
趋境科技发布大模型知识推理一体机,首创“全系统推理架构”助力企业实现高效推理
将推理成本降低10倍以上
随着大模型,尤其是开源大模型的持续进化,具备复杂推理能力的模型正在逐步应用于各行各业,并展现出超越人类专家的潜力。得益于此,未来的算力建设将更加聚焦于推理场景,而不仅仅是训练算力。
华福证券的研究指出,到2027年,推理端的人工智能服务器预计将占整体工作负载的72.6%。同时,OpenAI o1 所代表的大模型推理场景的 Scaling Law 也进一步助推了这一趋势的加速发展。
然而,尽管模型的效果有了显著的提升,数百亿参数、上百万上下文的一线模型在实际部署中仍面临高成本和低效率的挑战。这一现象导致了难以破解的“不可能三角”。
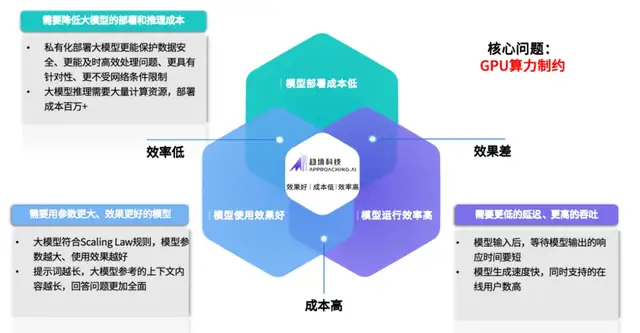
为了应对这一困境,亟需新型推理架构,打破传统主要为训练场景设计,以高端 GPU 为中心的算力架构设计思路。
在此背景下,趋境科技推出了“大模型知识推理一体机”,其搭载的业界首创的全系统推理架构能够通过协同存储、CPU、GPU、NPU等多种设备,充分释放异构算力,将推理成本降低10倍以上。

这一创新为企业实现大模型的高效落地提供了全新选择,开启了通向“推理自由”的新途径。
趋境大模型知识推理一体机不仅支持本地部署数百亿级别的一线大模型,还提供开放的API接口,便于第三方灵活调用。同时,用户可根据需求定制企业智能助手(assistant/copilot),实现真正的“开箱即用”。
协同 HBM/DRAM/SSD 和 CPU/GPU/NPU 全系统异构设备,充分释放异构存力和算力资源
与当前行业主要针对 GPU 算力利用率进行单点优化的传统方案相比,趋境科技大模型知识推理一体机采用了业界首创的全系统推理架构。
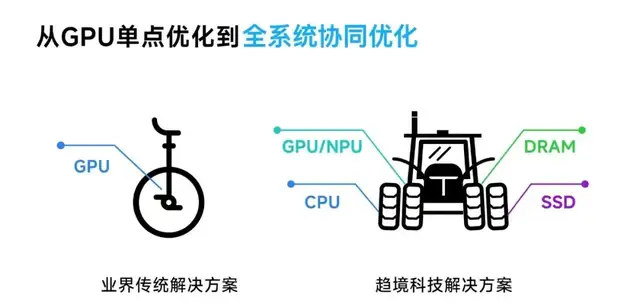
其通过“以存换算”技术释放存力作为算力的补充,降低对算力的需求;同时采用“异构协同”的思路,紧密联动 HBM/DRAM/SSD 和 CPU/GPU/NPU 全系统异构设备,突破显存容量的限制,充分释放全系统的存力和算力。
这一创新方案突破了以往方案的理论优化极限,实现了整合机器所有异构算力资源的目标,使得推理吞吐量提升超过10倍,大幅降低了大模型的落地成本。
此外,据财通证券发布的行业深度分析报告统计显示,国产GPU产品在单精度/半精度浮点算力、制程及显存容量上都与英伟达有2-4倍的显著差距。因此,仅依靠GPU单点优化,短时间内很难赶超英伟达GPU方案。
而采用全系统推理架构可以大幅降低GPU性能差距的影响,显著提升国产替代解决方案的竞争力,打破在大模型推理场景下国产GPU“卡脖子”的困境。
以存换算新范式,从“死记硬背”到“融合推理”
早期的大模型推理架构将每次推理视为独立请求,缺乏高效处理所需的“记忆”能力。尽管后续引入了近似问题缓存(Semantic Query Cache)和前缀缓存(Prefix KVCache Cache),但仍主要依赖于“死记硬背”。这些方案要求新问题与已处理问题高度一致才能利用缓存去降低算力需求。
针对这一问题,趋境科技创新性地设计了“融合推理(Fusion Attention)”技术,即便是面对全新的问题也可以从历史相关信息中提取可复用的部分内容,与现场信息进行在线融合计算。这一技术显著提升了可复用的历史计算结果,进而降低了计算量。
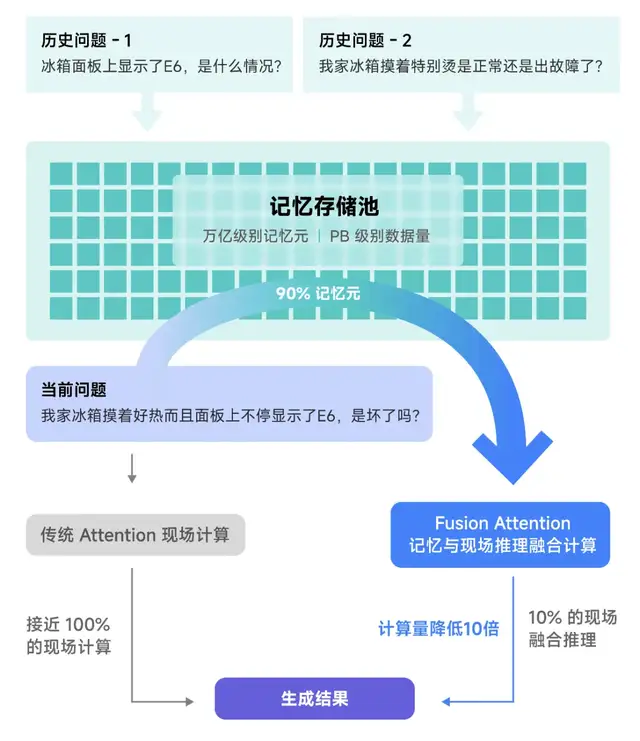
通过这一新思路,趋境大模型知识推理一体机充分利用了存储资源。采用“以存换算”的方式释放存力作为对于算力的补充,在RAG场景中,响应延迟降低20倍,性能提升达10倍。
