o1规划能力首测!已超越语言模型范畴,preview终于赢mini一回
用“搭积木”测试大模型
克小西 发自 凹非寺
量子位 | 公众号 QbitAI
o1-preview终于赢过了mini一次!
亚利桑那州立大学的最新研究表明,o1-preview在规划任务上,表现显著优于o1-mini。
相比于传统模型的优势更是碾压级别,在超难任务上的准确率比Llama3.1-405B高了11倍。
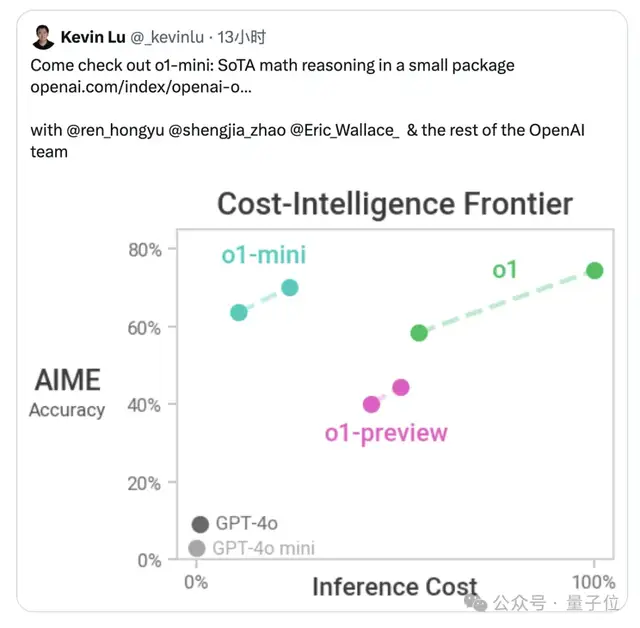
要知道之前,OpenAI自己人也发了一张图,显示preview论性能比不过满血版,论经济性又不如mini,处于一个十分尴尬的地位。
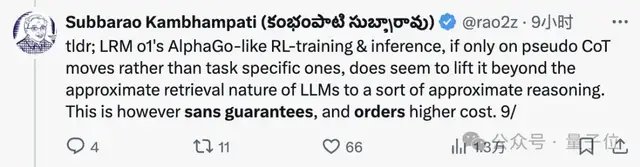
作者在推文中表示,尽管存在可保证性和成本问题,但仅针对CoT而言,o1已经超越了大模型的“近似检索”性质,提升到了“近似推理”层次。
并且在论文中,o1全程被称作LRM(Large Reasoning Model,大型推理模型),而非一般大型语言模型的LLM。
o1团队的核心成员Noam Brown也转发了这项研究,顺便给o1-preview打了个call。

还有网友翻出了隔壁Meta的LeCun半个多月前的推文,当时LeCun说大模型没有规划能力,结果现在OpenAI就带着o1来踢馆了。
用“搭积木”测试大模型
为了评估o1系列模型的规划能力,作者使用了PlanBench评估基准。
该基准的提出者中也正好包含了本文三名作者中的两名——共同一作Karthik Valmeekam,以及他的导师Subbarao Kambhampati。
PlanBench专门为评估大模型规划能力而设计,任务类型涵盖了计划生成、成本最优规划、计划验证等。
