谷歌&MIT何恺明团队:视觉大模型像LLM一样高效扩展
指路连续token+随机生成顺序
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
视觉自回归模型的Scaling,往往不像在语言模型里那样有效。
谷歌&MIT何恺明团队联手,有望打破这一局面,为自回归文生图模型的扩展指出一个方向:
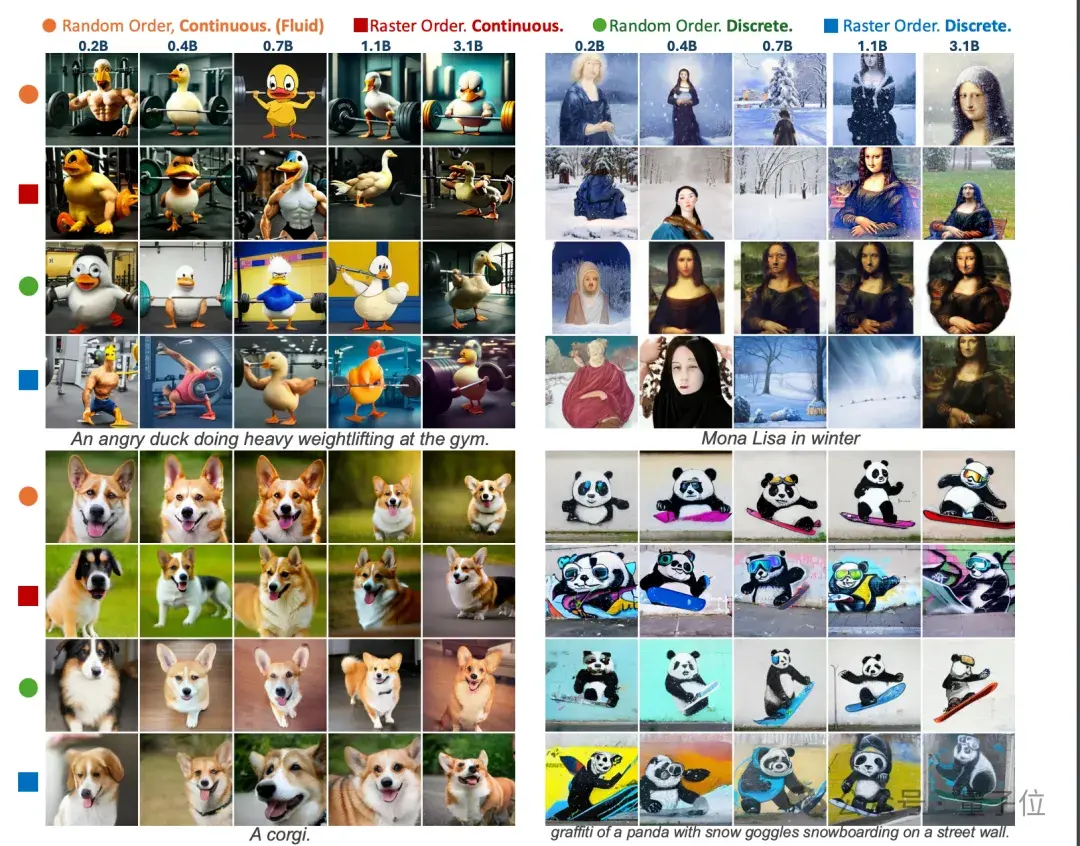
- 基于连续token的模型比离散token模型在视觉质量上更好。
- 随机顺序生成与光栅顺序相比在GenEval测试上得分明显更好。

受到这些发现启发,团队训练了Fluid,一个基于连续标记的随机顺序自回归模型。
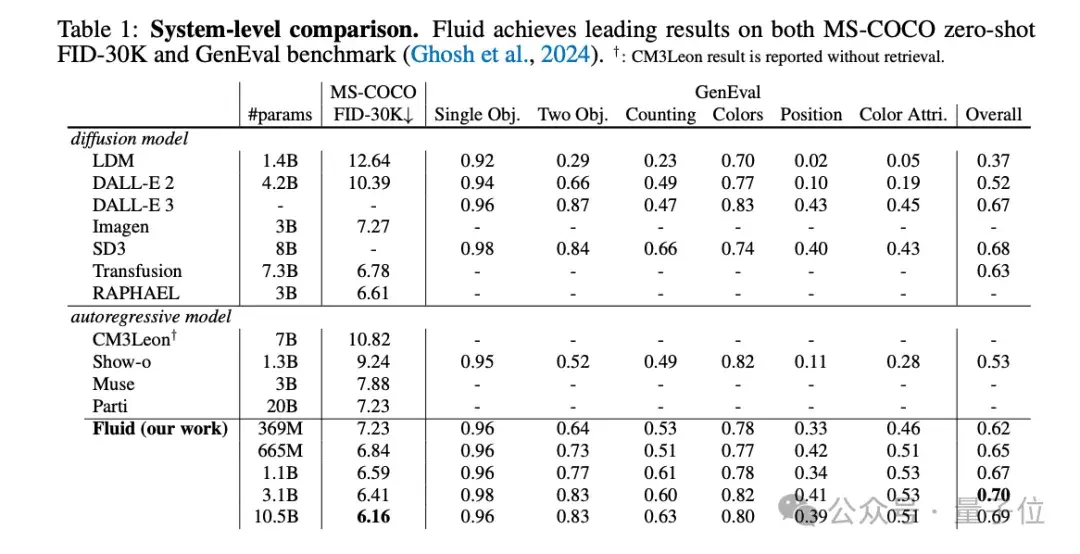
扩展至百亿参数的Fluid在MS-COCO 30K上zero-shot条件下实现了6.16的FID分数,并在GenEval基准测试中获得了0.69的整体得分。
团队希望这些发现和结果能够鼓励未来进一步弥合视觉和语言模型之间的规模差距。
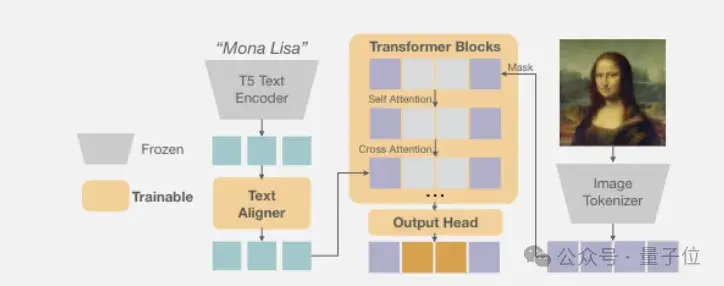
100亿参数自回归文生图模型
回顾过去,两个关键设计因素限制了自回归图像生成模型的性能表现:
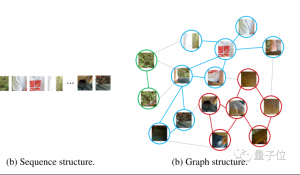
- 离散token。大多数此类模型借鉴NLP的做法,先用vector-quantized(VQ)方法将图像离散化为一组token,每个token只能取有限的离散值。这种量化难免损失大量信息。
- 光栅顺序。即按从左到右、从上到下的固定顺序生成token。这种方式虽有利于推理加速,但也影响了生成质量。
Fluid继承了团队在今年6月份研究《Autoregressive Image Generation without Vector Quantization》的思路,抛弃离散token,改用连续token。

它借鉴了扩散模型,用一个小型去噪网络近似每个token的连续分布。
具体而言,模型为每个位置的token生成一个向量z作为条件,输入一个小型去噪网络。这个去噪网络定义了token x在给定z时的条件分布p(x|z)。训练时,该网络与自回归模型联合优化;推理时,从p(x|z)中采样即可得到token。整个过程无需离散化,避免了量化损失。

再来看看生成token的顺序。按固定的光栅顺序逐个生成token,推理时虽然可以用kv缓存加速,但因果关系的限制也影响了生成质量。
Fluid另辟蹊径,随机选择要生成的token,并用类似BERT双向注意力的机制捕捉全局信息。
