开源版《Her》来了,技术报告已公开!大神Karpathy:它很有个性
实时语音模型Moshi
大神Karpathy鼎力推荐,开源版「Her」Moshi再引关注!
(Moshi)的性格非常有趣,它会突然断断续续,有时会无缘无故沉默……
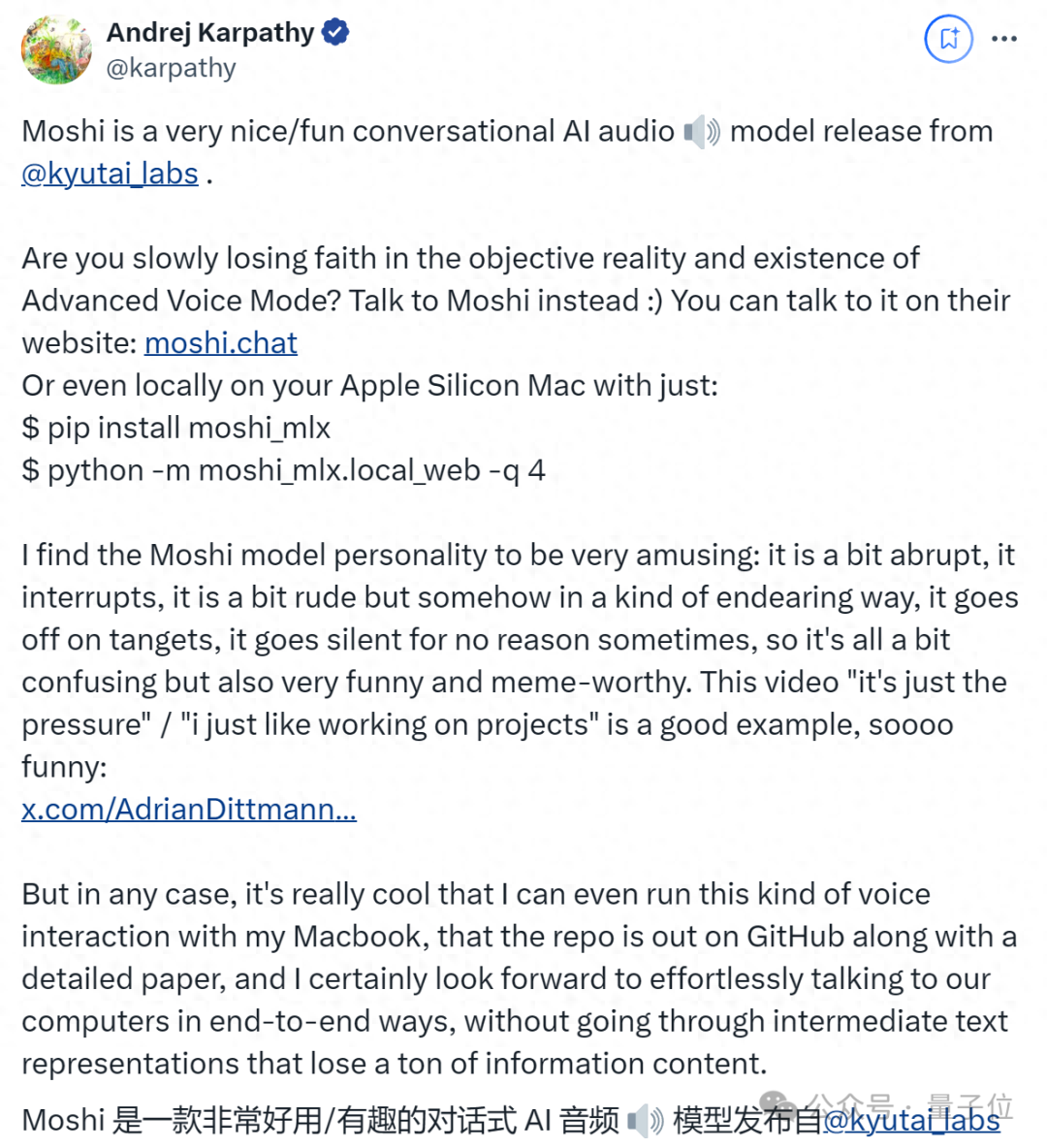
据了解,Moshi是一款端到端实时音频模型,于今年7月初由一家法国创业团队Kyutai发布。
