
大模型应用新战场:揭秘终端侧AI竞争关键|智在终端
底层技术驱动AI创新
鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
2024年过去2/3,大模型领域的一个共识开始愈加清晰:
AI技术的真正价值在于其普惠性。没有应用,基础模型将无法发挥其价值。
于是乎,回顾这大半年,从互联网大厂到手机厂商,各路人马都在探索AI时代Killer APP的道路上狂奔。这股风潮,也开始在顶级学术会议中显露踪迹。
其中被行业、学术界都投以关注的一个核心问题就是:
在大模型“力大砖飞”的背景之下,AIGC应用要如何在手机等算力有限的终端设备上更丝滑地落地呢?

△Midjourney生成
这段时间以来,ICML(国际机器学习大会)、CVPR(IEEE国际计算机视觉与模式识别会议)等顶会上的最新技术分享和入选论文,正在揭开更多细节。
是时候总结一下了。
AI应用背后,大家都在聚焦哪些研究?
先来看看,AI应用从云端迈向终端,现在进展到何种程度了。
目前,在大模型/AIGC应用方面,众多安卓手机厂商都与高通保持着深度合作。
在CVPR 2024等顶会上,高通的技术Demo,吸引了不少眼球。
比如,在安卓手机上,实现多模态大模型(LLaVA)的本地部署:

△Qualcomm Research发布于YouTube
这是一个70亿参数级别的多模态大模型,支持多种类型的数据输入,包括文本和图像。也支持围绕图像的多轮对话。
就像这样,丢给它一张小狗的照片,它不仅能描述照片信息,还能接着和你聊狗狗适不适合家养之类的话题。

△量子位在巴塞罗那MWC高通展台拍摄的官方演示Demo
高通还展示了在安卓手机上运行LoRA的实例。
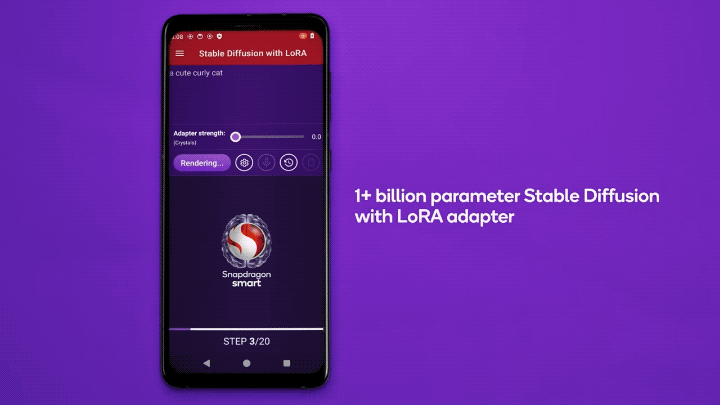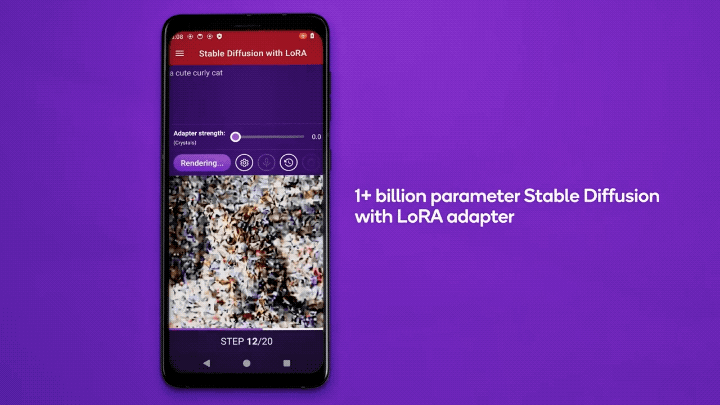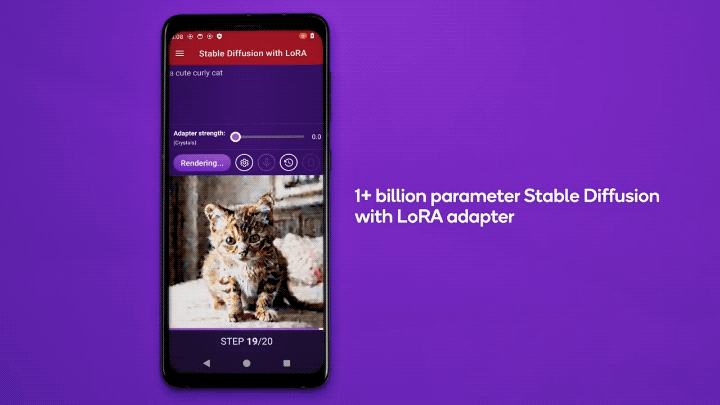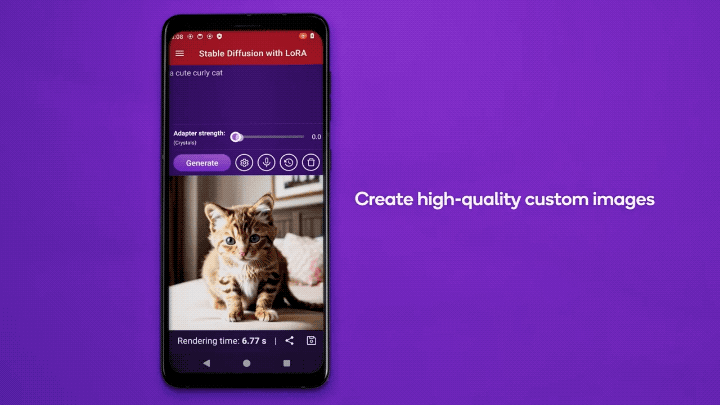
△Qualcomm Research发布于YouTube
以及音频驱动的3D数字人版AI助手——同样能在断网的情况下本地运行。
Demo原型既出,加之手机厂商们的魔改优化,对于普通用户而言,意味着其中展现的新玩法新可能,在咱们自个儿的终端设备上已经指日可待。
但在顶会上,更加受到关注的是,demo之外,高通的一系列最新论文们,还详细地揭开了应用背后需要重点布局的关键技术。
量化
其中之一,就是量化。
在手机等终端设备上部署大模型/AIGC应用,要解决的一大重点是如何实现高效能的推理。
而量化是提高计算性能和内存效率最有效的方法之一。并且高通认为,使用低位数整型精度对高能效推理至关重要。
高通的多项研究工作发现,对于生成式AI来说,由于基于Transformer的大语言模型受到内存的限制,在量化到8位(INT8)或4位(INT4)权重后往往能够获得大幅提升的效率优势。
其中,4位权重量化不仅对大语言模型可行,在训练后量化(PTQ)中同样可能,并能实现最优表现。这一效率提升已经超过了浮点模型。
具体来说,高通的研究表明,借助量化感知训练(QAT)等量化研究,许多生成式AI模型可以量化至INT4模型。
在不影响准确性和性能表现的情况下,INT4模型能节省更多功耗,与INT8相比实现90%的性能提升和60%的能效提升。

