单图解锁全景视角!北大/港中文/腾讯等推出ViewCrafter | 已开源
还支持文生3D、图生3D
随便给张图就能从更多视角查看全景了?!
话不多说,先看一波效果,单视角输入be like:


难度升级,接下来换成双视角,看起来衔接也非常丝滑。


以上来自ViewCrafter,由北大、港中文、腾讯等机构的研究人员提出,可以从单张或稀疏输入图像生成精确相机可控的新视角视频。

还支持场景级文生3D、图生3D、以及稀疏视角重建等应用。


目前论文和代码均已开源,并提供了在线Huggingface demo供用户使用。
ViewCrafter:一种新视角生成方法
传统的新视角生成方法,如NeRF和3D-GS等技术,存在一个痛点:
依赖于密集的多视角训练数据
这限制了它们在仅有稀疏(输入图像数量有限,不能提供完整视角或详尽场景信息)甚至单张输入视角的情况下的应用。
同时,传统方法对训练资源的需求较高,且不具备泛化能力,这限制了它们在训练资源受限场景下的应用。
因此,ViewCrafter最终想实现:
从稀疏视角图像甚至单张输入图像中生成任意规模场景的新视角。
这需要模型对3D物理世界有全面的理解。
接下来一起康康具体咋实现的。

概括而言,ViewCrafter是基于点云先验的可控视角视频生成。
首先,快速多视图/单视图stereo技术的发展,使得从单张或稀疏图像中快速重建点云表征成为可能。
点云表征能够提供3D场景的粗略信息,支持精确的相机位置控制以实现自由视角渲染。
然而,由于点云的表示能力较弱,加之极其稀疏的输入图像只能提供有限的3D线索,重建出的点云存在大面积的遮挡和缺失区域,并可能面临几何形变和点云噪声。
这些问题限制了其在新视角合成上的应用。
与此同时,在大规模视频数据集上训练的视频扩散模型能够深入理解3D物理世界,支持从单张图像或文本提示中生成符合物理规律和现实世界规则的视频内容。
然而,现有的视频扩散模型缺乏显式的场景3D信息,因此在视频生成过程中难以实现精确的相机视角控制。
针对这些优缺点,团队提出将视频扩散模型的生成能力与点云表征提供的显式3D先验相结合,以实现相机精准可控的任意场景高保真度新视角视频生成。