不仅发布后人人免费可玩,而且就在刚刚,Kyutai将Moshi的代码、技术报告来了个大公开。
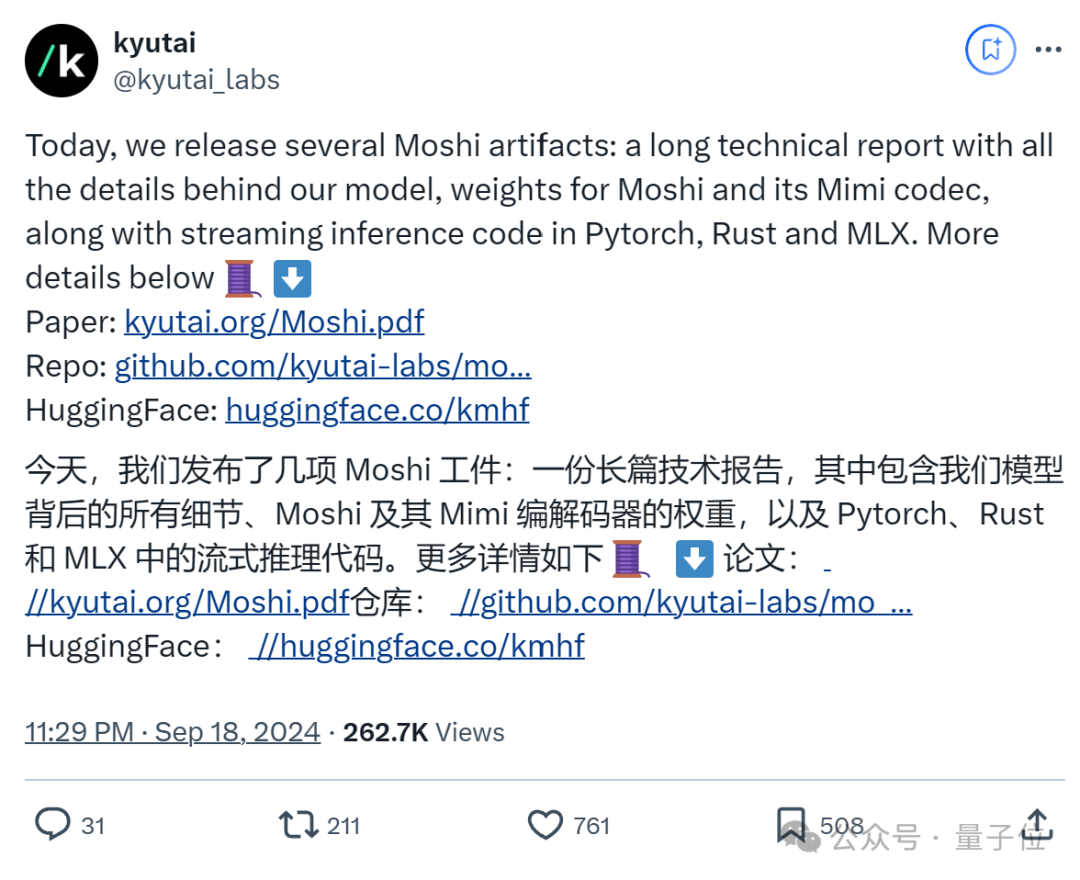
这波属实惊喜了,当初抢先试玩的谷歌DeepMind研究员、ViT作者Lucas Beyer闻声赶来:
(刚好)我最近就想知道这个问题
开源工程师Sebastian Rojo原地启动好学模式。
是时候学起来了!
