
利用公开知识定向提升大模型,腾讯优图&上交大新方法性能达SOTA
方法不依赖数据集和模型元信息
优图实验室 投稿
量子位 | 公众号 QbitAI
告别传统指令微调,大模型特定任务性能提升有新方法了。
一种新型开源增强知识框架,可以从公开数据中自动提取相关知识,针对性提升任务性能。
与基线和SOTA方法对比,本文方法在各项任务上均取得了更好的性能。
该方法由上海交通大学和腾讯优图实验室共同提出。

研究背景
近年来,LLMs 在众多任务和领域取得了显著发展,但为了在实际业务场景发挥模型的专业能力,通常需要在领域特定或任务特定的数据上进行指令微调。传统的指令微调往往需要大量的有标注数据和计算资源,对于实际业务场景这是很难获得的。
另一方面,开源社区提供了大量的微调模型和指令数据集。这些开源知识的存在使得在特定任务上LLM在特定领域上的适配和应用成为了可能。但是,使用开源的各类SFT模型以及任务相关的数据集时,仍有以下关键问题需要解决:
- 少量有标注样本场景下,直接对模型微调或进行in-context-learning的效果往往不能满足需求,如何利用这些少量的样本和海量的外部知识(开源世界的模型,数据)对目前已有的知识进行补充,提升模型的任务能力和泛化性能?
- 开源社区中有大量微调且对齐的模型和指令数据集,可作为提升 LLMs 特定任务专业能力的良好起点,如何在可能存在知识冲突的情况下,合理融合这些外部知识?现有工作往往聚焦于对已有模型组合方法的设计,无法最大化利用多个模型的知识储备。
- 在开源模型的评价上,现有工作仅仅从单一角度(如测试集上严格答案匹配的准确率)进行性能评估,而忽视了这可能带来的偏差。同时在开源数据的评价上,现有方案通常从通用数据的质量、复杂度等评估角度出发,没有结合任务导向性来实现数据精选。
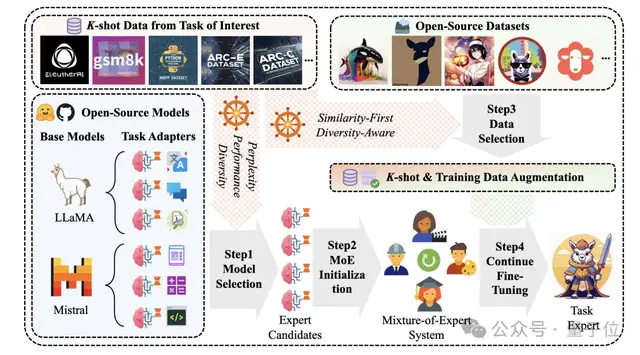
针对以上关键问题,研究团队提出了一种切合业务实际的全新实验设置:K-shot有标签真实业务数据下的开源知识增强框架。在这样的框架下,充分利用K-shot样本来实现LLM的定向任务增强。
