非Transformer架构新模型爆火,从第一性原理出发,MIT CSAIL衍生团队打造
基于液态神经网络
西风 发自 凹非寺
量子位 | 公众号 QbitAI
挑战Transformer,MIT初创团队推出LFM(Liquid Foundation Model)新架构模型爆火。
LFM 1.3B、LFM 3B两个不同大小的模型,性能超越同等规模Llama3.2等Transformer模型。
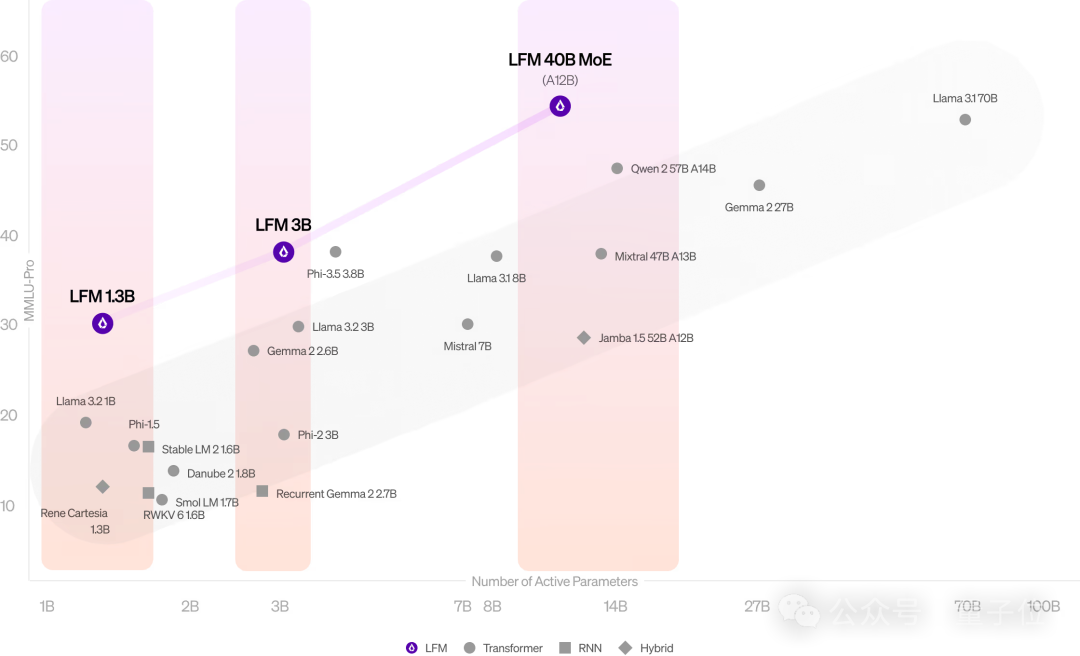
LFM架构还有很好的可扩展性,团队还推出了基于MoE的LFM 40B(激活12B参数),能与更大规模的密集模型或MoE模型相媲美。
LFM用的是一种液态神经网络(LNN),从第一性原理出发而构建,其计算单元植根于动态系统理论、信号处理和数值线性代数。
这种架构还有一个特点:在内存效率方面特别强。
基于Transformer的LLM中的KV缓存在长上下文中会急剧增长,而LFM即使在处理100万个token时也能保持内存最小。
小巧便携,使得它能够直接部署在手机上进行文档和书籍等分析。
LFM模型背后是一支MIT计算科学与人工智能实验室衍生出来的小团队,名叫Liquid AI。
