
上交大推出“可进化游戏引擎”!大模型加持代码自动成长,虚拟世界演化无需预设
游戏NPC在线掌握人生
WY 投稿 凹非寺
量子位 | 公众号 QbitAI
试问谁小时候没有幻想过有一只专属于自己的宝可梦?(可以DIY的那种~)
最近上海交通大学、哈工大深圳校区联合团队整了个“可进化游戏引擎”,实现了这个儿时梦想:
大模型与传统游戏引擎结合,能够被被特定的条件触发,自动地成长出新的代码。
选择宝可梦题材做实验,是因为团队中大部分成员都是宝可梦粉丝,目前相关论文已上传ArXiv平台。

「失控玩家」走进现实
研究团队用电影《失控玩家》中的主人公 “Guy”举了一个的例子。
Guy原本是虚拟游戏中的一名NPC,每天都生活在被规划好的剧本里,每天重复着相同的事情。但在阴差阳错下,他却拥有了改变生活、打破剧本的能力。
研究人员们非常希望在其他游戏中也能看到类似的情节 ———NPC在线进化。
例如被蜘蛛咬到、发现奇妙的宝藏等,从而解锁全新的能力,甚至有可能在某一天转变为反派角色。
不过他们幻想的内容大多数并不在虚拟世界的剧本中,无法被实现。
因此,他们将虚拟世界的进化特性联系到了其背后引擎的可拓展性:当前虚拟世界的引擎不具备可拓展性,无法拓展出新的内容,从而无法发生进化。
于是他们提出了一种全新的引擎Delta-Engine,它能够被特定的条件触发,从而自动地成长出新的代码。
Delta-Engine由两个组件构成:
基座引擎(Base Engine):一个原始的引擎,它刻画了虚拟世界最初的样子,代表了其静态的部分。
代理模型(Neural Proxy):一个神经网络作为基座引擎的外包装,它代表了虚拟世界可变的部分,特定的输入能够触发它在基座引擎的基础上生成新的代码。
研究人员选择了一个大语言模型作为基础,他们认为大语言模型还能够支持多种类型的输入,例如文本、图像、以及脚本语言,有利于虚拟世界的打造。
而针对Delta-Engine的可拓展性,他们也相应提出了一种高效的拓展方式,叫做增量预测。
简单来说,就是让代理模型预测基座引擎上的新增内容。
他们还强调,仅对于代理模型来说,增量预测和上下文学习、RAG是相交的概念。但增量预测是对于整个Delta-Engine而言的概念,它和基座引擎的设计密切相关。
DIY专属宝可梦
基于Delta-Engine,研究人员们打造了一款类虚拟世界的概念游戏。
因为团队大部分人都是宝可梦游戏的粉丝,因此他们决定把主角定为一只可进化的宝可梦,打造一款名为Delta-Pokémon的游戏。
