字节豆包首个AI硬件来了,定价1199元!
可以练雅思口语的那种
金磊 西风 发自 凹非寺
量子位 | 公众号 QbitAI
字节跳动的首个AI硬件,就这么水灵灵地来了——
一款塞了大模型的蓝牙耳机!

这个AI耳机,名叫Ola Friend,“Olá”在葡萄牙语中意为“你好”,因此它的中文名就是:你好呀 朋友。
首先,Ola Friend最大的亮点,就是第一个做到了真正把通用大模型应用到耳机场景——
戴上耳机,只需一句“豆包豆包”,就可以随时随地唤醒AI,并跟它做任何交流。
例如出门前询问天气、路面状况,现在的“打开方式”是这样的:
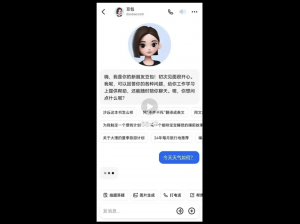
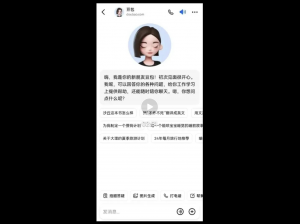
当然,这些问题都只能算是开胃菜,我们直接来上一下难度——英语口语练习!
视频详情:https://www.toutiao.com/article/7424073841964384802/
不难看出,现在跟AI练习英语口语,就变成戴个耳机就能实现的事情了,而且你可以随时打断豆包说话(1分29秒左右)。
当然,作为一个蓝牙耳机,其本身最基本的“听”的功能也是非常重要的。
Ola Friend在设计上属于不入耳的开放式(OWS)耳机,单只的重量只有6.6克(亲测佩戴无重感)。
在音效方面,由于设计采用27.5度夹角,发声单元会更靠近耳道,声压比会相对大一些;并且还采用了10mm动圈发声单元、动态EQ1.0、动态低音补偿、定向防漏音等设计,提升了耳机的音质。
上面视频中豆包说话的音效,其实就已经非常接近佩戴时候的真实感觉了。
但毕竟我们第一时间拿到了Ola Friend,定然不能就这么简单放过它——
实测嘛,就是要狠狠地、各方面地都来体验一把。
嘈杂环境、方言,统统都能hold住
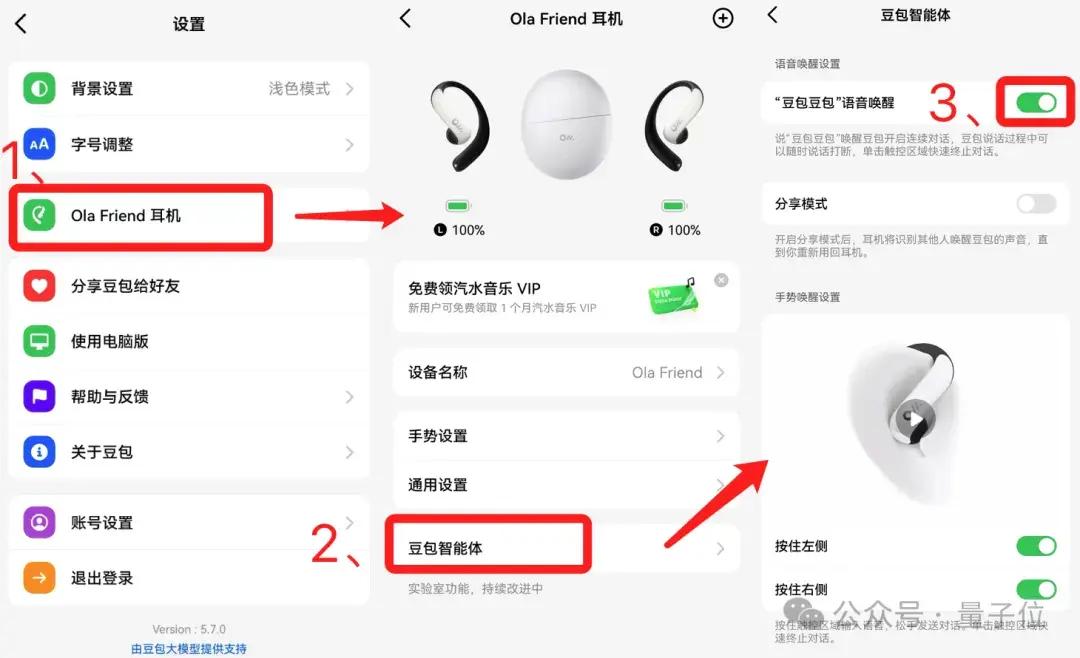
首先我们需要介绍一些基本的功能和设置。
Ola Friend在和手机配对的时候,需要双手同时按住两侧机身,然后就可以在手机蓝牙中找到它并连接。
但要想开启AI大模型功能,还需要进豆包APP的“我的→设置”里,找到“Ola Friend耳机”选项,进行第二次配对;其中,“豆包智能体”选项中的唤醒功能是默认开启的。
接下来,我们就再贴近真实生活场景来一波测试。
毕竟我们戴耳机不仅仅是在安静的环境,大多数可能都是非常嘈杂的环境,那么在用Ola Friend跟豆包对话的过程中,它会不会受到外界环境的影响呢?