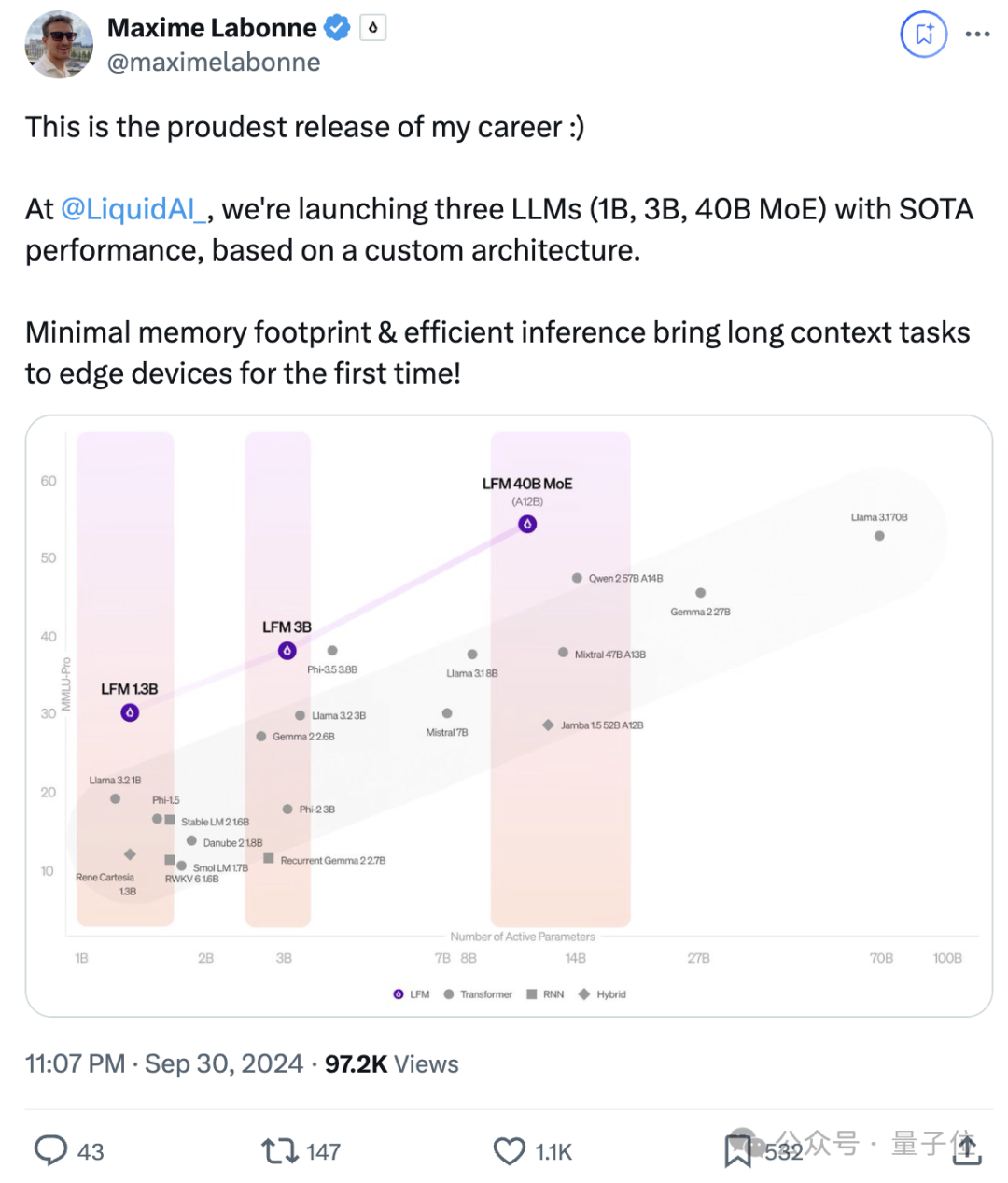
其后训练负责人Maxime Labonne在X上为自家模型疯狂打Call:
这三个具有SOTA性能的模型,是我职业生涯中最值得骄傲的版本。
AI畅销书《人工直觉》作者也表示看好。

一直等的就是这样的模型,基于物理学或神经元的“第一性原理”

目前LFM系列模型还在预览测试中,大伙儿可通过Liquid官方平台、Lambda Chat、Perplexity AI来访问。
基于液态神经网络打造
具体来看看这三个模型的性能和特点。
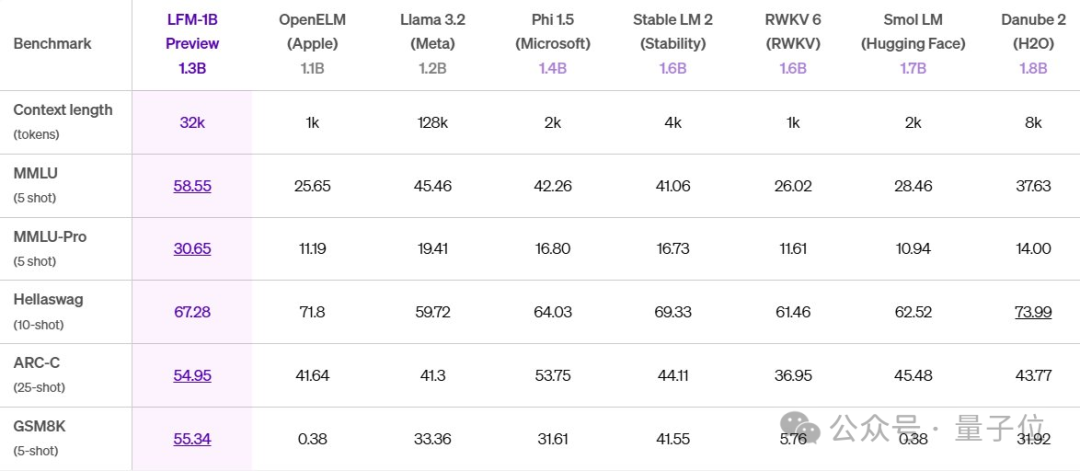
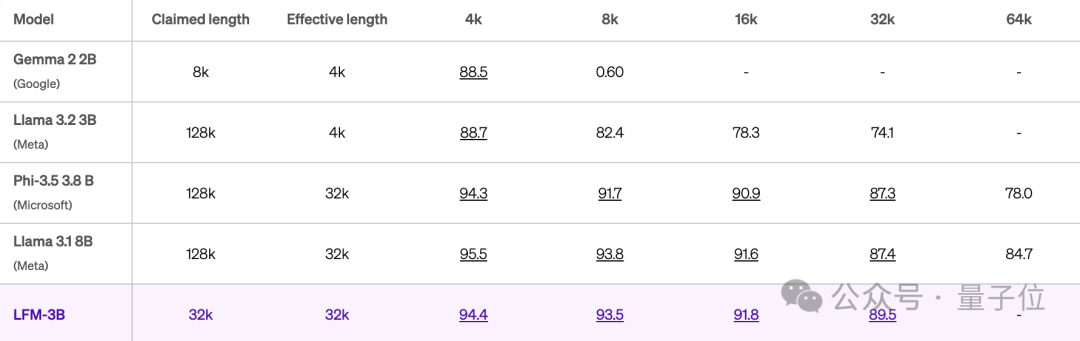
LFM 1.3B在MMLU、MMLU-Pro、ARC-C、GSM8K基准上相较于下表其它模型,取得SOTA性能。
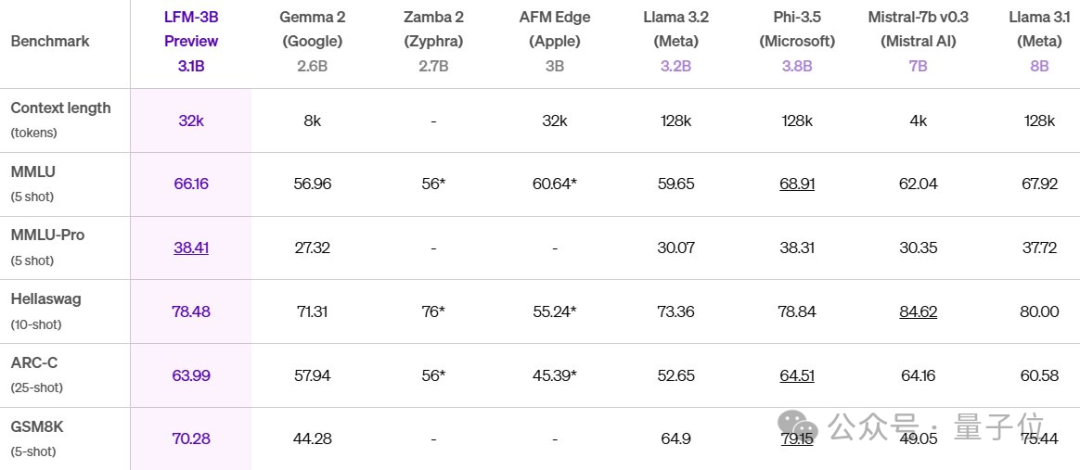
LFM 3B,还能和Mistral 7B、Llama3.1 8B两倍大模型打得有来有回。
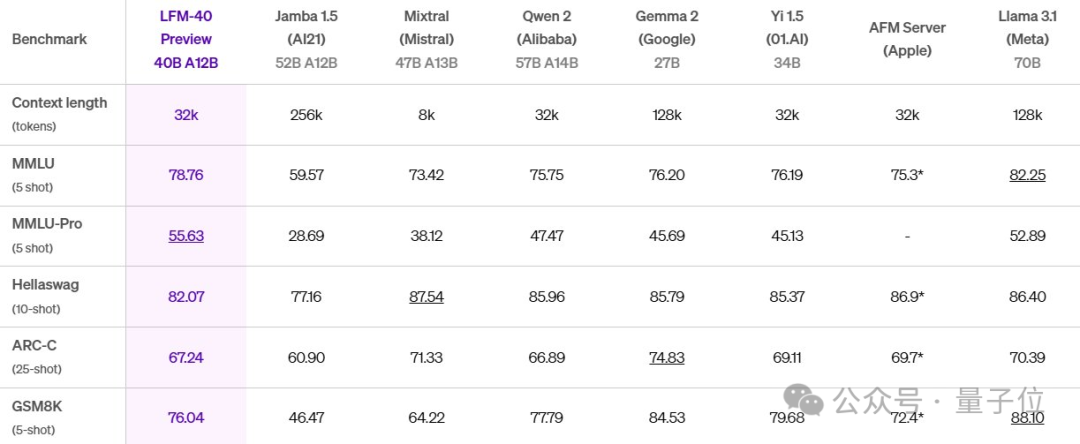