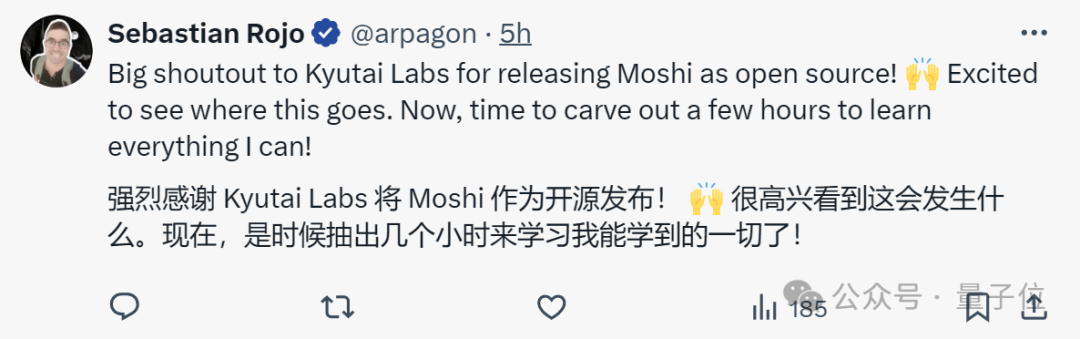
当然,一直慢腾腾的OpenAI再次被“当众处刑”。(其高级语言模式7月底上线后,仍只面向小部分人开放)
惊人的!当我们仍在等待OpenAI的高级语音模式时,人们可以开始使用Moshi并进行构建。

Moshi技术细节大公开
话不多说,先来开个箱,看看Kyutai这次放出了哪些东西。
- 一份长篇技术报告。揭露Moshi模型背后细节、权重、代码;
- GitHub官方仓库;
- HuggingFace模型库;
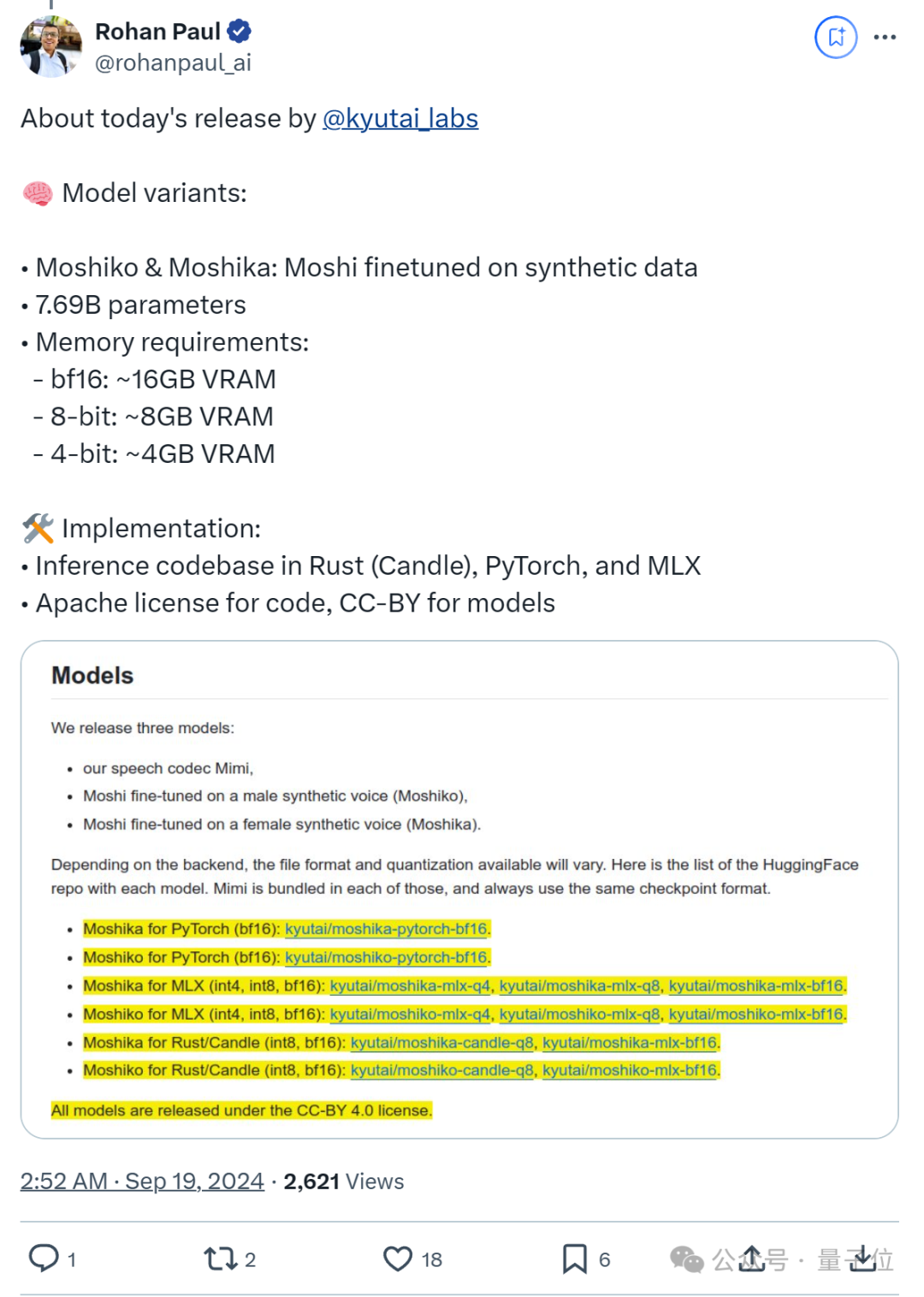
首先来看模型。Kyutai这次发布了3个模型,分别是Moshiko、Moshika,以及Mimi流语音编解码器。