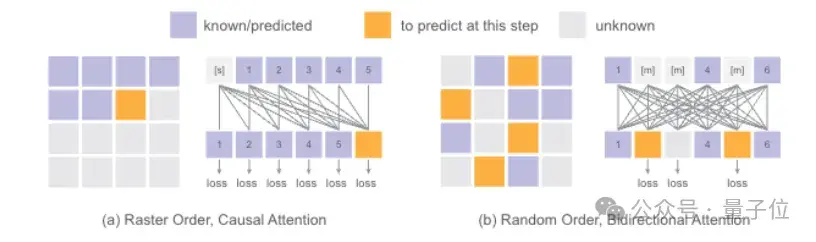
在推理时采用完全随机顺序,训练和推理过程的序列分布更一致;同时还能对每个token进行类似GPT的temperature采样,进一步提升了生成多样性。
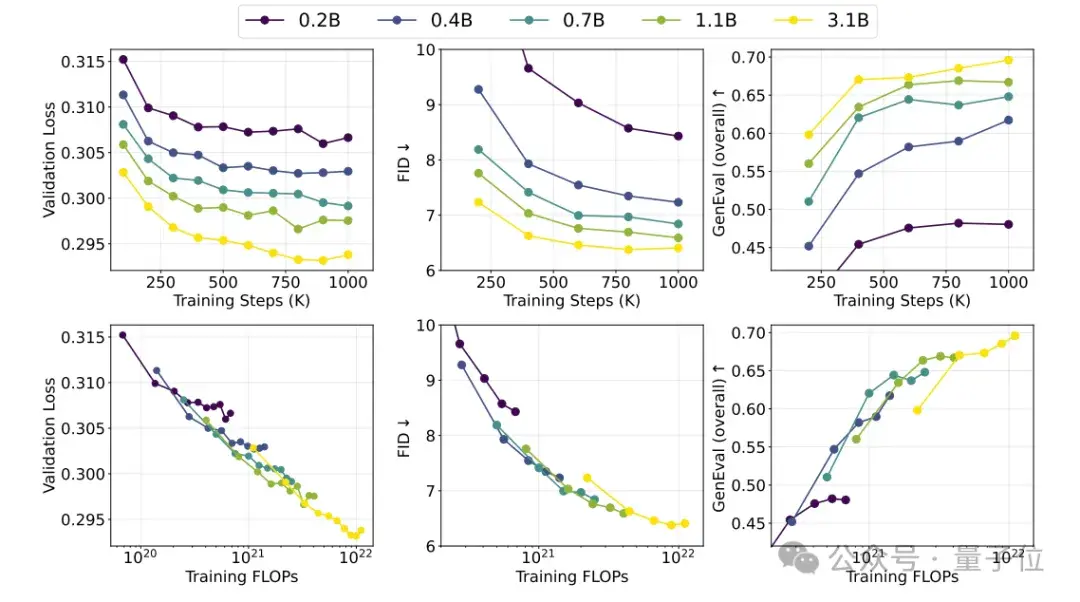
得益于扩散损失和MAR范式的双重加持,作者将模型参数量扩展到超过100亿,在MS-COCO和GenEval数据集上取得领先结果。
更重要的是,随着参数量和训练轮数的增加,模型在验证损失、FID、GenEval Score等指标上表现出良好的可扩展性,为进一步扩大规模提供了理论支撑。这与语言模型的Scaling现象非常类似,表明视觉大模型的潜力尚未被充分挖掘。
更多Fuild模型生成图像精选:

论文地址:
https://arxiv.org/abs/2410.13863
- 刷新复杂Agent推理记录!阿里通义开源网络智能体超越DeepSeek R1,Grok-32025-07-07
- DeepSeek降本秘诀曝光:2招极致压榨推理部署,算力全留给内部2025-07-04
- 国产GPU历史性时刻!摩尔线程、沐曦同日获IPO受理2025-07-01
- 韩松贾扬清之后,又一家清华系AI公司卖给英伟达,黄仁勋亲自招募95后联创2025-06-29