LFM 40B性能也可与比其自身更大的模型相媲美,MoE架构可实现更高吞吐可部署在更具成本效益的硬件上。
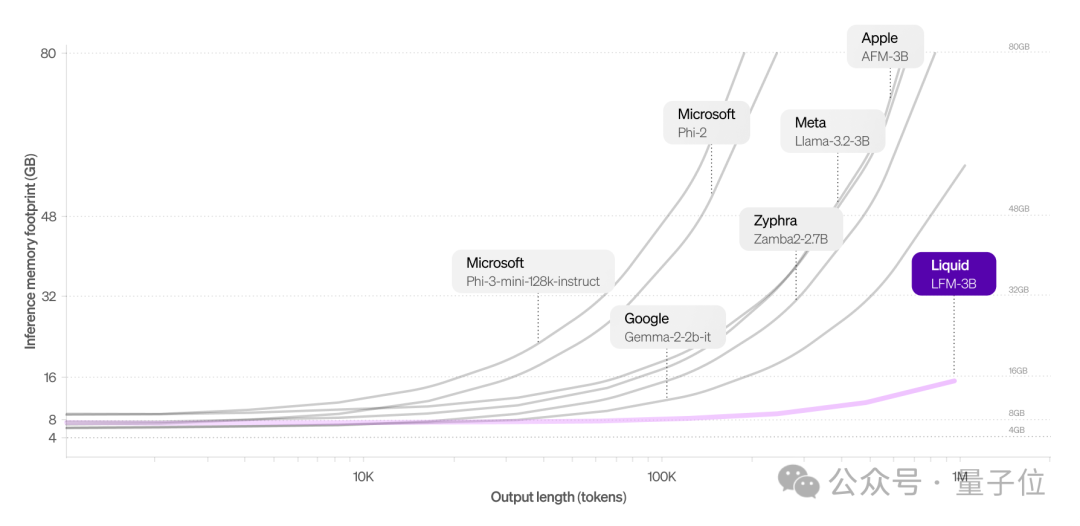
与Transformer架构相比,LFM的一个突出优势就是内存占用更少。
对于长输入效果更明显,基于Transformer的LLM中的KV缓存随着序列长度线性增长。通过有效压缩输入,LFM可以在同一硬件上处理更长的序列。
以下是LFM 3B与其它3B级模型的对比,LFM 3B能始终保持较小的内存占用。
处理100万个token,LFM 3B只需16 GB内存,而Llama-3.2-3B模型则需48 GB+。
LFM上下文有效长度为32k。
当相应得分高于85.6时,长度被认为是“有效的”(Hsieh等人,2024 RULER)。
LFM 3B在32k的上下文长度上,仍能保持89.5的高分。
实验结果中Llama 3.2生成128k上下文窗口,但实际只在4k上有效,也引起一波关注。
除此之外,LFM由结构化运算符组成,为基础模型打开了一个新的设计空间。
不仅限于语言,还可以将其应用于音频、时间序列、图像等等其它模态。