我们这波测试的环境设置如下:电脑外放音乐,用中英掺杂的方式跟豆包对话。
(由于对话文字内容较长,以下几个实测视频将以字幕的形式呈现)
即便背景放了巨大音量的英文歌,但豆包还是能够精准识别出用户的声音,在问及“为什么今年的the Nobel Prize in Physics颁给了Geoffrey Hinton”时,豆包也能做出准确回答。
由此可见,在嘈杂的现实环境中,Ola Friend也是完全可以hold住的。
而之所以能够如此,是因为Ola Friend是可以像朋友一样专门记住你的声音,这就大幅降低了错误打断的概率。
同样的问题,同样的环境,我们再有请方言出战——四川话!
这一次,我们特意切换了语音风格为“呆萌川妹”,是不是相当地有那味儿了!
那么对于复杂的数学题,Ola Friend又将做何表现?
我们不妨以电影《抓娃娃》片段中的那道经典题目来提问(这次我们切换了声音为“温暖阿虎”):
一个长2米,直径30cm的圆柱形木材,做半径6cm比做半径8cm能多做多少个球?
从求解过程中不难看出,不论是要求Ola Friend直接给出答案,亦或是在它求解过程中任意打断(1分17秒、1分59秒、2分14秒),它都能像跟真人交流一样严丝合缝。
不难看出,戴上了Ola Friend,就宛如实时地在跟AI大模型电话一样,而且是有问必答、随意打断、多轮对话的那种。
因此,像在做饭烧菜等场景中,这个AI大模型耳机就能在释放双手的同时,还能做到答疑解惑。
方便,着实是方便。
那么接下来的一个问题便是:Ola Friend是如何做到的?
大模型+TTS+ASR炼成
扒开Ola Friend内核,关键之一是字节于业界领先的大规模自回归文本到语音模型——Seed-TTS。
几个月前,字节发布了Seed-TTS技术论文,引发圈内广泛关注。
它可以依据上下文理解文本情绪,能生成与人类语音几乎无法区分的高质量语音,说话自然有感情,连停顿、喘息、换气声都合成得真真儿的。

从技术实现上来看,Seed-TTS基于自回归Transformer,模型架构包含speech tokenizer从语音中提取token信息,语言模型建模文本和语音token的关系,扩散模型从语音token生成连续的语音表征,最后通过声码器生成最终的语音。
训练含三个阶段:
- 预训练:使用大量数据训练,实现广泛的应用场景和说话者覆盖。
- 微调:说话者微调,以提高特定说话者或任务的性能。
- 后训练:使用强化学习进行后训练,全面提高模型性能。
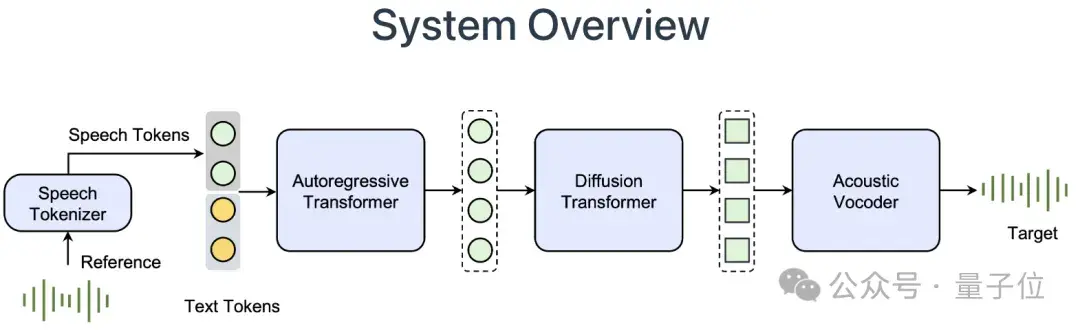
与以前的模型相比,Seed-TTS在自然性和稳定性方面有显著提升。
经实验,Seed-TTS不仅具有零样本上下文学习能力,基于短音频提示生成相似声音的新语音,还可以针对特定说话人进行微调,进一步提高相似度。
在情感等方面Seed-TTS具有更高的可控性,且支持跨语言语音合成,拿捏讲话的音调、韵律、节奏。
Ola Friend另一大法宝是语音识别技术——Seed-ASR。
与AI智能音箱和车载语音系统相比,耳机通常在公共空间中被使用。这些场所环境嘈杂并且人多,因此在这些环境中进行声音识别和意图判断面临较大挑战。