具体地,团队设计了一套可轻松尺度拓展的LLM知识增强管线,并且充分发挥少量的K-shot样本在开源模型、开源数据筛选上的指导作用。在方案设计上,主要面临了以下挑战:
挑战1: 对于给定的感兴趣任务,如何充分利用有限的 K-shot 数据,以高效地确定具有最大潜力的模型。
挑战2: 如何从开源数据集中识别与 K-shot 任务相关性最强的一批指令数据,以便为 LLMs 注入、补充缺失的领域知识,同时避免过拟合现象。
挑战3: 当多个 LLMs 均在任务上表现出有效性时,如何构建一个自适应的模型融合系统,以更好地利用这些模型之间互补的知识,从而提高它们在 K-shot 任务中的协同性能并展现出比单模型更优的效果。
本文贡献
本研究提出了一种结合公开可用模型和数据集,针对特定任务提升大型语言模型性能的方法全流程。主要贡献包括:
- 提出了一种高效筛选具有最大潜力的模型的方法,综合推理困惑度,模型表现和模型间知识丰富度进行模型筛选,在有限的 K-shot 数据条件下,能够充分发挥已有模型的性能。
- 设计了一种从开源数据集中提取与感兴趣任务或领域相关知识的方法,通过相似性-多样性的数据筛选策略,为 LLMs 提供补充信息,降低过拟合的风险。
- 通过混合专家模型结构构建了一种自适应的模型融合系统,能够在多个潜在有效的 LLMs 之间实现知识互补和协同优化,从而在感兴趣任务上取得更好的性能。
前提储备:
LoRA Bank Construction:从 Huggingface 选择 38 个具有代表性且广泛使用的指令数据集,对每个数据集进行预处理和 LoRA 微调来构建 LoRA Bank。LoRA Bank的引入为特定任务提供了可选择的预训练模型集合,并保证了实验的可重复性以及对比的公平性。
核心方法:
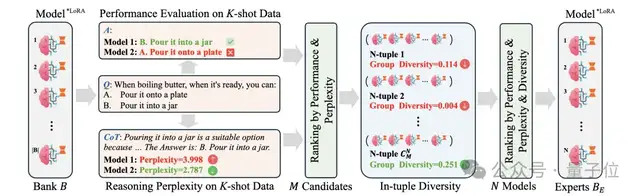
1、K-shot Guided Expert Model Selection:提出一种专家模型选择方法,综合考虑模型的推理困惑度、在K-shot数据上的性能表现以及模型多样性来筛选最有潜力的模型组。