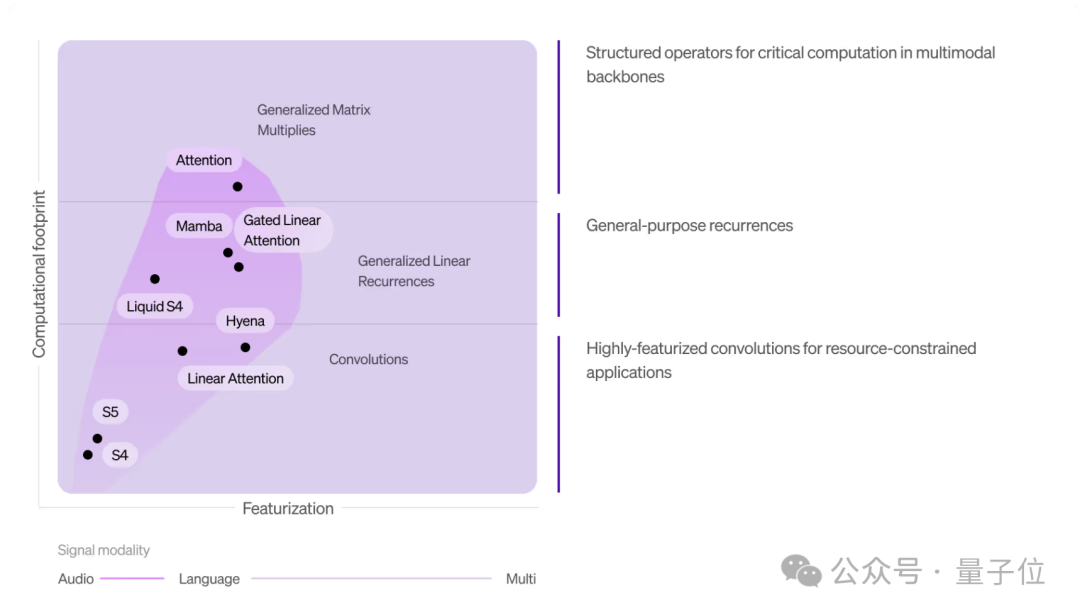
还具有高适应性,可针对特定平台(如苹果、高通、Cerebras、AMD)优化架构,或匹配给定的参数要求和推理缓存大小。
Liquid AI团队直接把目前LFM模型的优缺点都一一列了出来。
现在LFM语言模型擅长通用和专业知识、数学和逻辑推理、长上下文任务。
主要语言是英语,还支持西班牙语、法语、德语、中文、阿拉伯语、日语和韩语。
但LFM语言模型不擅长零样本代码任务、精确的数值计算、时效性信息,人类偏好优化相关技术也尚未广泛应用。
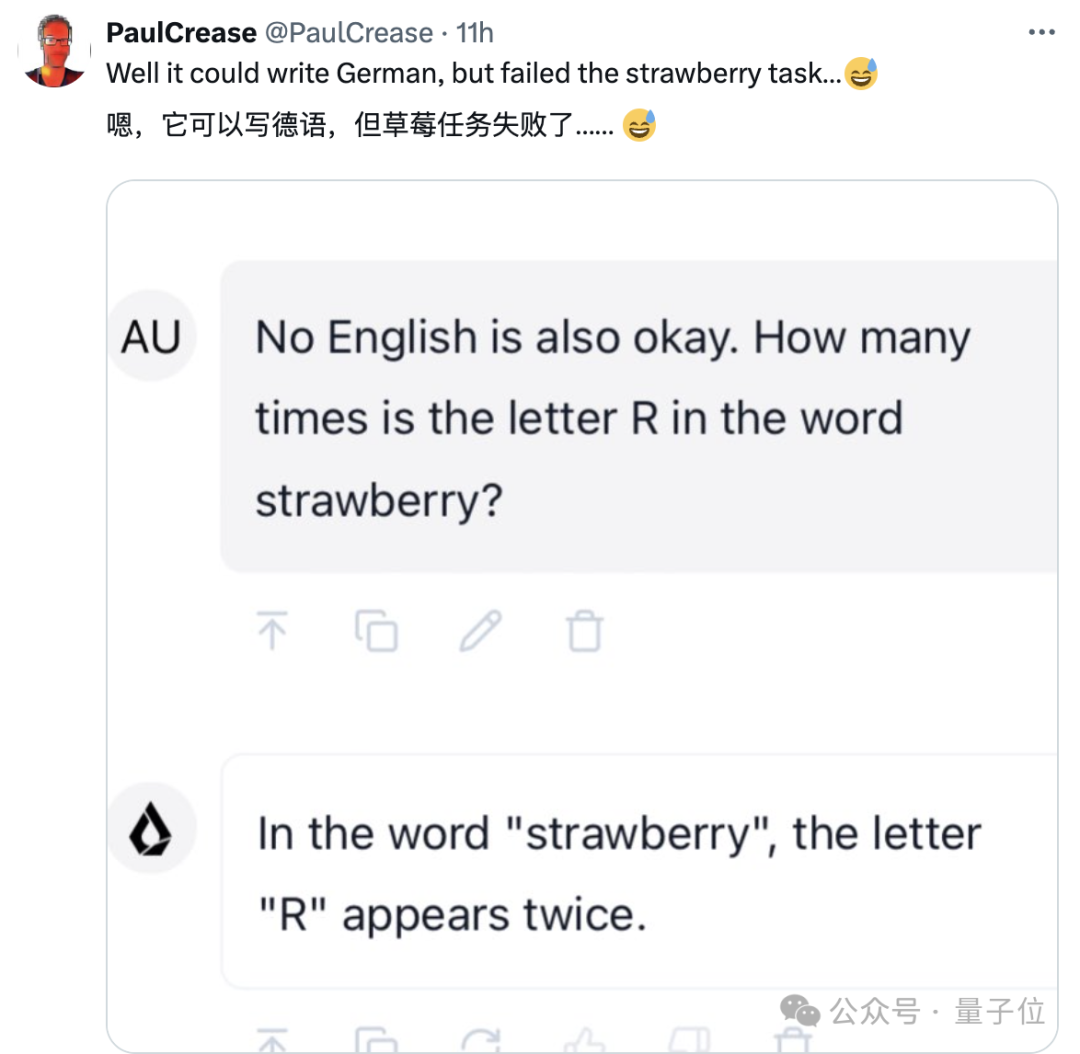
有意思的是,Liquid AI团队还明确表示LFM现在不会数“Strawberry”中“r”的数量。

经网友测试,它确实不会😂。
关于LFM架构更多技术细节,官方表示将持续发布技术Blog。
背后团队来自MIT CSAIL
下面简单介绍一下LFM模型背后团队——Liquid AI。
Liquid AI是一家从MIT计算机科学与人工智能实验室衍生出来的公司。
目标是在每一个规模上构建能力强大且高效的通用人工智能系统。

联合创始人共有四位。