在传统的宝可梦游戏中,各个角色的内容包括其成长模式都是被预设好的。
而在Delta-Pokémon中,玩家将为自己量身定做一只专属宝可梦,从最初阶段的白板宝可梦,通过不断的对战,从而进化学会全新的能力。
每一次进化将完全取决于玩家的意愿,玩家可以通过自然语言,根据自己的喜好任意地编写新的属性、特性、以及技能。

研究人员称其为开放角色扮演游戏(ORPG),每一名玩家的游戏中角色都会各不相同。
他们认为,玩家在虚拟世界中的形象是他在真实世界中的映射,能够反映玩家的某种欲望,可能是对现实世界的抽离、或是对现实世界的深入。
ORPG带来的开放性,能够极大程度满足玩家对自我的另一种表达。
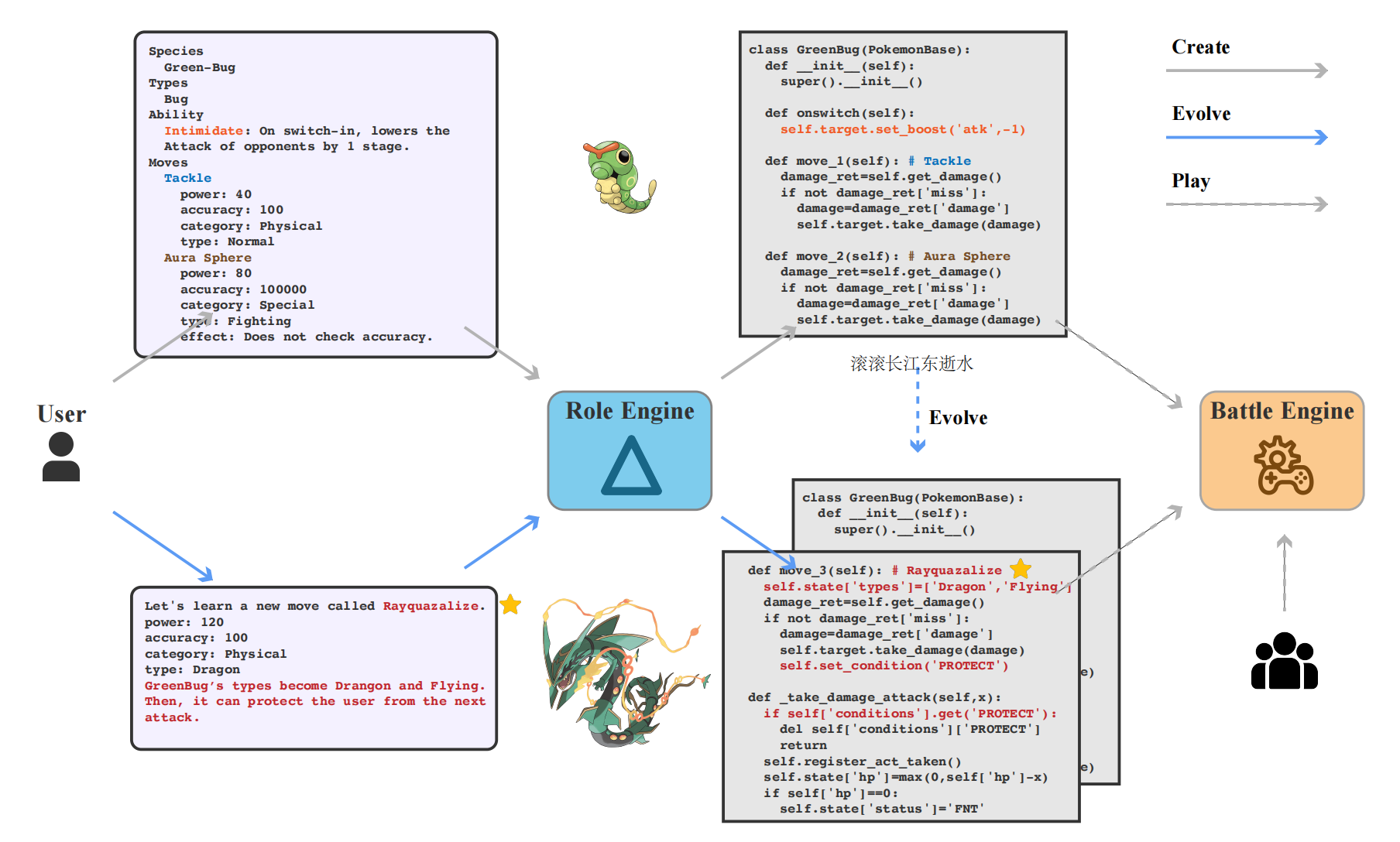
Delta-Pokémon中每一个创建的角色都对应着一个Delta-Engine。
玩家首先输入自然语言,随后会被转换成对应的角色剧本。Delta-Engine接受角色剧本生成相应的角色代码。随着角色的进化,引擎也会随之膨胀。
研究人员还提供了他们设计的一只宝可梦作为示例,它以以下剧本初始化:
{
"物种": "路卡利欧",
"属性": [
"格斗",
"钢"
],
"特性": {
"胜利之心": "上场时,该宝可梦的攻击和特攻数值变为1.25倍。"
},
"招式": {
"波导弹": {
"威力": 80,
"命中率": 100000,
"分类": "特殊",
"属性": "格斗",
"效果": "该招式必定命中。"
},
"加农光炮": {
"威力": 80,
"命中率": 100,
"分类": "特殊",
"属性": "钢",
"效果": "10%几率令目标的特防降低1级。"
}
}
}Delta-Engine的输出为:
class Lucario(PokemonBase):
def __init__(self):
super().__init__()
def onswitch(self):
# 登场时攻击和特攻变为1.25倍
self.set_stat('atk',1.25)
self.set_stat('spa',1.25)
def move_1(self): # Aura Sphere
damage_ret=self.get_damage()
if not damage_ret['miss']:
damage=damage_ret['damage']
