
从一大堆图片中精准找图,有新招了!论文已经中了ECCV 2024。
北京大学袁粒课题组,联合南洋理工大学实验室,清华自动化所提出了一种新的通用检索任务:通用风格检索(Style-Diversified Retrieval)。

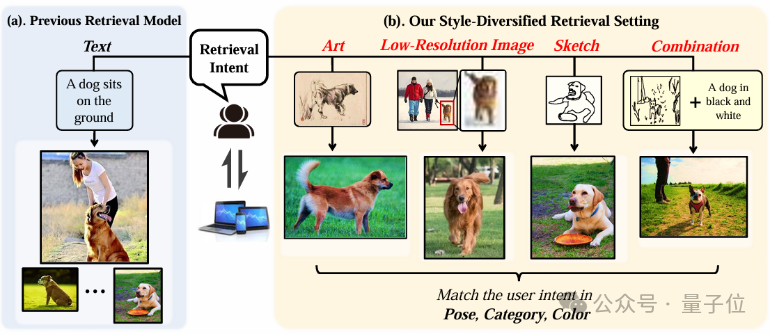
一句话,这种检索任务要求模型面对风格多样的查询条件时,依然能精准找图。
传统图片检索主要靠文本查询,查询方法单一不说,在使用其他检索方案的性能也一般。
而论文提出的新图像检索方法,能够根据多样化的查询风格(如草图、艺术画、低分辨率图像和文本等)来检索相应图像,甚至包括组合查询(草图+文本、艺术+文本等)。
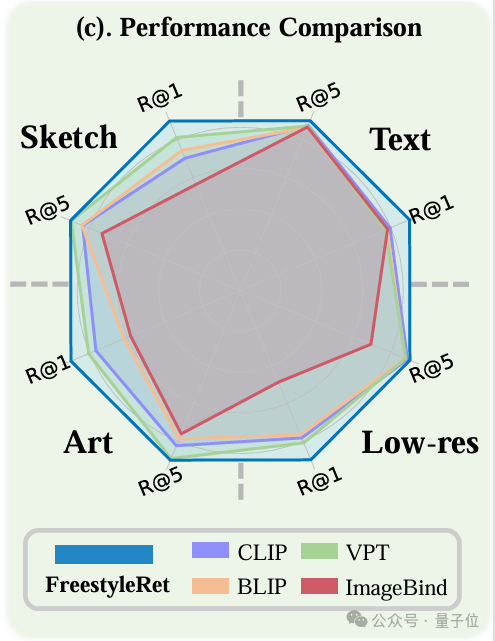
同时,模型在与其他检索基线之间的性能比较中达到SOTA。(最外围蓝色)
目前,论文已在arXiv公开,相关代码和数据集也已开源。
新图像检索方法
当前,图像检索的一大痛点是:
让检索模型具备理解多样化用户查询向量的能力
通俗点说就是,不管用户用哪种方式检索查询,最后都能命中用户想要的图像。
为了实现这一点,团队进行了两项工作:
- 构建专有的检索数据集,包括多种类型的查询图片。
- 提出即插即用的框架,使传统检索模型也能快速具有通用检索能力。
数据集构建
针对多种查询风格的图片文本检索任务,团队生成并构建了细粒度检索数据集DSR(Diverse-Style Retrieval Dataset)。