Moshi的参数大约为7.69B,Moshiko/ka是Moshi对合成数据进行微调后的变体,分为男女两个声音。
还可以让它们自行对话, be like:

可以看出,它们都能在一台MacBook上运行,且据介绍,这些模型在L4 GPU上实现了约200毫秒的延迟。
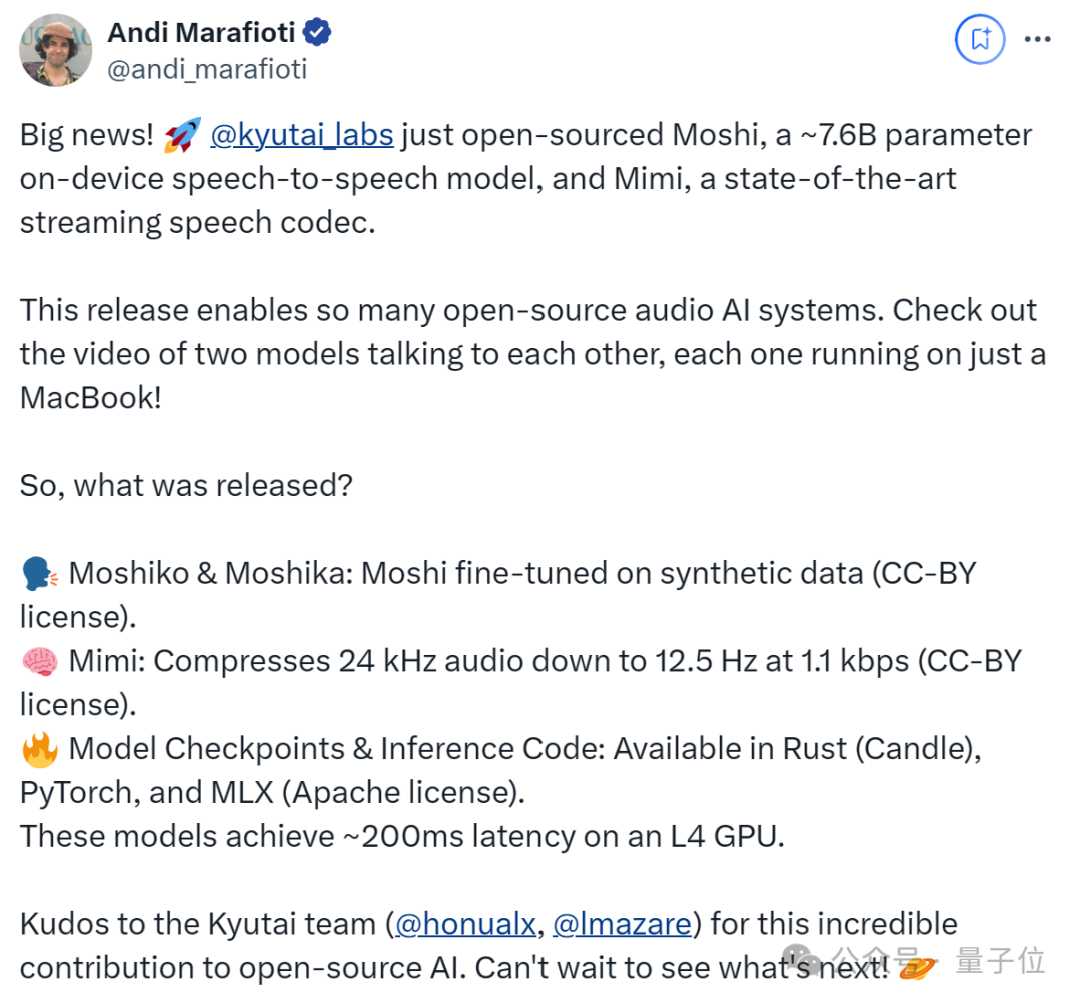
至于变体的内存需求,bf16、8位和4位精度,对应的内存分别为16GB、8GB和4GB VRAM。
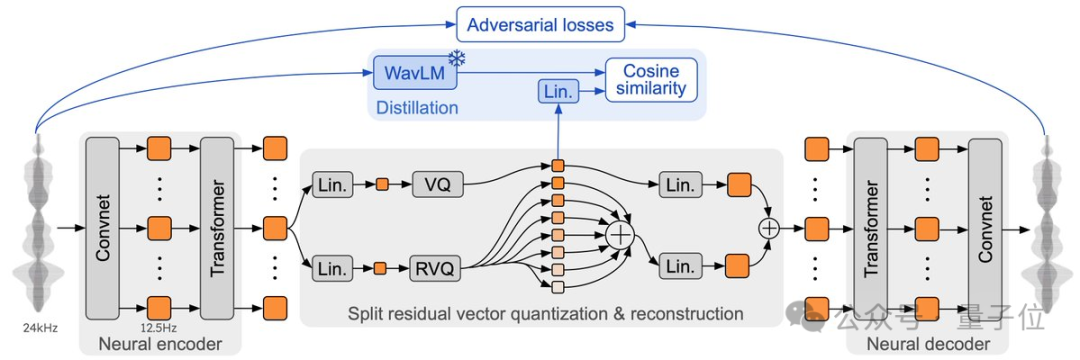
另外,Moshi使用了一个名为Mimi的流式神经音频编解码器,能够处理24 kHz音频(以1.1kbps的速度将24 kHz音频压缩至12.5Hz),并且支持多种预训练模型。
