
不花一分钱!GPT-4o微调限时免费开放,每日附赠百万训练token
免费时间截止到9月23日
一觉醒来,OpenAI又上新功能了:
GPT-4o正式上线微调功能。
并且官方还附赠一波福利:每个组织每天都能免费获得100万个训练token,用到9月23日。

也就是说,开发人员现在可以使用自定义数据集微调GPT-4o,从而低成本构建自己的应用程序。
要知道,OpenAI在公告中透露了:
GPT-4o微调训练成本为每100万token 25 美元(意味着每天都能节省25美元)
收到邮件的开发者们激动地奔走相告,这么大的羊毛一定要赶快薅。

使用方法也很简单,直接访问微调仪表盘,点击”create”,然后从基本模型下拉列表中选择gpt-4o-2024-08-06。
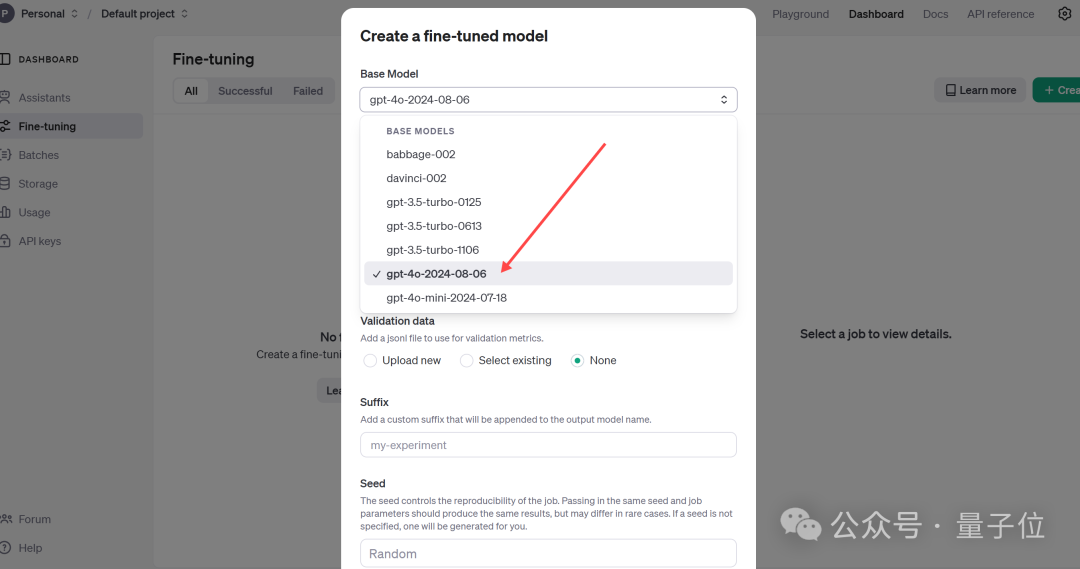
对了,OpenAI还提到,只需训练数据集中的几十个示例就可以产生良好效果。

还晒出了成功案例
消息公布后,一众网友跃跃欲试,表示很想知道模型微调后的实际效果。
OpenAI官方早有准备,随公告一同发布了合作伙伴微调GPT-4o的实际案例。