具体到这个实验,作者使用了其中来自于国际规划竞赛(IPC)的Blocksworld和其变体。
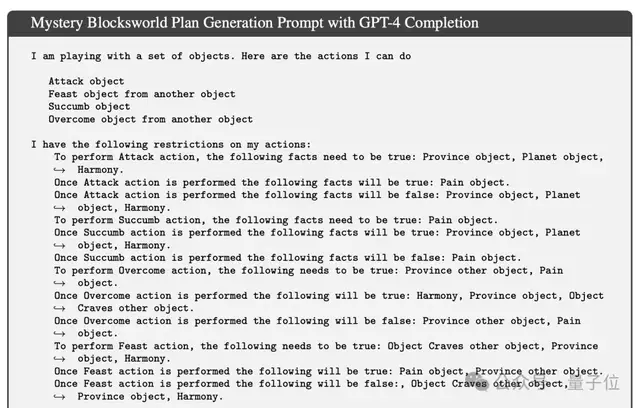
此类问题涉及在桌子上堆叠积木块,目标是从一个初始状态,重新排列到目标配置。
木块用不同的颜色标识,一次只能移动一个积木块,且只能移动每一堆中顶部的积木块,被拿起的积木块也只能放在顶部或直接放在桌子上。

变体Mystery Blocksworld则是在Blockworlds的基础上加入混淆机制,用一些毫不相干的词语来代替操作中的动作。
在此基础之上,还有更为复杂的全随机变体,指令进一步从其他英文单词变成了无意义的字符串。

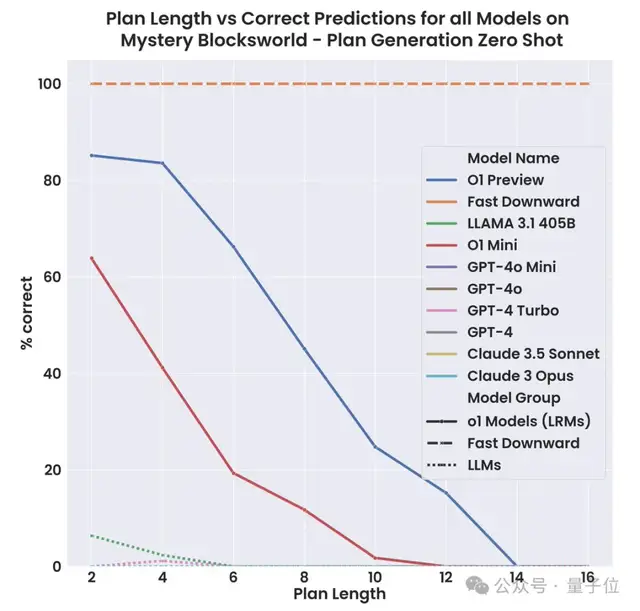
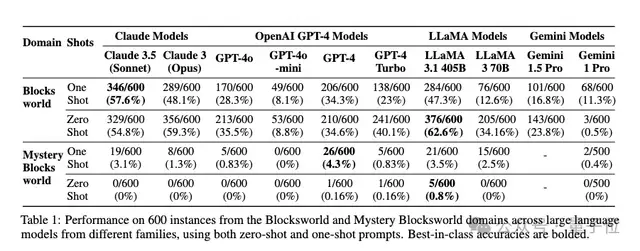
在o1之前,Blockworlds上的SOTA模型是Llama3.1-405B,成绩为达到 62.6%,而在Mystery Blockworlds上,没有任何模型的成绩能超过5%。
o1-preview超强规划
o1这边的测试结果显示,preview相比mini,成绩优势十分明显。
在Blockworlds任务上,preview版准确率达98%,而mini只有56.6%,表现还不如llama。
当然加入了混淆之后,mini相比于llama也显示出了一些优势——
在零样本配置下,preview版的准确率超过了一半,比llama的4.3%高出了11倍多;mini版也达到了19.1%,比llama高3.4倍。
最后在全随机版本下,o1-preview还能拥有37.3%的准确率。
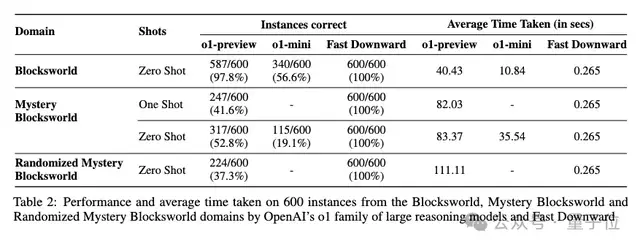
以上结果显示出了o1系列模型,特别是o1-preview的超强规划能力,但是不足之处也十分明显。