CEO Ramin Hasani,MIT CSAIL人工智能科学家、前Vanguard Group首席人工智能和机器学习科学家。


博士论文研究主题就是关于液态神经网络(Liquid Neural Networks),由维也纳工业大学Radu Grosu教授和麻省理工学院Daniela Rus教授共同指导。

CTO Mathias Lechner,MIT CSAIL研究员。
维也纳工业大学计算机科学的学士、硕士学位,奥地利科学与技术研究所(ISTA)博士学位。
专注于开发稳健可信的机器学习模型。

首席科学官Alexander Amini,在MIT完成了计算机科学学士、硕士和博士学位,同时辅修数学。
研究的领域包括自主系统的端到端控制学习、神经网络的置信度公式化、人类移动性的数学建模以及复杂惯性精细化系统的构建。
另外一位联合创始人是MIT CSAIL主任Daniela Rus,她还是MIT电气工程与计算机科学系的Andrew&Erna Viterbi教授。

Liquid AI成立初就致力于从第一性原理出发构建新一代基础模型,是一个基于深度信号处理和状态空间层扩展语言模型的团队。
之前研究有一箩筐:

感兴趣的的家人们可以自行查阅:
https://www.liquid.ai/blog/liquid-neural-networks-research
对新模型感兴趣的家人们可以测试起来了:
https://playground.liquid.ai/chat?model=cm1ooqdqo000208jx67z86ftk
参考链接:
[1]https://x.com/LiquidAI_/status/1840768722665189596
[2]https://venturebeat.com/ai/mit-spinoff-liquid-debuts-non-transformer-ai-models-and-theyre-already-state-of-the-art/
- 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品2025-04-14
- 4090玩转大场景几何重建,RGB渲染和几何精度达SOTA|上海AI Lab&西工大新研究2025-04-13
- 阿里云造“Agent工厂”,百炼MCP服务上线,无需代码5分钟建Agent2025-04-09
- 又一上海人形机器人加入开源!全套图纸+代码,来自傅利叶2025-04-11