展开来说,数据集包括10,000张自然图片以及对应的四种检索风格(文本、草图、低分辨率、卡通艺术)。

其中的草图标注由FSCOCO数据集提供,卡通艺术图片和低分辨率图像由AnimateDiff生成。
同时,团队也采用ImageNet-X作为大尺寸粗粒度的多风格检索数据集。
ImageNet-X包括100万张带有各种风格标注的自然图片,相较于DSR,ImageNet-X数据集的图片更加简单,便于检索。
提出FreestyleRet框架
概括而言,FreestyleRet框架通过将图片风格提取并注入,有效解决了当前图片检索模型无法兼容不同类型的检索向量的问题。
在构建FreestyleRet框架时,团队主要考虑到两个问题:
- 如何有效地理解不同风格的查询向量的语义信息。
- 如何有效利用现有的图文检索模型,实现优秀的扩展能力。
围绕这两个核心问题,团队设计三个模块来组成FreestyleRet框架:
(1)基于格拉姆矩阵的风格提取模块用于显式提取未知查询向量的风格表征;
(2)风格空间构建模块,通过对风格表征聚类从而构建检索的风格空间,并将聚类中心作为风格的一致性表征;
(3)风格启发的提示微调模块,通过对检索模型的Transformer layer进行风格初始化的插值,实现对现有检索模型的多风格查询能力扩展。
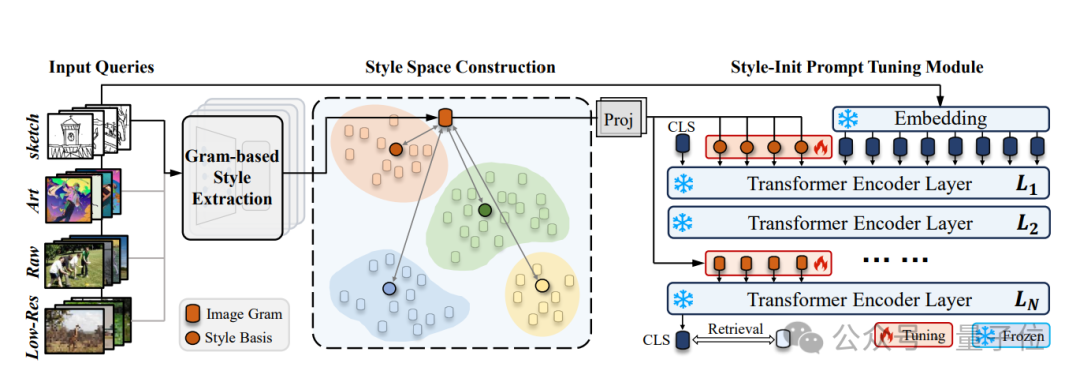
风格提取与风格空间的构建
格拉姆矩阵被验证为有效的图像风格提取方案,在本论文中团队采用基于格拉姆矩阵的风格提取模块对不同类型的查询向量进行风格提取。