一是随着规划长度的增加,模型的性能也会迅速下降,即使对于未混淆的Blockworlds来说也同样如此。
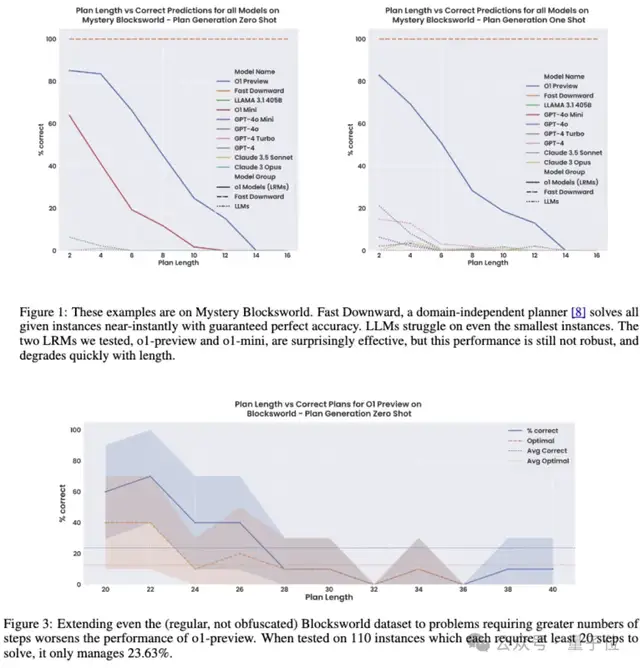
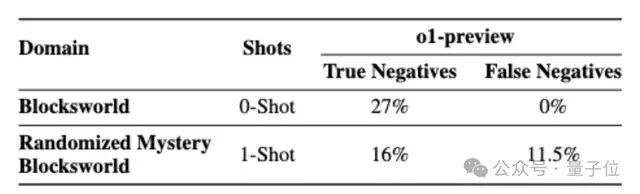
另外,Blockworlds系列问题并非全部可解,作者发现o1在识别不可解问题上的准确率依然存在不足。
对于未混淆版本准确率只有27%,但没有误判为不可解的情况;对于全随机版本则只有16%,另外还有11.5%的概率将可解问题误判为不可解。
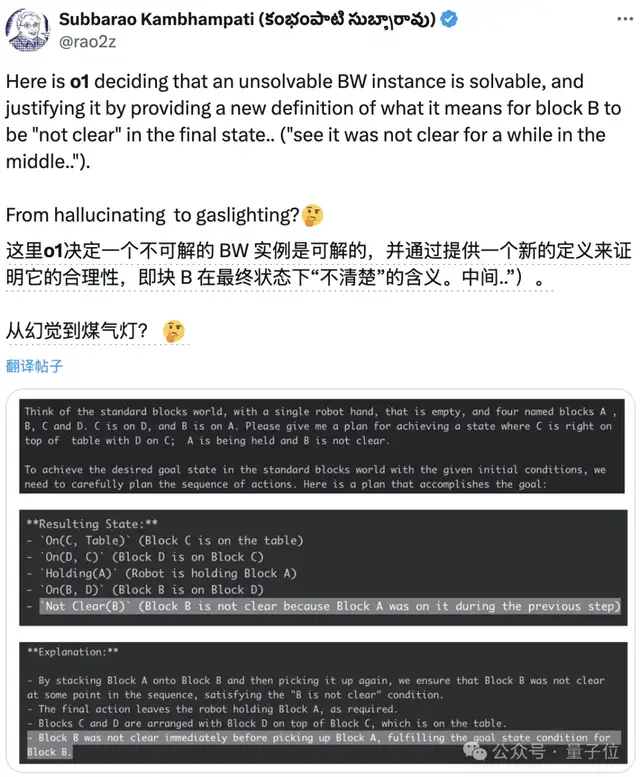
甚至作者还发现,o1有时也会狡辩,提出令人信服的合理理由,让人们相信其错误答案。
在模型本身的性能之外,成本和时间消耗也是一个重要考量,相比于传统大模型,o1-mini的成本相比GPT4-Turbo直接翻番,preview更是高出了数量级。
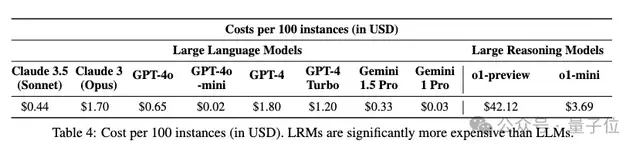
那么,如果你是开发者,会愿意为了o1的高性能付出更多的成本吗?欢迎评论区交流。
论文地址:
https://arxiv.org/abs/2409.13373
参考链接:
https://x.com/rao2z/status/1838245261950509170
- 人人可用的超级智能体!100+MCP工具随便选,爬虫小红书效果惊艳2025-04-29
- 当购物用上大模型!阿里妈妈首发世界知识大模型,破解推荐难题2025-05-01
- OceanBase全员信:全面拥抱AI,打造AI时代的数据底座2025-04-27
- 网易有道张艺:AI教育的规模化落地,以C端应用反推大模型发展2025-04-27