Mimi受SpeechTokenizer启发,通过蒸馏技术联合建模语义和声学信息,并且通过对抗性训练提升了性能,专门用来和大语言模型协同工作。
其次,从官方公布的技术细节来看,Moshi项目主要由三个组件构成:
- Helium语言模型(拥有70亿参数并在2.1万亿tokens上进行训练)
- Mimi神经音频编解码器(能够建模语义和声学信息)
- 一种新的多流架构(能够在单独的频道上分别对用户和Moshi的音频进行建模)
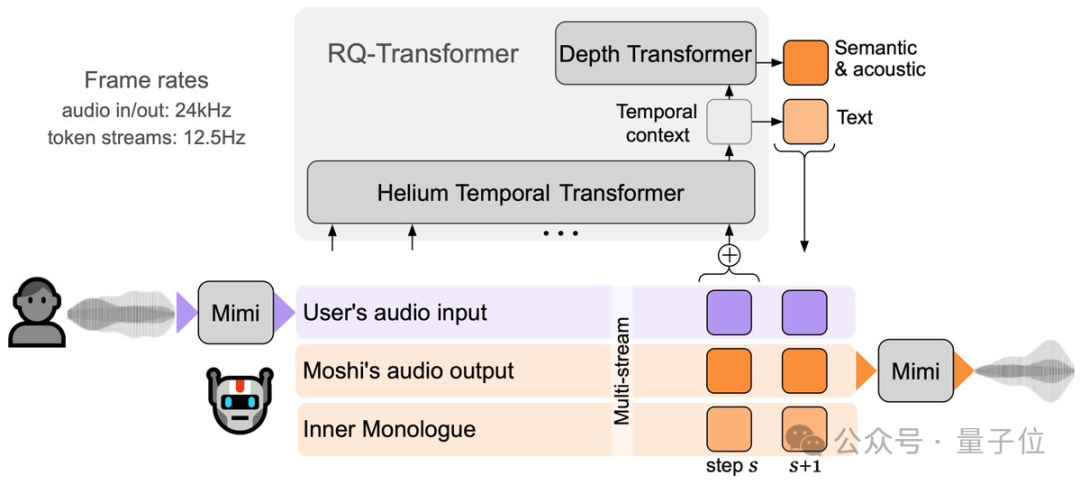
展开来说,Moshi团队对Helium进行了增强,采用了RQ-Transformer变体架构,这使得Helium能够在不增加序列长度的情况下建模语义和声学标记的层次结构。