首先是一款代码助手Genie,来自AI初创公司Cosine,专为协助软件开发人员而设计。
据Cosine官方介绍,Genie的开发过程采用了一种专有流程,使用数十亿个高质量数据对非公开的GPT-4o变体进行了训练和微调。
这些数据包括21%的JavaScript和Python、14%的TypeScript和TSX,以及3%的其他语言(包括Java、C++和Ruby)。
经过微调,Genie在上周二OpenAI全新发布的代码能力基准测试SWE-Bench Verified上,取得了43.8%的SOTA分数。
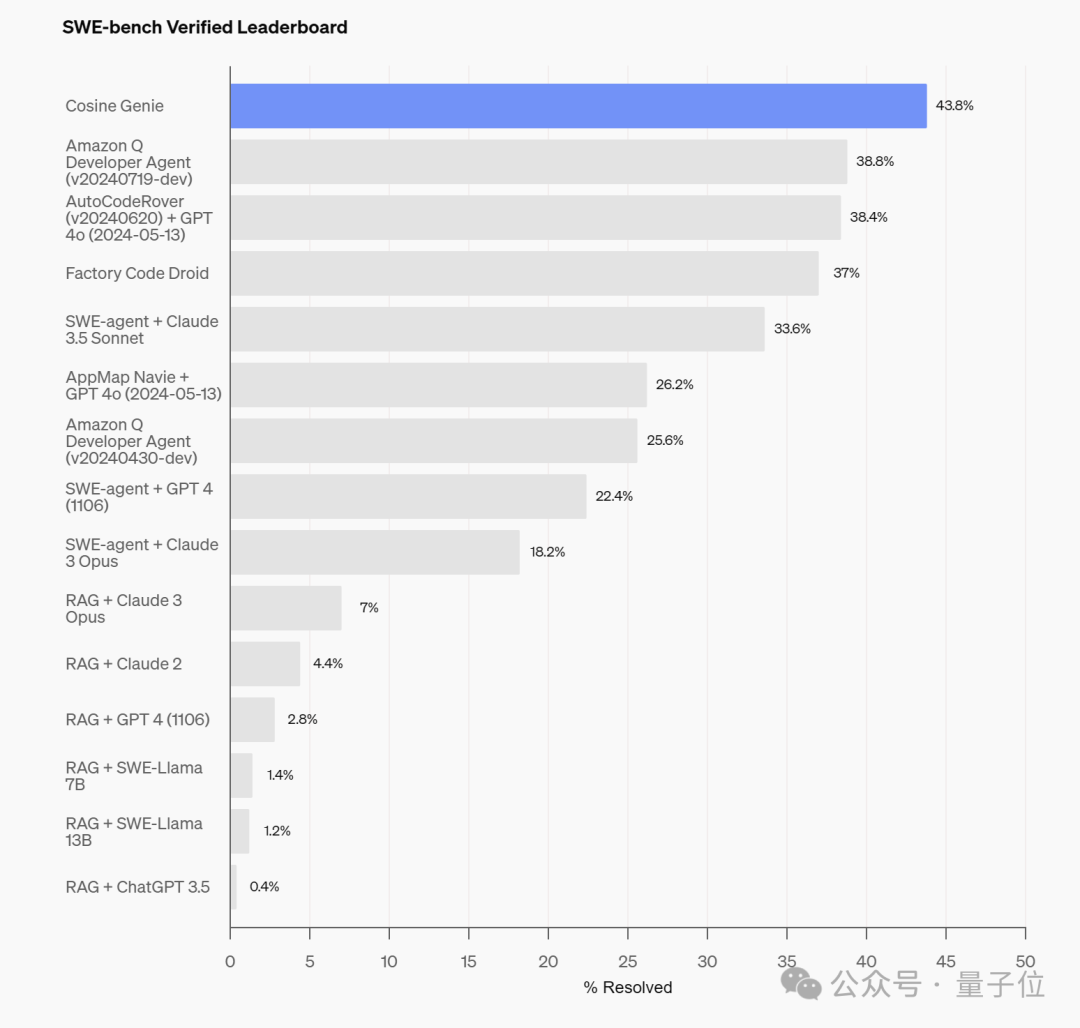
与此同时,Genie还在SWE-Bench Full上的SOTA分数达到了30.08%,破了之前19.27%的SOTA纪录。
相较之下,Cognition的Devin在SWE-Bench的部分测试中为13.8%。
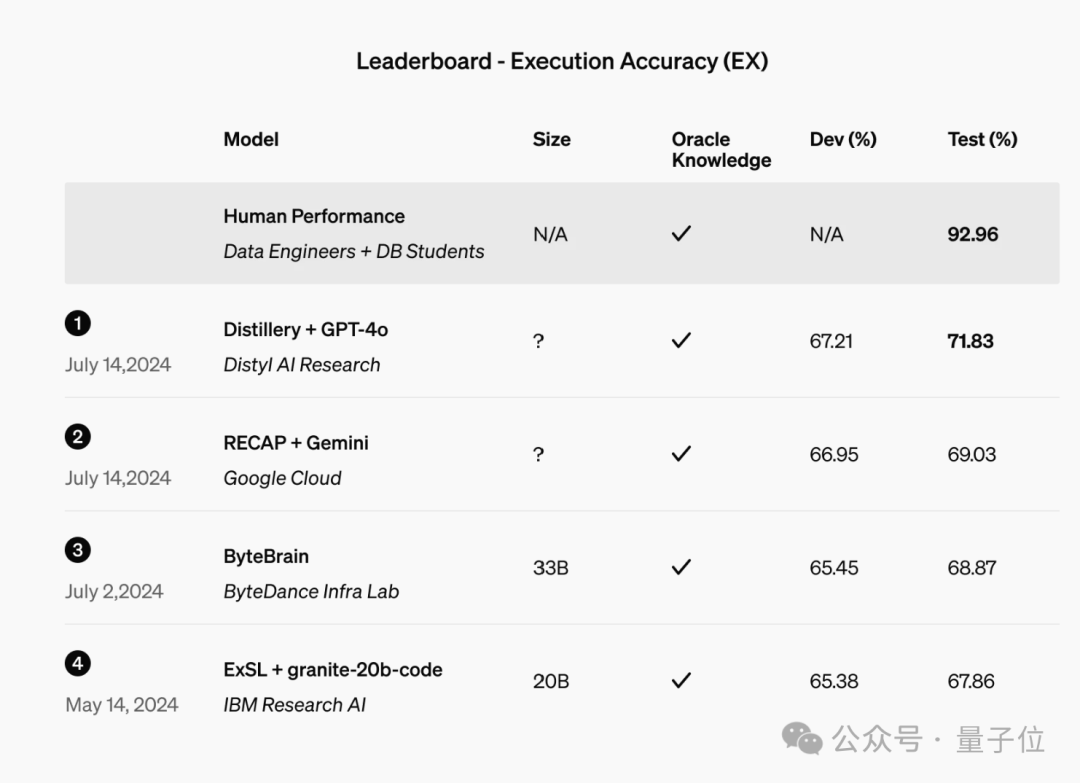
另一个案例来自Distyl,这是一家为财富500强企业提供AI解决方案的公司,最近在领先的文本到SQL基准测试BIRD-SQL中排名第一。