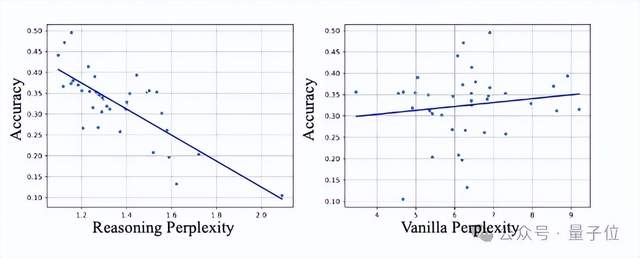
团队发现,仅仅从推理结果的性能评估(通常用后处理+Exact Match等手段来计算)不能很好地预测得到模型在特定任务上的表现。这是因为模型输出的答案可能无法被完全后处理解析,导致模型被低估。
团队发现通过答案的推理困惑度可以判断模型对某一个领域的理解能力,因此综合考虑了这两种手段。
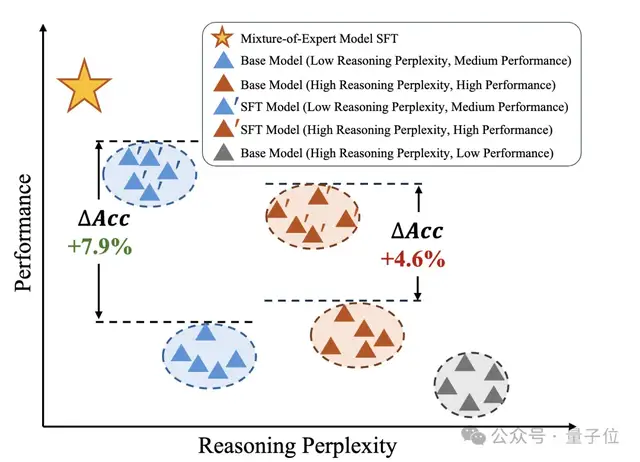
如下图,部分直接推理指标高的模型在微调后表现可能低于原先推理指标低的模型,但推理困惑度低的模型的微调后的性能会比原先困惑度高的模型更强。
此外,还对模型组的组多样性进行了评估,即不同模型的知识的差异性要尽量大,这对于混合专家系统的训练效果有较大提升。
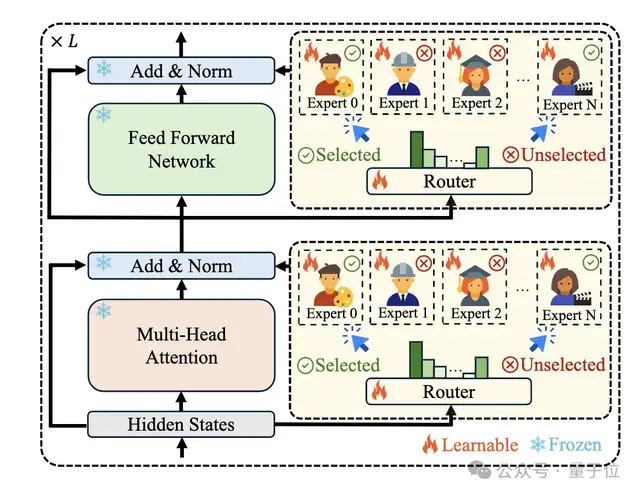
2、Mixture-of-Experts Initialization:使用混合专家模型结构来利用合理利用 LoRA Bank,用模型筛选步骤中得到的模型做MoE模型的初始化,并训练Router使模型能够自动将不同的 token 分配给合适的专家,从而促进不同专家之间的协同合作。
3、K-shot Guided Sim-Div Data Selection:提出一种相似性优先和多样性感知的数据选择策略,通过对原始指令文本进行embedding计算,计算开源数据和K-shot数据相似度,选择与K-shot数据最相似的数据子集,并通过语义层面上的相似度去重来去除重复度过高的数据,保证数据的多样性。
数据相似度-多样性的平衡是筛选过程中着重考虑的点,相似的数据能保证和当前任务的强相关性,多样性的引入能保持数据整体的丰富度和信息充分性,防止模型过拟合的情况的出现。
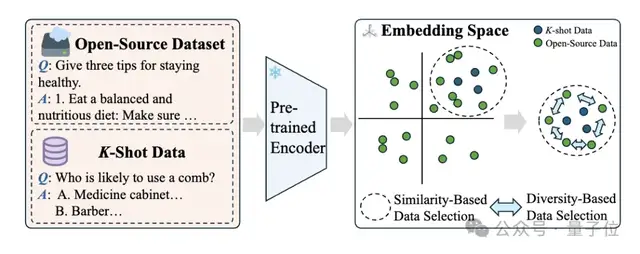