今年,高通还提出了一种名为LR-QAT(低秩量化感知训练)的算法,能使大语言模型在计算和内存使用上更高效。
LR-QAT受LoRA启发,采用了低秩重参数化的方法,引入了低秩辅助权重,并将其放置在整数域中,在不损失精度的前提下实现了高效推理。
在Llama 2/3以及Mistral系列模型上的实验结果显示,在内存使用远低于全模型QAT的情况下,LR-QAT达到了相同的性能。

另外,高通还重点布局了矢量量化(VQ)技术,与传统量化方法不同,VQ考虑了参数的联合分布,能够实现更高效的压缩和更少的信息丢失。

编译
在AI模型被部署到硬件架构的过程中,编译器是保障其以最高性能和最低功耗高效运行的关键。
编译包括计算图的切分、映射、排序和调度等步骤。
高通在传统编译器技术、多面体AI编辑器和编辑器组合优化AI方面都积累了不少技术成果。
比如,高通AI引擎Direct框架基于高通Hexagon NPU的硬件架构和内存层级进行运算排序,在提高性能的同时,可以最大程度减少内存溢出。
硬件加速
终端侧的AI加速,离不开硬件的支持。
在硬件方面,高通AI引擎采用异构计算架构,包括Hexagon NPU、高通Adreno GPU、高通Kryo CPU或高通Oryon CPU。
其中,Hexagon NPU在今天已经成为高通AI引擎中的关键处理器。

以第三代骁龙8移动平台为例,Hexagon NPU在性能表现上,比前代产品快98%,同时功耗降低了40%。
架构方面,Hexagon NPU升级了全新的微架构。与前代产品相比,更快的矢量加速器时钟速度、更强的推理技术和对更多更快的Transformer网络的支持等等,全面提升了Hexagon NPU对生成式AI的响应能力,使得手机上的大模型“秒答”用户提问成为可能。
Hexagon NPU之外,第三代骁龙8在高通传感器中枢上也下了更多功夫:增加下一代微型NPU,AI性能提高3.5倍,内存增加30%。