全系统异构协同新架构,从GPU单点优化到全系统协同优化
除了通过“以存换算”降低算力需求外,趋境大模型知识推理一体机还进一步通过全系统异构协同架构设计,将来自存储、CPU、GPU、NPU的算力高效融合,进一步提升大模型推理性能,降低成本。
此前,趋境科技与清华 KVCache.AI 团队合作,开源了一部分异构推理框架,项目名为“KTransformers”(GitHub链接:https://github.com/kvcache-ai/ktransformers),该开源框架仅需单个消费级 GPU 即可在本地运行 Mixtral 8x22B 和DeepSeek-Coder-V2 等千亿级大模型,性能数倍于 Llama.cpp。
在长达 1M 的超长上下文推理任务中,成为业界首个仅需单 GPU 卡的高性能推理框架,生成速度达到 16.91 token/s,比 Llama.cpp 快10倍以上,同时维持接近满分的“大海捞针”能力。
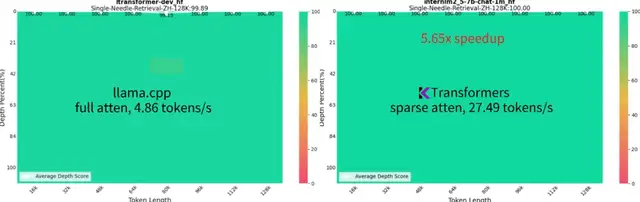
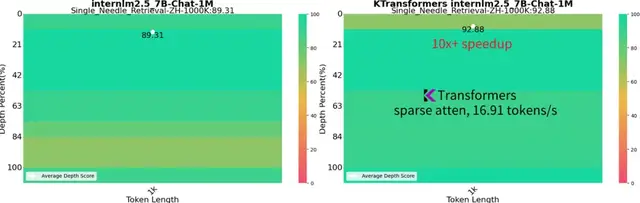
趋境科技大模型知识推理一体机采用的全系统推理架构是基于“KTransformers”进一步完善的商业版本,在开源版的基础上,协同性能更强,加入了多卡高并发调度、RAG支持等策略。经过测试及客户合作验证,Prefill 和 Generate 性能大幅领先业界方案:
- Prefill阶段的 TTFT(响应延迟)相比业界方案快6倍以上
- Generate阶段的 TPOT(生成速度)相比业界方案快3.48倍以上
趋境x长亭:为安全大模型开启千亿大模型时代
国内顶尖的网络信息安全公司长亭科技,使用趋境科技提供的全系统异构推理架构技术策略,无缝衔接到其原有的“问津(ChaitinAI)安全大模型”、MSS 安全托管服务等产品中,问津(ChaitinAI)安全大模型升级为千亿大模型,安全性能全方位升级:
核心指标攻击识别准确率提升至95.8%,检测时延降低至秒级。另外,其对漏洞的检测能力增强,不仅提升漏洞发现数量,对应的修复建议也更准确,还能基于不同场景选择更合适的工具和策略。同时,对不良内容识别能力升级,准确率和召回率均有提升。安全报告内容生成质量和评分也显著提高,综合输出更具健壮性和稳定性。
此外,长亭科技的安全大模型的部署资源成本降低50%,助推其更多业务加入大模型能力。
技术的不断进步和市场需求为大模型的未来发展提供了广阔的空间。随着算力基础设施的不断完善,提升算力的利用效率,使大模型能与更多的行业实践结合起来,未来大模型将在更多行业中发挥更大的作用。
趋境目前也正在和更多的大模型应用厂商一同协作,希望助推全面智能化的到来。
Approaching.AI 趋境科技
趋境科技成立于 2024 年,基于业界首创的全系统推理架构推出“大模型知识推理一体机”,为用户提供开箱即用的大模型落地解决方案。
该架构能够通过协同存储、CPU、GPU、NPU等多种设备,充分释放异构算力,显著降低 RAG(检索增强生成)等关键大模型应用场景的运算成本 10 倍以上,有效解决大模型公司以及金融、安全、电信、教培等行业大模型落地的“最后一公里”难题。
公司创始团队均来自清华大学,在 AI、体系结构、系统软件等相关的技术系统和软件领域,有多年学术与产业实践经验。
- 阶跃星辰推出开源 SOTA 图像编辑模型,一个月连发三款多模态模型2025-04-27
- 清华系智谱×生数达成战略合作,专注大模型联合创新2025-04-27
- 夸克AI超级框上新“拍照问夸克” 加码多模态能力2025-04-27
- 一季度超百万辆!比亚迪凭实力书写行业 “霸榜” 传奇2025-04-27