4、Mixture-of-Experts Fine-Tuning:结合增强数据集和K-shot数据集来优化 MoE 系统的Router权重和专家权重,使用交叉熵损失来监督语言建模的输出。
实验设置
数据集:使用六个开源数据集(ARC-Challenge、ARC-Easy、PiQA、BoolQ、MBPP 和 GSM8K)作为评估集,从每个数据集的官方训练集中随机采样K条有标注的指令-响应对作为 K–shot数据。
基线:与五种基线方法(基础模型、随机选择模型、基于整个训练集微调的模型、在测试集上表现最佳的专家模型、对最佳专家进行微调的模型)以及其他 SOTA 方法进行比较。
实验结果与分析
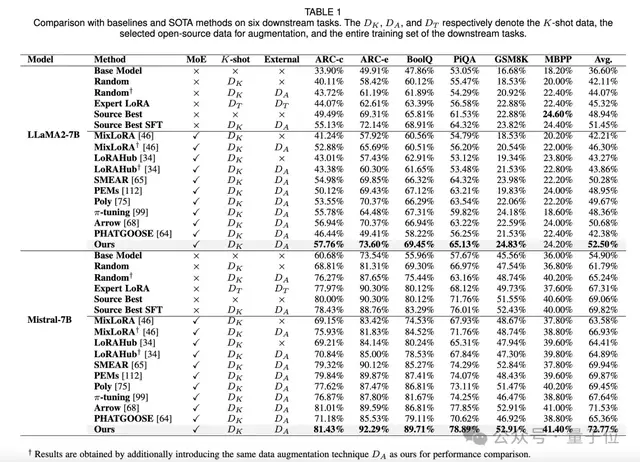
1、与基线和 SOTA 方法对比,本文方法在各项任务上均取得了更好的性能。
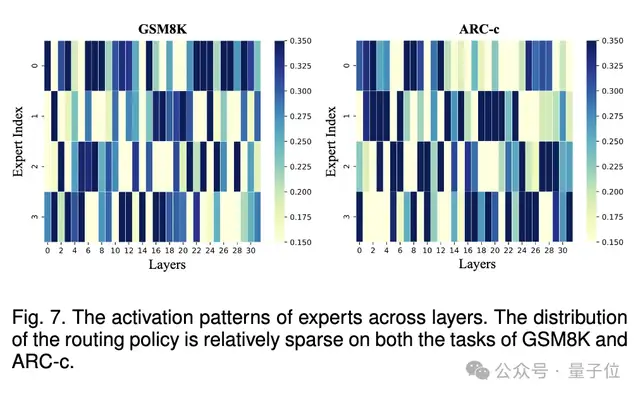
2、通过可视化专家的激活模式,发现 MoE 系统没有等效地坍缩为单个模型,每个专家都对整体有贡献。
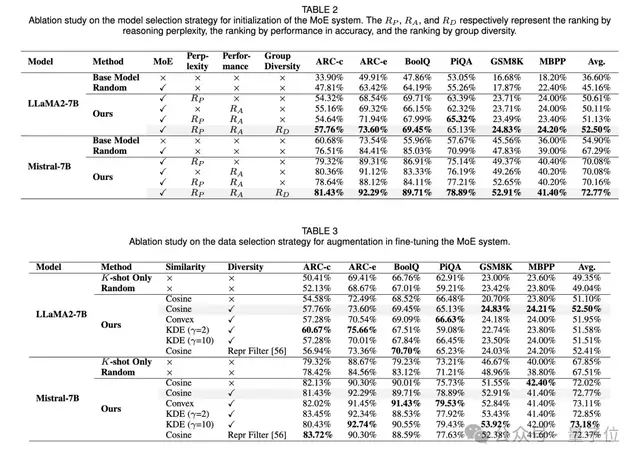
3、在模型选择的消融研究中,综合考虑评测性能、推理困惑度和模型多样性来选择有潜力的模型优于单一依赖 K – shot 性能或推理困惑度的方法,且推理困惑度比普通困惑度在模型选择中更有效。
4、在数据选择的消融研究中,基于相似性优先和多样性感知的数据选择策略进一步提高了 MoE 系统的性能,同时发现增加数据量时性能先上升后下降,多样性在平衡分布和缓解过拟合方面起着重要作用,不同的相似性采样技术对性能也有影响。
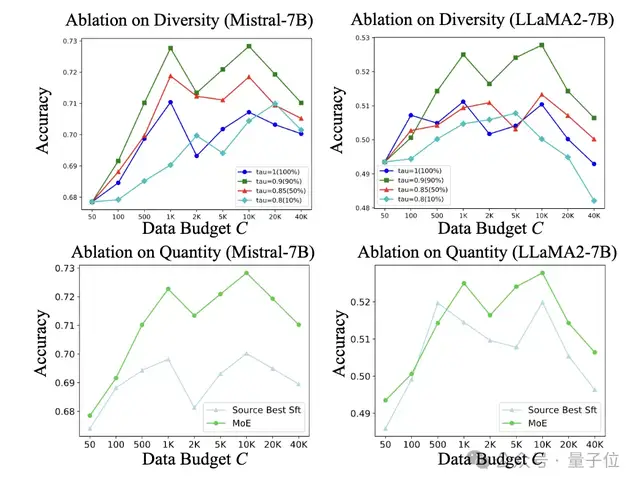
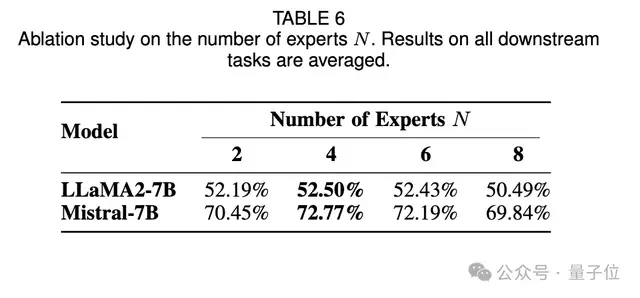
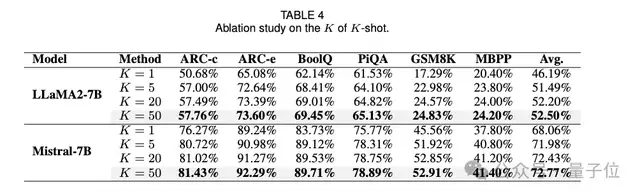
5、在对 K、N 和 k 的消融研究中,发现增加仅仅需要K=5,即5条有标注样本在感兴趣任务上的就可以取得不错的效果。
