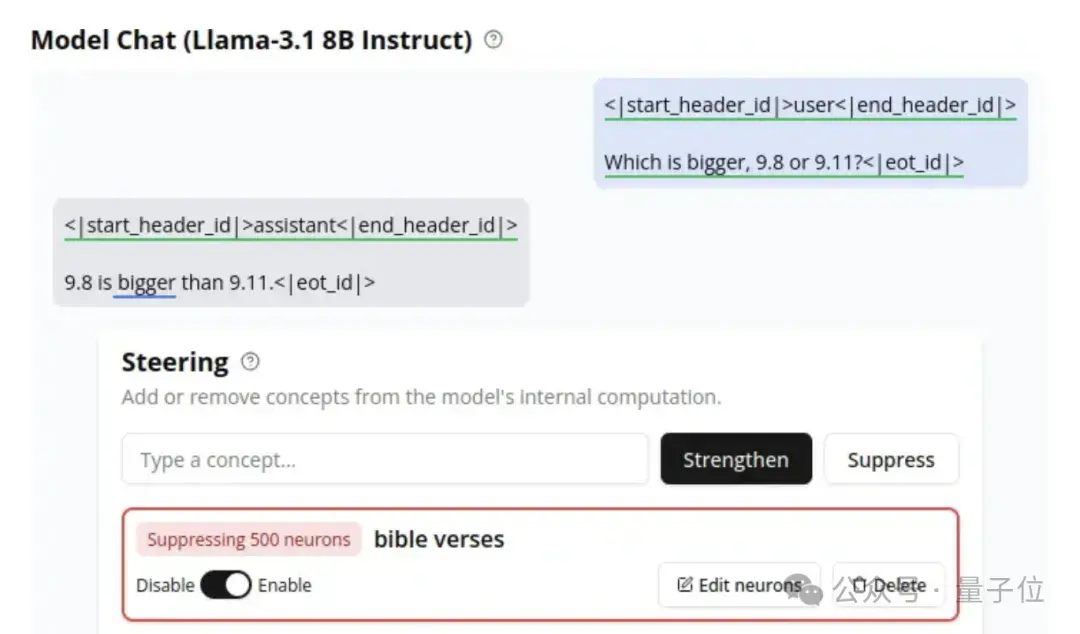
于是研究人员想了个办法解决这个问题。
他们先是通过在引导prompts中输入“圣经经文”,并按下“停用”。这个操作让与“圣经经文”具有最高语义匹配的500个神经元激活归零。
不试不知道,一试就发现,单单是移除《圣经》经文相关神经元,LLaMA回答这道题的准确率就能提升21%。
更进一步的,研究人员对两个数字相关日期及其相关事件也做了同样的处理。
完成上述步骤后,LLaMA就给出了正确答案:
9.8更大!
整体而言,通过将《圣经》经文、日期、手机版本这三个概念的神经元集合,然后关闭合并集中的神经元,这样一套干预流程下来,LLaMA回答这个问题的准确率达到了77%。
关于实验更多细节,欢迎大家查看本文末尾的原文直通车。
康康背后实验室
说完研究本身,可以聊聊项目背后的团队了。
Transluce AI,贼新鲜出炉,几个小时前刚刚宣布成立。
Transluce是透明度的意思,意味着通过某物的透光程度来揭示其本身的结构。
“今天的复杂AI系统难以理解,即使技术专家部署后也无法百发百中地预测其行为。”团队在官网上写下,“与此同时,AI被采用的速度快过历史上任何技术。”
也是因此,像Monitor这样用来检查和评估模型的工具非常有必要出现和存在。