而字节Seed-ASR技术,不仅让Ola Friend能听懂用户说话,甚至能通过上下文识别各类信息。
Seed-ASR以大语言模型为基础,通过输入连续的语音表示和上下文信息,显著提升了在不同应用场景下对多样语音信号的识别准确率。
它支持包括普通话及多种方言在内的多语言识别,在丰富的训练数据上进行大规模的自监督学习,还通过了阶段性训练策略,包括监督式微调、上下文感知训练和强化学习,进一步优化性能。
Seed-ASR在公开测试集和内部综合评估集上均展现出比现有端到端模型更低的词/字错误率。
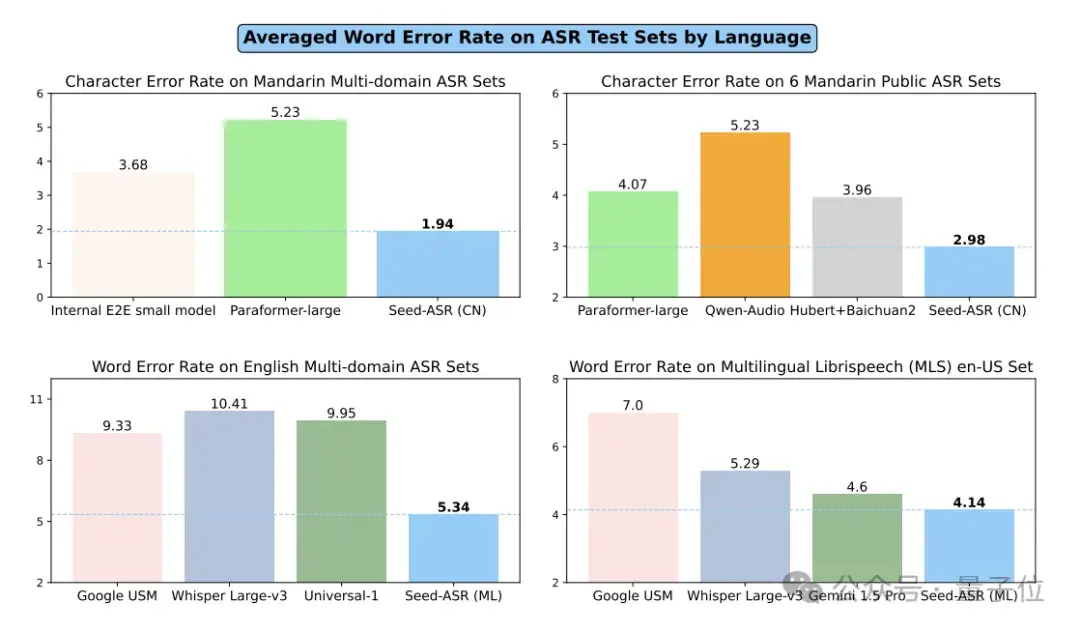
除此之外,依靠豆包大模型,Ola Friend还有buff加成——
能够双向实时对话,随时打断也可以,支持引入其他话题多轮交流,而非每句话都要唤醒词并且听完全部再回复。
与传统智能音箱助手等大多是特定任务可以多轮(如追问天气情况)不同,接入大模型之后,在交流中随意切换话题也不怕,可以做到通用场景全双工连续对话。
另外,Ola Friend进行了很多工程优化,像是链路预加载等,使得端到端交互时间可以缩短,降低用户讲话后得到反馈的时间。
开放式耳机的AI进化
作为字节跳动豆包团队第一款AI硬件,几天前官方刚发布预热海报,就有大批网友开始猜测Ola Friend是耳机呢?还是眼镜呢?还是耳机呢?
这下它的神秘面纱终于被揭开,那为啥字节能将AI交互引入到耳机场景呢?
不仅得益于自家的豆包大模型支持,还与其硬件团队的实力密不可分。
据了解,九月份,字节跳动正式宣布成功收购开放穿戴式音频产品厂商Oladance,完成100%控股。

Ola Friend硬件团队就是原Oladance耳机团队,也就是最早做OWS开放式耳机的那帮人,有深厚技术积累。
团队出身如此,所以Ola Friend也正如我们前文所提到的,不仅从设计上不单单考虑了AI硬件的性能,还兼顾了传统开放式耳机的舒适度和音质。
同时团队还专门推出了优化降噪算法,算法已申请专利,针对轻声唤醒和交互专门做了改进,用户用较轻的声音就能唤起豆包。
也就是说,在公开场合中悄默声就能唤醒,妈妈再也不用担心我会社死。

大模型技术的发展正如日中天,各种AI硬件如雨后春笋般涌现,从智能家居到个人助手,AI正在深刻改变我们的生活方式。
在这一背景下,字节跳动推出的Ola Friend无疑为AI硬件耳机市场带来了新的活力。
据悉,Ola Friend将于10月17日起售,听说后续AI功能还会持续更新,未来Ola Friend不仅能唤醒豆包,还可以唤起更多智能体。
那么你对这个首款AI大模型耳机心动了吗?
- 阿里云造“Agent工厂”,百炼MCP服务上线,无需代码5分钟建Agent2025-04-09
- 周光:VLA模型将成智能驾驶体验颠覆性拐点2025-03-31
- 摸DeepSeek过河也得自身硬! 想开后的文小言,真香!2025-03-31
- 7B模型搞定AI视频通话,阿里最新开源炸场,看听说写全模态打通,开发者企业免费商用2025-03-27