团队采用冻结的VGG轻量化网络对查询向量进行表征编码,并选取浅层卷积表征作为风格提取的基特征,具体公式如下:
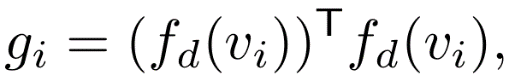
在得到查询向量对应的风格表征集合后,团队为查询向量集合构建整体的风格空间。
具体来说,采用K-Means聚类算法,迭代式的计算四种不同风格的查询向量集合对应的聚类中心,然后再对每个风格表征计算其所属的风格中心,并根据新的风格表征集合重新调整聚类中心的位置。
当聚类中心位置不再发生变化即为迭代完毕,公式如下:
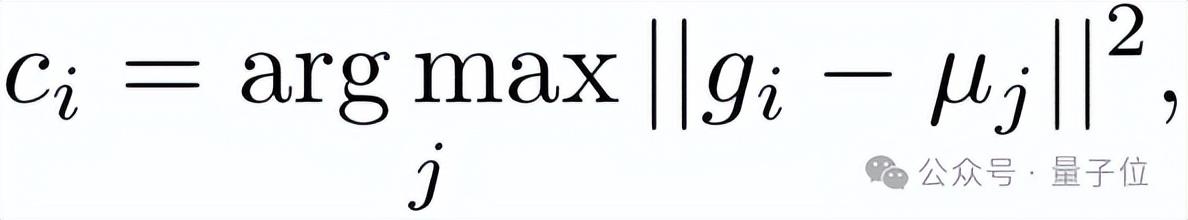
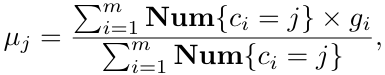
在风格空间中,团队将不同查询向量风格对应的不同聚类中心作为风格空间的基向量。
而在推理过程中面对未知风格的查询向量,风格空间将计算查询向量在基向量上的投影,通过对基向量投影与基向量的加权求和,风格空间实现对未知风格的量化。
高效风格注入的提示微调模块
在图像文本检索领域,基于Transformer结构的ALBEF, CLIP, BLIP等基础检索模型受到广泛的使用,很多下游工作采用了这些基础检索模型的编码器模块。
为了让FreestyleRet框架能够便捷且高效的适配这些基础检索模型,团队采用风格表征初始化的token对基础编码器的Transformer结构进行提示微调。