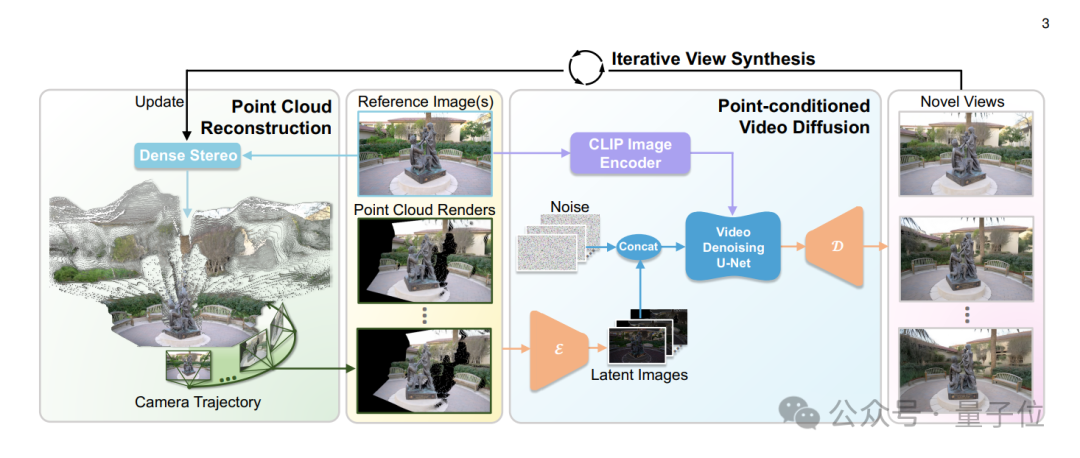
具体而言,给定单张或稀疏视角输入图像,团队首先使用快速多视图stereo方法构建其点云表征,以实现精准地移动相机进行自由视角渲染。
随后,为了解决点云渲染结果中存在的大面积缺失区域、几何失真和点云伪影,团队训练了一个以点云渲染结果为控制信号的视频扩散模型作为增强渲染器。
这一渲染器能在粗糙的点云渲染结果的基础上进一步生成具有高保真度和3D一致性的新视角。
通过结合点云提供的显式3D信息以及视频扩散模型的强大生成能力,新方法能够在视频生成过程中实现6自由度的精准相机位姿控制,并生成高保真度、一致性强的新视角视频。
△相机轨迹规划算法
此外,现有的视频扩散模型难以生成长视频,因为长视频推理会造成巨大的计算开销。
为了解决这一问题,研究采用了一种迭代式的新视角生成策略,并提出了一种内容自适应的像机轨迹规划算法,以逐步扩展新视角覆盖的区域和重建的点云。
具体来说,从初始输入图像构建的点云开始,团队首先利用相机轨迹规划算法,从当前点云预测一段相机轨迹,以有效揭示遮挡和确实区域。
接着,团队根据预测的轨迹渲染点云,并利用ViewCrafter根据渲染的点云生成高质量的新视角。
随后利用生成的新视角更新点云,以扩展全局点云表征。
通过迭代执行这些步骤,最终可以获得覆盖大视场范围和扩展点云的高保真新视图,并支持高斯重建等下游任务。
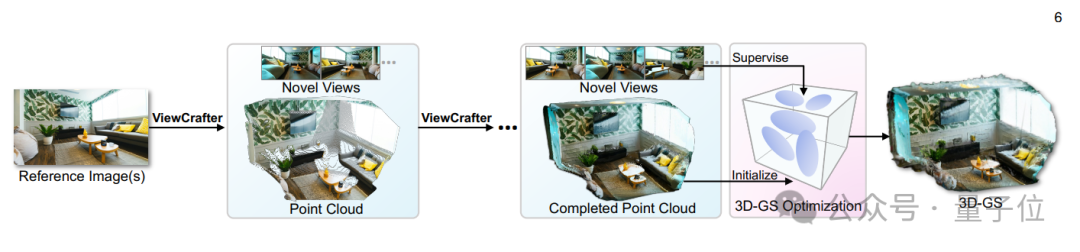
具体应用上,基于ViewCrafter和提出的迭代式新视角生成算法,可以从单张图像/稀疏视角甚至一段文字描述中进行3D高斯重建,以支持实时渲染和沉浸式3D体验。
对比实验
团队从多个角度对比了新方法。
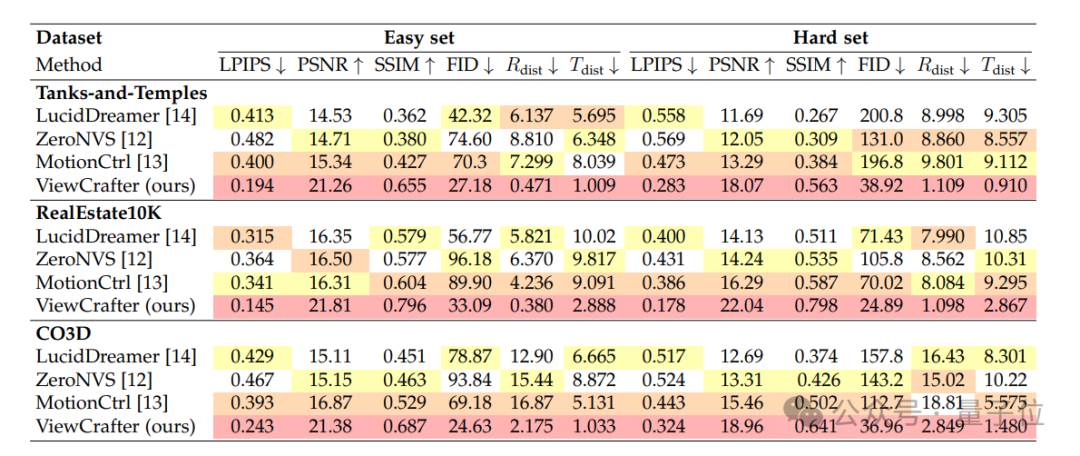
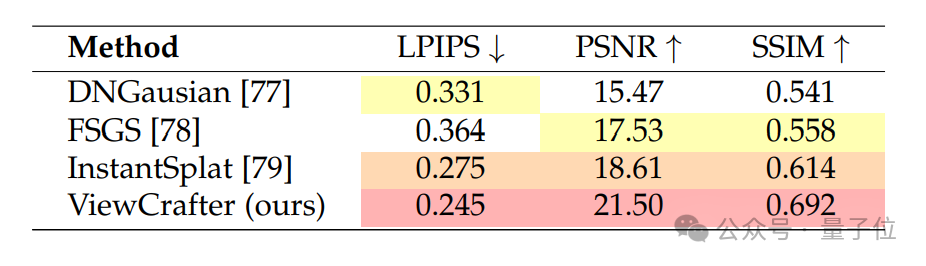
从新视角生成来看,团队在Tanks-and-Temples,CO3D, RealEstate10K这三个真实世界数据集上与SOTA方法进行了定量和定性比较。
实验结果证明,ViewCrafter在相机位姿控制的精准程度,以及生成新视角的视觉质量上都优于对比方法。