官方自称,他们对生成音频的主要贡献是多流建模技术(multi-stream modeling)。
能够在每个时间步中堆叠Moshi和用户的tokens,以模拟全双工对话的动态,包括重叠、反向通道和中断等。
还包括内心独白技术(Inner Monologue),它进一步提高了生成语音的质量,通过预测时间对齐的文本来增强Moshi的智能性,同时保持与流媒体的兼容性。
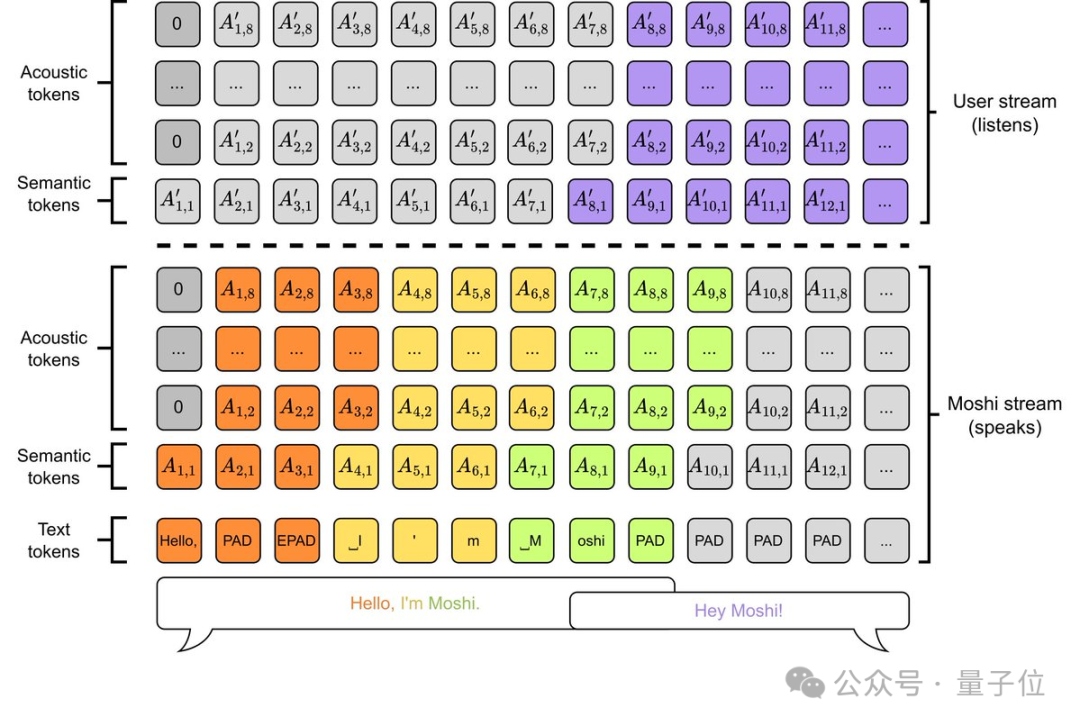
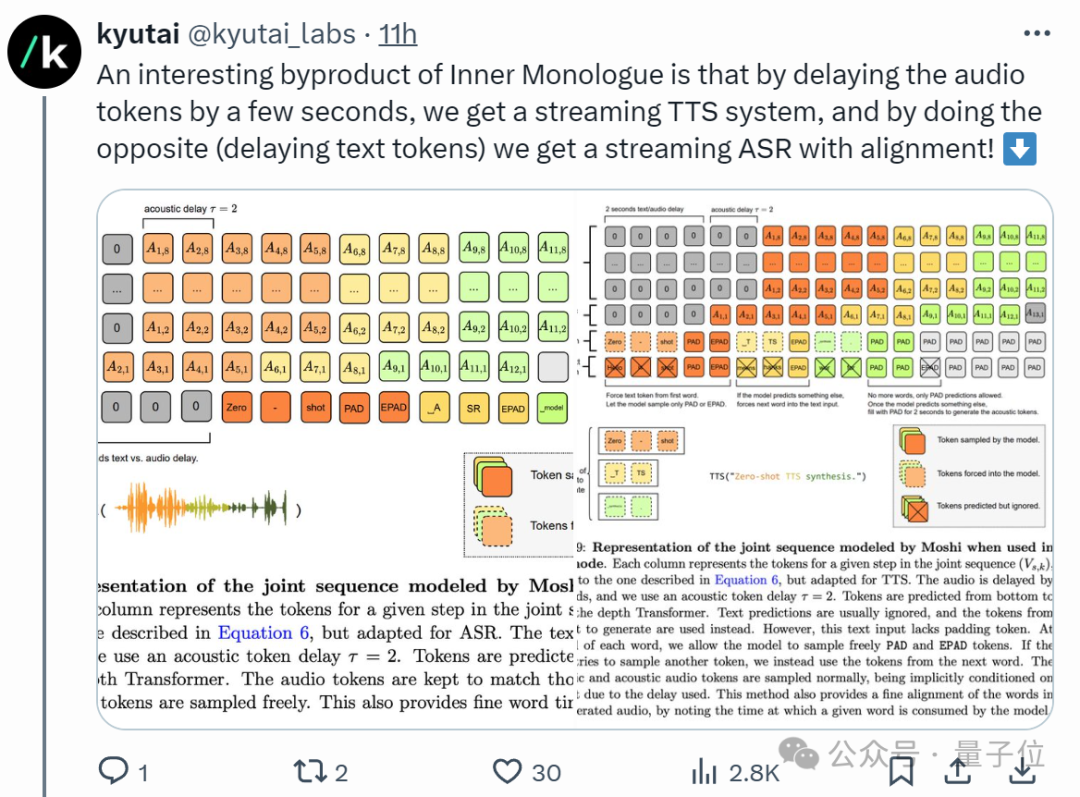
此外,“内心独白”的一个延伸是:通过调整音频和文本标记的延迟,Moshi能够实现流式TTS和ASR功能。