self.target.take_damage(damage)
def move_2(self): # Flash Cannon
damage_ret=self.get_damage()
if not damage_ret['miss']:
damage=damage_ret['damage']
self.target.take_damage(damage)
# 10%几率令目标的特防降低1级
if not self.target.isfaint() and rnd()<10/100:
self.target.set_boost('spd',-1)仔细看,其实能够很轻松找到代码和上方剧本的对应关系。
onswitch对应了宝可梦的胜利之心特性,而move_1和move_2分别对应了两个招式,波导弹和加农光炮。
值得注意的是,胜利之心是研究人员原创的特性,不属于官方特性,这也是ORPG的特点之一,玩家可以自行创造自己的专属内容。
接下来关键的内容来了,研究人员再次输入:
学习一个新招式
"保护": {
"威力": 0,
"命中": 100000,
"分类": "变化",
"优先": 4,
"属性": "一般",
"效果": "在这一回合中,使用者将免受其他宝可梦的攻击。如果使用者在上一回合使用了此招式,则此招失败。"
}Delta-Engine的输出为:
@Increment(Lucario)
def move_3(self): # Protect
if self['last_act'] and self['last_act']['id']=='Protect':
return
# 设置保护状态
self.set_condition('PROTECT',counter=0)
@Increment(Lucario)
def _take_damage_attack(self,x):
# 免受其他宝可梦的攻击
if self['conditions'].get('PROTECT'):
del self['conditions']['PROTECT']
return
self.register_act_taken()
self.state['hp']=max(0,self['hp']-x)
if self['hp']==0:
self.state['status']='FNT'
@Increment(Lucario)
def endturn(self):