专家候选者之间的差异对于维持任务导向的 MoE 系统至关重要。此外MoE 系统训练所需的数据量应根据任务进行优化,更困难的任务需要更多高质量训练数据。总的训练数据的数量不能太多,随着k的增加,模型性能会出现先上升后下降的趋势,证明和任务数据相似度较高的外部数据的引入才能对模型性能有所提升。
从LoRA Bank中选出的专家数量N不需要很多,证明和模型高相关性的适配器的引入才能增强模型的任务能力。
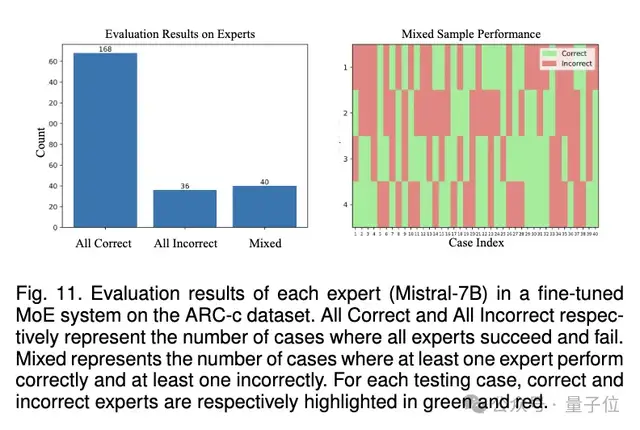
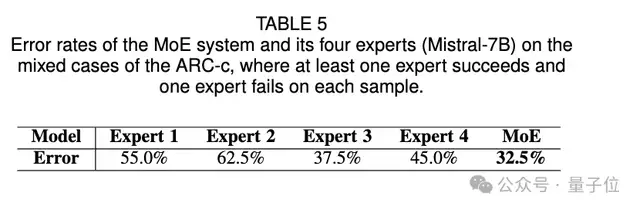
6、对MoE组合的有效性分析:将数据划分为All-correct,All-incorrect,Mixed三类数据,其中Mixed代表至少有一个专家做对且至少有一个专家做错(不同专家出现分歧)的样本,通过MoE的方式,不同专家的融合能超过最优的专家的效果,证明MoE组合方案的有效性。
讨论
本方法不依赖数据集和模型的元信息,这是本方法的一大优势。实际场景下,数据和模型的源信息可能会存在描述不详细、难以确定相关数据点等问题。开源模型的训练数据/训练细节很难具体获得。
该方法具有多任务适用性和易用性,大多数开源 LLMs 是 LLaMA 和 Mistral 家族的变体,可通过 Huggingface 获取大量模型,但不同 PEFT 方法之间计算模型间相似性可能不兼容。
结论
本文提出的方法通过 K – shot 数据在模型选择和数据扩增中发挥重要作用,优于现有方法,并通过消融研究验证了选择方法的有效性,展示了一种挖掘开放知识进行定制技能整合的高效流程。
- 图像编辑开源新SOTA,来自多模态卷王阶跃!大模型行业正步入「多模态时间」2025-04-28
- 不要思考过程,推理模型能力能够更强丨UC伯克利等最新研究2025-04-29
- 首份空间智能研究报告来了!一文全面获得空间智能要素、玩家图谱2025-04-26
- 拜拜邀请码!首个现货超级智能体实测2025-04-26