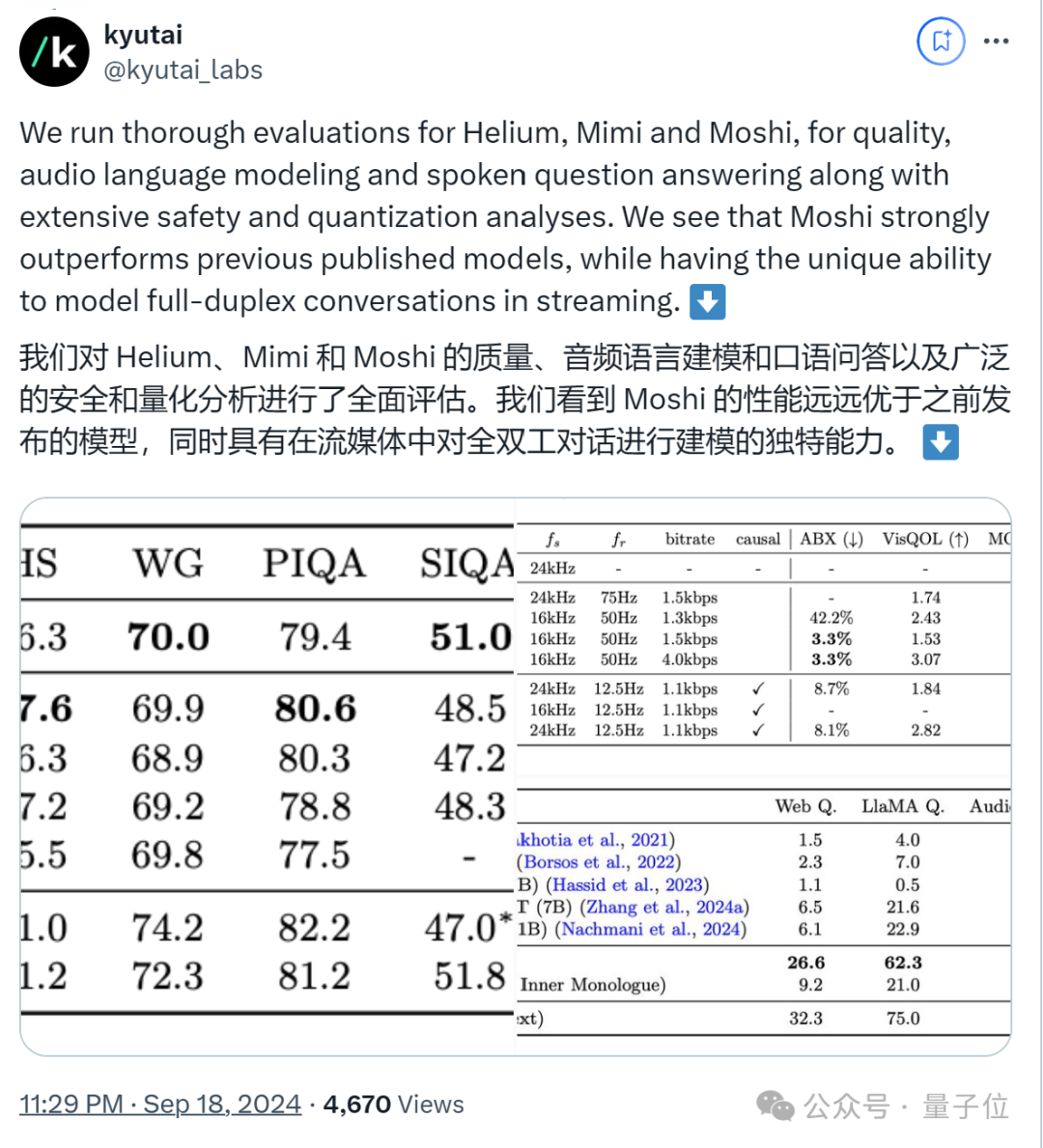
在大规模音频预训练后,官方利用自己的模型创建了20k小时的合成对话数据,用于评估Moshi在质量、音频语言建模和口语问答方面的表现,以及进行了安全和量化分析。
评估结果显示,Moshi在性能上优于之前发布的模型。
OpenAI版「Her」仍未开放
眼见Moshi这次来了个大公开,一众网友又纷纷想起了OpenAI。
今年7月底,OpenAI高级语音模式面向部分plus用户上线,一些试玩例子也随之流出……
比如让ChatGPT开口讲中文,这浓浓的「歪果仁」口音是怎么回事。
再比如让它来段绕口令,围观网友笑cry了。
一番试玩下来,网友们期待值拉满。
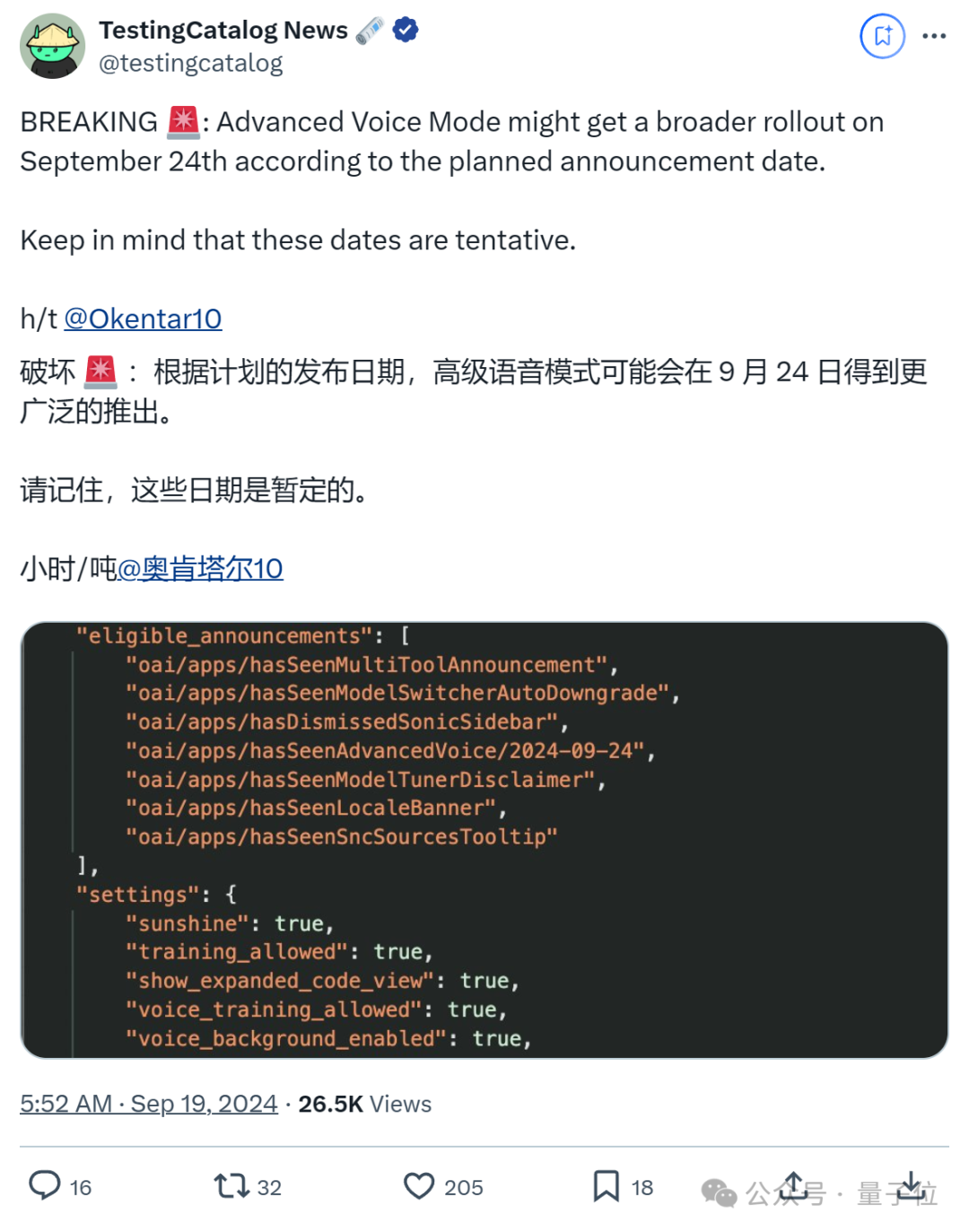
然而,OpenAI的动作实在有亿点慢了,当时曾计划秋季时让所有plus用户都能用上高级语音模式。
然而至今没有更多消息,相关话题的实时页面下,随处可见一片抱怨。
以至于Moshi发布后,再次有网友调侃:
开源总是胜利!
不过也有爆料称,OpenAI可能会在9月24日发布高级语音模式。
一周之后咱们见分晓!
- 轻松健康集团高玉石:AI产品和用户走得够近才能挖到新需求丨中国AIGC产业峰会2025-04-23
- AI火花集|10位AI火花先锋揭晓,看AI应用如何“改写”商业世界?2025-04-17
- 中杯o3成OpenAI“性价比之王”?ARC-AGI测试结果出炉:得分翻倍、成本仅1/202025-04-23
- 人形机器人半马冠军,为什么会选择全尺寸?2025-04-20