# 回合结束时保护消失
if self['conditions'].get('PROTECT'):
del self['conditions']['PROTECT']以上为Delta-Engine增量预测的结果,它在初始代码的基础上新增了三个类方法,来实现新的保护招式。
理论上来说,基于特定的输入,Delta-Engine可以无限制地进行这种新增,从而让角色开放式地进化。
Delta-Pokémon 是怎么做出来的?
由于Delta-Engine引入了代理模型,它的开发过程离不开对代理模型的对齐。
这个过程需要一定量、或是大量的训练数据。
而Delta-Engine所需的数据主要有两个方面:
新颖(Novelty):和其他场景类似,Delta-Engine需要新颖且多样的数据,一味重复的数据会造成性能瓶颈。
有趣(Interestingness):数据的内容上还需要做到有趣,来提升玩家的体验。然而有趣性的评估相当困难,因此他们采用了一种启发式的评估准则。
但研究人员认为大语言模型并不具有想象力,它表现出的想象力很大程度来源于指令中提供的线索。因此,仅仅靠提示大语言模型让其发挥想象力并不能获得新颖的结果。
为此他们给出了一种解决思路,即在提示中引入一段对实体的描述性文字,称之为原型。原型去显示地提示大语言模型该怎么进行联想。
例如,将霸王龙作为原型让Claude3设计一只宝可梦,Claude3于是给出了一只具备“顶级捕食者”和“泰坦之咬”特性的全新宝可梦。
有意思的是,原型不仅仅能够采自于现实世界,还能是一系列虚拟生物,例如一部分训练数据的原型取自于游戏《怪物猎人》中的冰狼龙。

除此之外,研究人员还采用了一种启发式的方法来量化一个样本的有趣性。
他们认为有趣性可以被量化为一系列潜在的可能让玩家感觉到有趣的“有趣因子”,有趣因子越多,玩家越有可能觉得有趣。
他们将这些有趣因子称为有趣性标签(Tag of Interest),需要一个标注模块来为一条样本标注出这些标签。一个样本的所有这些标签可以用一个布尔向量来表示,按照他们对有趣性的假设,向量的模越大,则有趣性越高。
研究人员因此针对宝可梦设计了一个标签集,其中包含近50种有趣性标签,例如吸血、恢复、强化等。在设计宝可梦时,其有趣性低于某一阈值的样本将被过滤。
为了满足上述两种需求,他们还采用了一种人类和大语言模型协同设计(Co-Design)的管线。