事实上,作为大模型/AIGC应用向终端侧迁移的潮流中最受关注的技术代表之一,以上重点之外,高通的AI研究布局早已延伸到更广泛的领域之中。
以CVPR 2024入选论文为例,在生成式AI方面,高通提出了提高扩散模型效率的方法Clockwork Diffusion,在提高Stable Diffusion v1.5感知得分的同时,能使算力消耗最高降低32%,使得SD模型更适用于低功耗端侧设备。
并且不止于手机,针对XR和自动驾驶领域的实际需求,高通还研究了高效多视图视频压缩方法(LLSS)等。
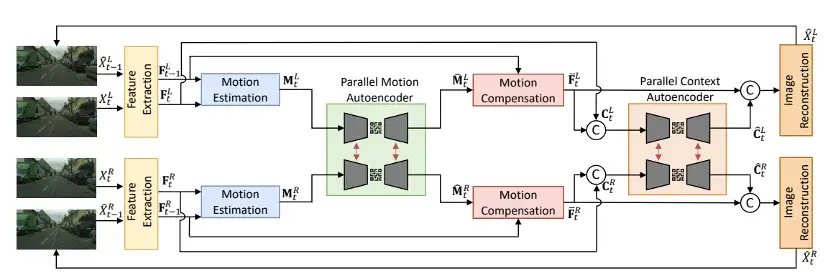
在当前的热点研究领域,比如AI视频生成方面,高通也有新动作:
正在开发面向终端侧AI的高效视频架构。例如,对视频到视频的生成式AI技术FAIRY进行优化。在FAIRY第一阶段,从锚定帧提取状态。在第二阶段,跨剩余帧编辑视频。优化示例包括:跨帧优化、高效instructPix2Pix和图像/文本引导调节。
底层技术驱动AI创新
大模型应用是当下的大势所趋。而当应用发展的程度愈加深入,一个关键问题也愈加明朗:
应用创新的演进速度,取决于技术基座是否扎实牢固。
这里的技术基座,指的不仅是基础模型本身,也包括从模型量化压缩到部署的全栈AI优化。
可以这样理解,如果说基础模型决定了大模型应用效果的上限,那么一系列AI优化技术,就决定了终端侧大模型应用体验的下限。
作为普通消费者,值得期待的是,像高通这样的技术厂商,不仅正在理论研究方面快马加鞭,其为应用、神经网络模型、算法、软件和硬件的全栈AI研究和优化,也已加速在实践中部署。

以高通AI软件栈为例。这是一套容纳了大量AI技术的工具包,全面支持各种主流AI框架、不同操作系统和各类编程语言,能提升各种AI软件在智能终端上的兼容性。
其中还包含高通AI Studio,相当于将高通所有AI工具集成到了一起,包括AI模型增效工具包、模型分析器和神经网络架构搜索(NAS)等。
更为关键的是,基于高通AI软件栈,只需一次开发,开发者就能跨不同设备随时随地部署相应的AI模型。
就是说,高通AI软件栈像是一个“转换器”,能够解决大模型在种类繁多的智能终端中落地所面临的一大难题——跨设备迁移。
这样一来,大模型应用不仅能从云端走向手机端,还能被更快速地塞进汽车、XR、PC和物联网设备中。
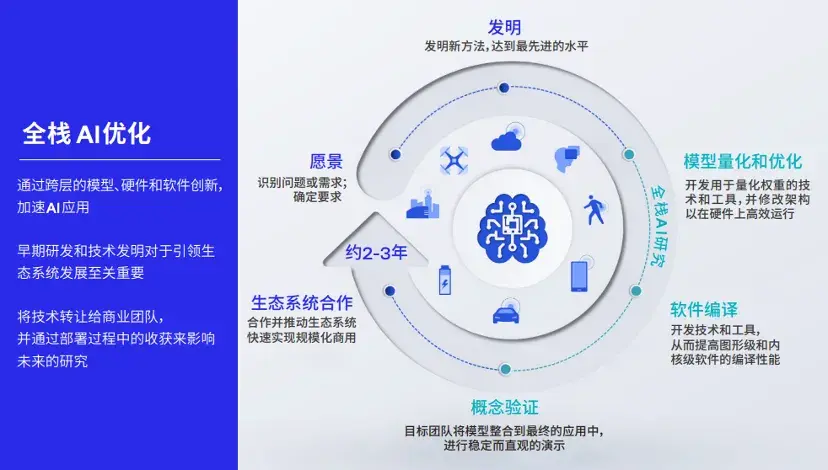
站在现在的时间节点,人人都在期待改变世界的技术潮流翻腾出更汹涌的巨浪。
而站立潮头的弄潮儿们正在再次验证技术史中一次次被探明的事实:引领技术之先的人和组织,无不具备重视基础技术的“发明家文化”。
不止是追赶最新的技术趋势,更要提前布局,抢先攻克基本方案。
高通在《让AI触手可及》白皮书中同样提到了这一点:
高通深耕AI研发超过15年,始终致力于让感知、推理和行为等核心能力在终端上无处不在。
这些AI研究和在此之上产出的论文,影响的不仅是高通的技术布局,也正在影响整个行业的AI发展。
大模型时代,“发明家文化”仍在延续。
也正是这样的文化,持续促进着新技术的普及化,促进着市场的竞争和繁荣,带动起更多的行业创新和发展。
你觉得呢?
— 完 —
- 大模型终于通关《宝可梦蓝》!网友:Gemini 2.5 Pro酷爆了2025-05-03
- 10秒生成官网,WeaveFox重塑前端研发生产力 | 蚂蚁徐达峰@中国AIGC产业峰会2025-04-30
- 粉笔CTO:大模型打破教育「不可能三角」,因材施教真正成为可能|中国AIGC产业峰会2025-04-18
- GPT-4.1淘汰了4.5!全系列百万上下文,主打一个性价比2025-04-15