具体来说,在encoder layer的每层都插入使用量化风格表征初始化的可学习token,从而实现风格向编码器注入的流程。
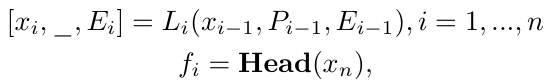
实验性能展示
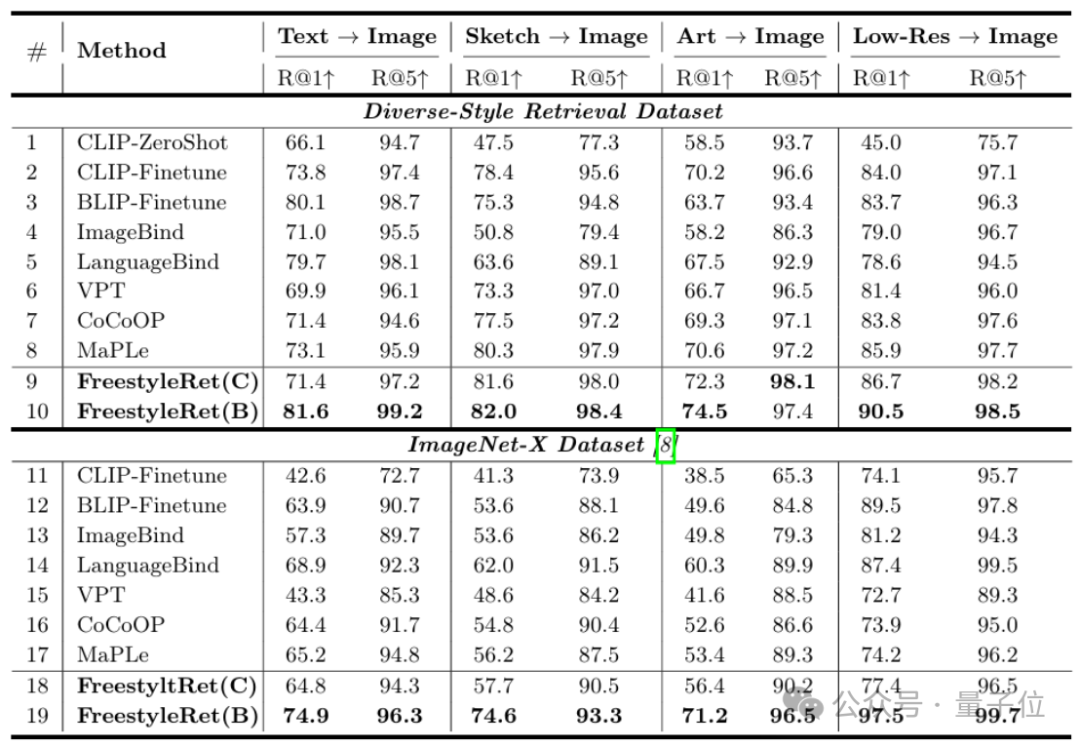
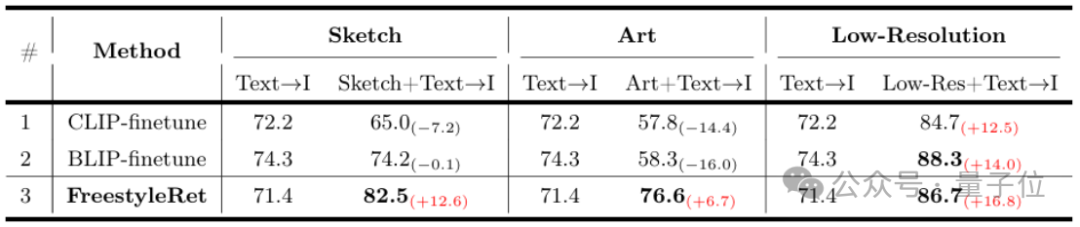
在定量实验角度,团队分析了基于FreestyleRet架构的BLIP和CLIP模型在DSR数据集以及ImageNet-X数据集的Recall@1, Recall@5性能。
实验证明,面对多种风格的查询向量时,FreestyleRet框架可以显著增强现有检索模型的泛化能力,具有2-4%的提升。
而团队也进一步验证FreestyleRet框架对于多个不同风格的查询向量共同输入的性能,共同输入的查询向量可以进一步提升模型的检索精度。
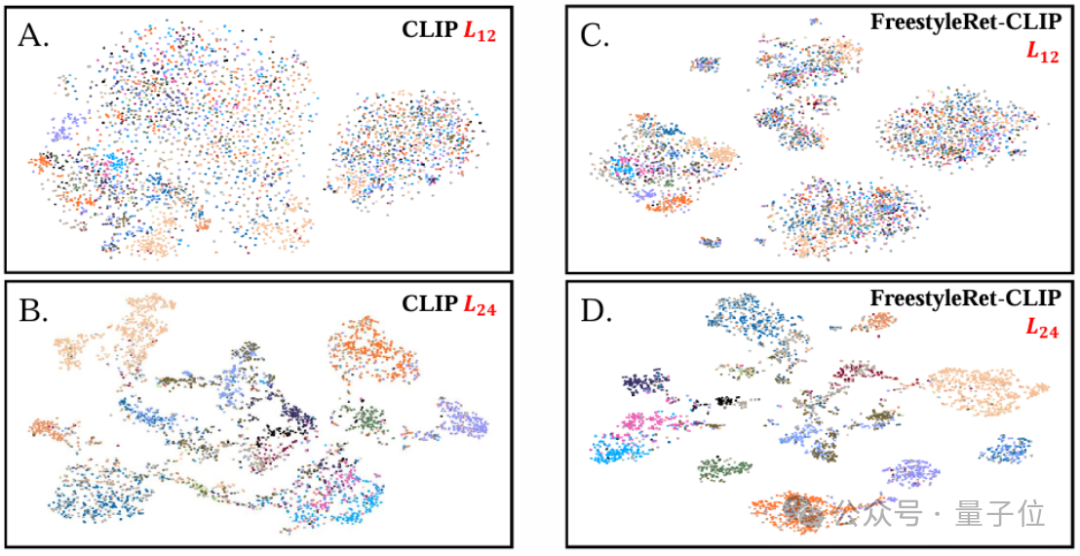
通过对特征分布进行可视化,团队发现使用FreestyleRet结构的基础检索模型能够有效分离查询向量中的风格信息与语义信息,并实现语义角度的高维空间聚类。
团队也对实际的检索推理流程进行了示例的可视化,以验证模型的泛化性。
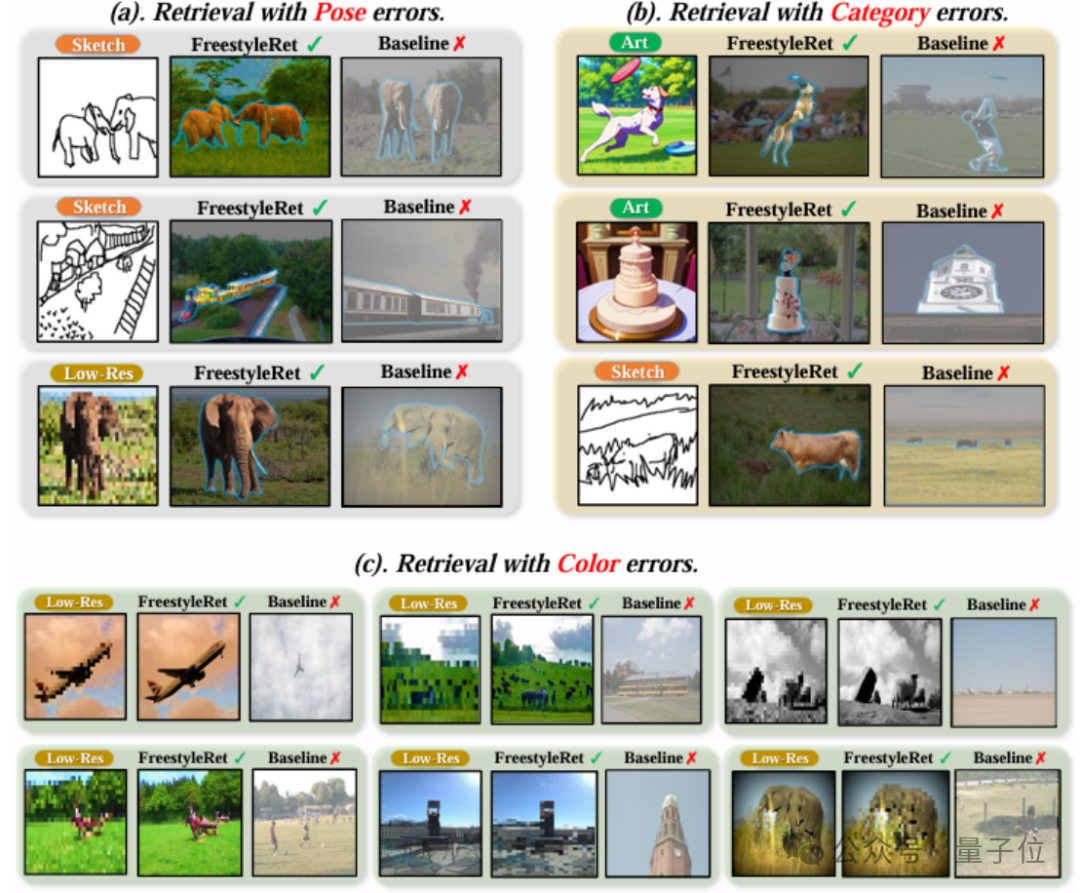
总之,模型在5种不同类型的检索向量上都取得了良好效果,而且还在多种检索向量共同检索的子任务上表现了良好的扩展性。
更多详情欢迎查阅原论文。