因为他们觉得虽然现在大语言模型可以全自动合成相关数据,但在构造数据的新颖程度、有趣性、以及正确性上AI始终是无法取代人类设计师的工作,而且合成数据中隐藏的巨大偏见也是一大隐患。
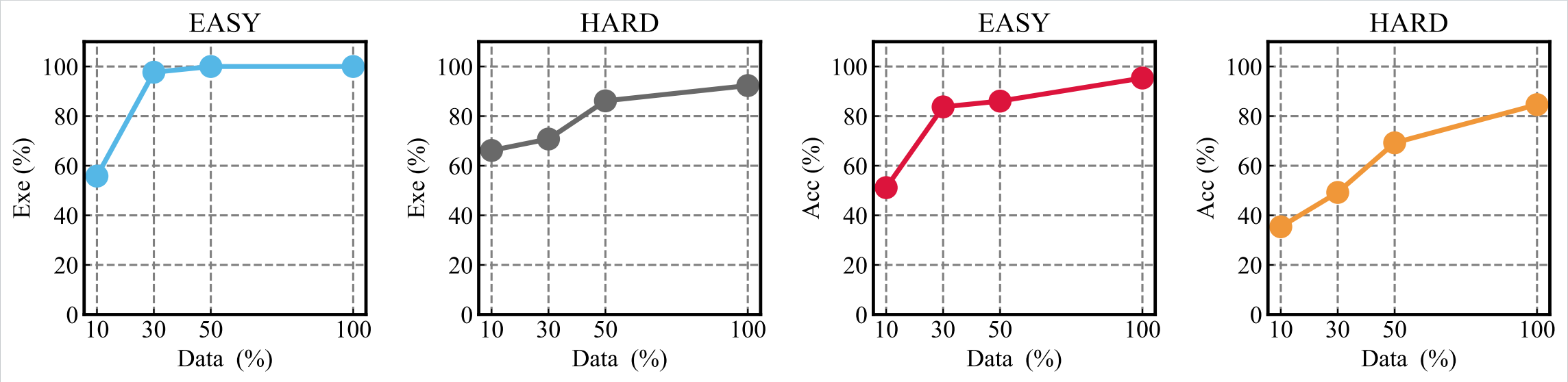
最后,研究人员给出了三种评估准则,用来全面地评估Delta-Engine的性能。
常规评估(Naive Evaluation):评估引擎的正确性,包含两个指标。
正确率(Acc):即生成的代码是否正确地实现了应有的功能。
执行率(Exe):即生成的代码是否能通过编译,不论正确与否。Exe对于用户的体验感非常重要,很多情况下,相比功能不匹配,无法正确运行会带来更强烈的负面感受。
为此他们还专门构造了“简单”和“困难”两部分的测试集。
简单部分包含了43条样本,皆来自于官方存在的宝可梦。困难部分皆为由专家撰写的原创宝可梦,数据分布和现有的宝可梦存在较大差异,总共包含了70条样本。
研究人员使用了近500条高质量训练样本来微调CodeGemma-7b,从而观察不同训练数据量下,引擎性能的变化。
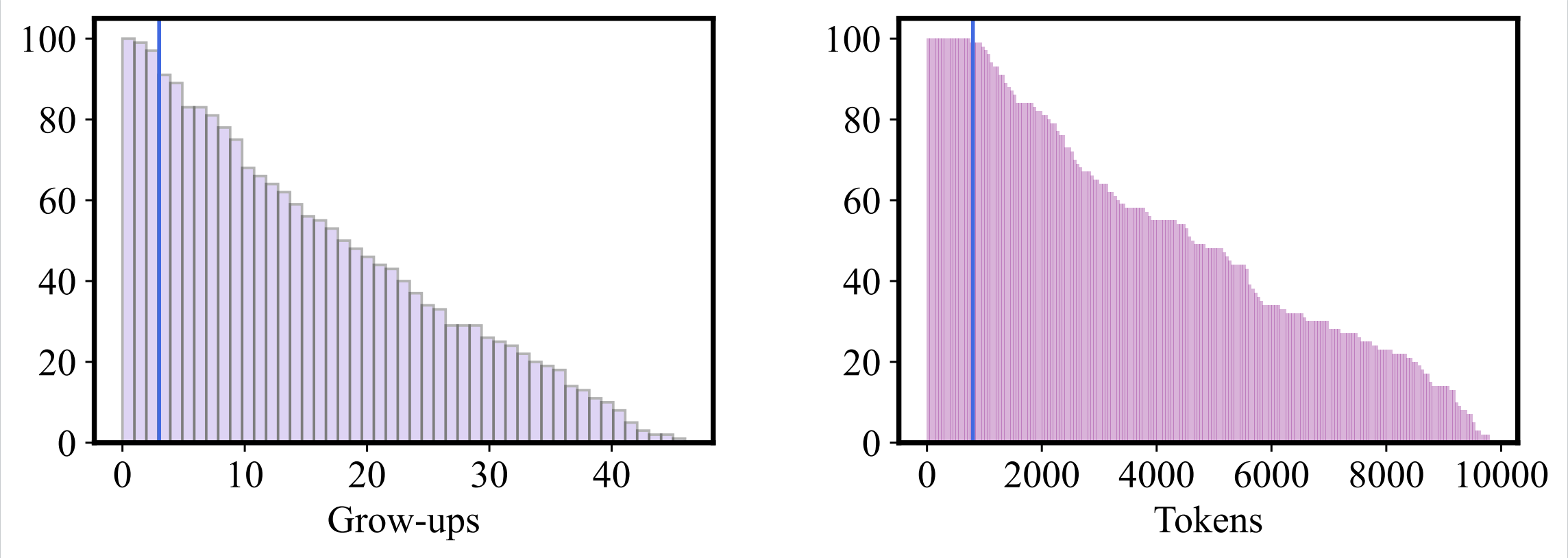
增量评估:评估Delta-Engine的性能与其内容量之间的关系。
随着引擎内容的不断膨胀,其上下文会越来越长,其性能也会遇到挑战。
研究人员通过随机缝合100只“宝可梦”,获得了一张引擎性能图。
蓝色竖线代表的是用于训练的最大输入长度。可以看到一只宝可梦进行20次进化后,上下文长度达到了5k,40次进化将达到10k。但大约在10次进化过后,引擎的增量预测性能开始了阶梯式下滑。
对此研究人员指出,代理模型的长度延展性对于Delta-Engine来说非常重要。
对抗评估:应对用户给出的非常规输入。
由于Delta-Engine带来的高度开放性,用户的大部分输入都会被允许,此时不乏有用户处于好奇和娱乐的心态,尝试输入一些稀奇古怪的内容来试探引擎。
研究人员对此表示高度理解,并将所有这类输入统称为对抗输入。在对抗评估中,引擎的执行率尤为重要,因为大部分对抗输入不存在正确解。
- 在线可玩!智谱开源图生视频模型,网友直呼Amazing!2024-09-19
- 字节AI版小李子一开口:黄风岭,八百里2024-09-13
- 小心!AI能「看懂」你的唇语,悄悄话不再安全!2024-09-12
- 机器人也会系鞋带了!斯坦福团队赋予机器人新技能丨已开源2024-09-11