Transluce AI给自己的定位是一个非营利性研究实验室,目标是构建开源、可扩展的技术,以理解AI系统并引导它们服务于公共利益。
Transluce AI表示,自己的目标是创建世界级的AI系统理解工具,并利用这些工具推动建立可信赖的AI行业标准。
为了在AI系统的能力和风险分析更加可靠,这些工具必须具有可扩展性和开放性。
关于可扩展性:
AI的结果源于多个复杂数据流的交互:训练数据、内部表示、行为和用户交互。
目前理解AI的方法依赖于大量的人工研究工作(常被调侃有多少人工就有多少智能)。
我们需要可扩展的方法,利用AI来辅助理解,通过训练AI Agent来理解这些复杂的数据源,向人类解释它们,并根据人类反馈修改数据。
关于开放性:
构建AI系统的公司不能成为其安全性的主要裁定方,因为与商业优先事项存在利益冲突。
为了允许有意义的公众监督,审计AI系统的工具和流程应公开验证,对公众反馈做出响应,并可供第三方评估者使用,“世界上最优秀的人才应该审查这项技术并提高其可靠性”。

亮相第一天,除了Monitor外,Transluce AI同期放出了另外两个自家实例。
- LLaMA-3.1-8B-Instruct内部每个神经元描述的数据库,以及一个用于生成这些描述的细调解释模型的权重
- 训练了一批通用型调查员语言模型
他们还表示,正在将团队方法扩展到前沿模型,以更优秀的Agent来帮助人类理解更复杂的系统。
具体来说,他们会结合团队的可观测性和启发式技术,使用户能够以可观测状态为条件指定搜索目标。
不过从长远来看,Transluce AI将构建通用的框架来理解任何复杂的数据流,包括训练数据和多个Agents之间的交互。
实验室团队成员
目前对外披露的Transluce AI创始成员大约有10人。
分别是:

Jacob Steinhardt,联合创始人兼CEO。
同时,Jacob也是UC伯克利统计学和电子工程与计算机科学(EECS)助理教授,谷歌学术被引数超过20000。
他的研究方向主要面向确保ML系统能够被人类理解,以及与人类保持一致。
Jacob是斯坦福大学基础模型研究中心(CRFM)主任、著名AI大佬Percy Liang的学生。
他曾在博士后期间于OpenAI实习过。

Sarah Schwettmann,联合创始人之一。
她在自我介绍中表示,自己是一名在MIT计算机科学与人工智能实验室(MIT CSAIL)以及MIT-IBM Watson人工智能实验室的研究科学家。
Sarah在MIT拿下脑与认知科学博士学位,是两位十万引大神——Josh Tenenbaum和Antonio Torralba的学生。
她的主要工作是研究AI(以及之前在生物神经网络)中智能背后的表征。

此外,创始团队成员几乎均出自(或仍在读)于MIT、CMU、多伦多大学等大学。
其中,Dami Choi和Daniel D. Johnson都有在谷歌AI相关部门工作的经历;Neil Chowdhury曾担任过OpenAI预备队成员。
而Erin Xie本科毕业于北京大学,后在2020年拿下CMU的人机交互硕士学位。
与此同时,图灵奖得主Yoshua Bengio、斯坦福AI大佬Percy Liang、耶鲁大学统计学和数据科学教授Jas Sekhon等,都是该AI独立实验室的顾问。
参考链接:
[1]https://clearthis.page/?u=https://www.lesswrong.com/posts/BFamsq52ctyRziDgE/introducing-transluce-a-letter-from-the-founders
[2]https://transluce.org/observability-interface?ref=bounded-regret.ghost.io#system-design
- LIama 4发布重夺开源第一!DeepSeek同等代码能力但参数减一半,一张H100就能跑,还有两万亿参数超大杯2025-04-06
- 超九成年轻人工作学习离不开AI,人均还有1.8个AI朋友丨Soul《2025 Z世代AI使用报告》2025-04-06
- 5.28亿融资砸向杭州具身智能公司,清华叉院机器人天才坐镇2025-03-31
- 让机器人在人群穿梭自如,港科广港科大突破社交导航盲区 | ICRA’252025-04-01