在场景重建方面,团队在Tanks-and-Temples数据集上与稀疏视角重建领域的SOTA方法进行了定量和定性比较。
结果证明,ViewCrafter在3D高斯重建渲染出的新视角的视觉质量上也超过了对比方法。

文生3D结果如下。左边显示了文本提示以及文生图效果,后面是最终的3D效果。

当然,团队也进行了消融实验。
比如利用点云先验作为视频扩散模型控制信号的有效性。
具体而言,一些同期工作采用普吕克坐标作为视频生成模型的控制信号,以实现相机可控的新视角生成。
作为对比,为了验证点云控制信号的优越性,团队训练了一个以普吕克坐标为控制信号的新视角生成模型,并进行控制变量实验,保证除了控制信号外其他模型结构与ViewCrafter一致。
两个模型在新视角生成任务上对比结果如下所示:
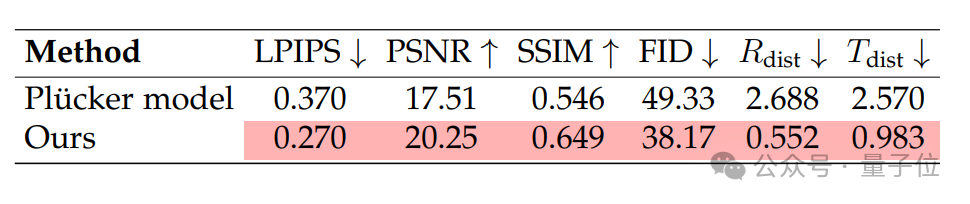

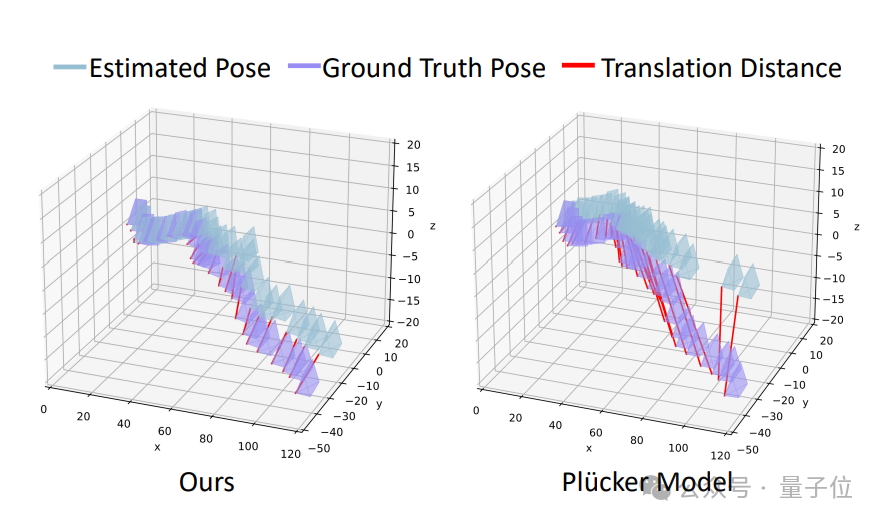
实验结果证明,不管是在新视角生成质量还是在相机控制的精准程度上,团队使用的基于点云的控制信号都要优于基于普吕克坐标的控制信号。
另外,团队验证了模型对粗糙点云的鲁棒性。
如图所示,对于作为控制信号的点云具有严重几何形变的情况,模型依然能够有效地进行几何纠错和空洞修补。
这证明了新方法对点云控制信号的鲁棒性。

概括下来,团队验证了ViewCrafter对于静态场景的强大新视角生成能力。
接下来,团队计划探索和单目视频深度估计方法结合,实现单目动态视频的新视角生成和4D重建。
更多细节欢迎查阅原论文。
- 用多模态LLM超越YOLOv3!强化学习突破多模态感知极限|开源2025-05-03
- OpenAI最新技术报告:GPT-4o变谄媚的原因万万没想到2025-05-03
- 数学家们仍在追赶天才拉马努金2025-04-27
- Qwen3真香!通义App满血接入,一手实测在此2025-04-30