经过微调,其模型在排行榜上实现了71.83%的执行准确率,并在查询重构、意图分类、思维链和自我纠正等任务中表现出色,尤其是在SQL生成方面表现尤为突出。
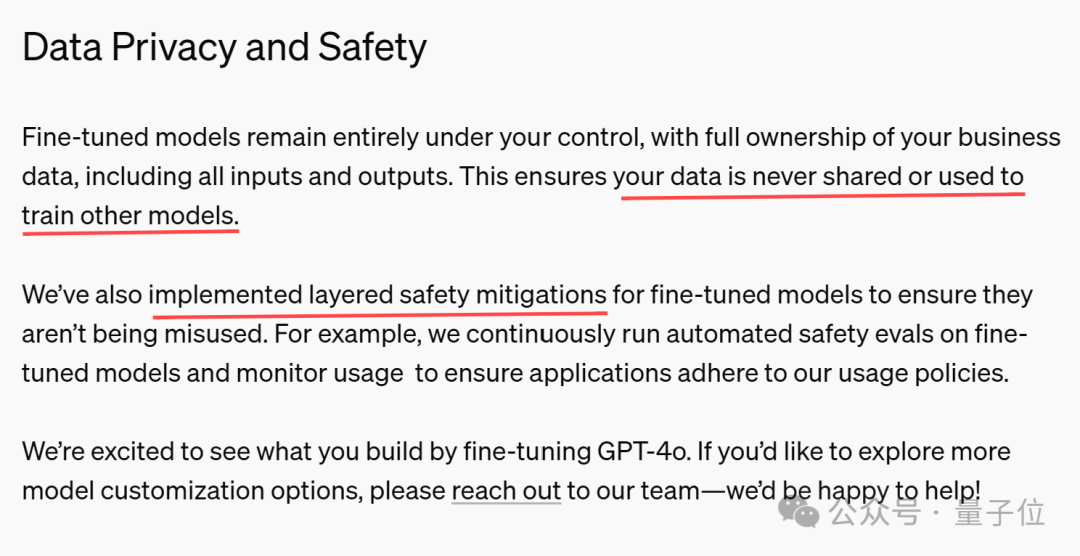
除了提供案例,OpenAI还在公告中特意强调了数据隐私和安全问题,总结下来就是:
开发者的业务数据(包括输入和输出)不会被共享或用于训练其他模型。
针对微调模型实施了分层安全缓解措施,例如不断对微调模型运行自动安全评估并监控使用情况。
网友:微调比不上提示词缓存
一片热闹之际,有网友认为微调仍然比不上提示词缓存。
微调很酷,但它仍然不如提示词缓存……
之前量子位也介绍过,提示词缓存的作用,就是一次给模型发送大量prompt,然后让它记住这些内容,并在后续请求中直接复用,避免反复输入。
今年5月,谷歌的Gemini就已经支持了提示词缓存,Claude也在上周上新了这项功能。
由于不需要反复输入重复的脚本,提示词缓存具有速度更快、成本更低这两大优势。
有网友认为,提示词缓存功能对开发者更友好(无需异步微调),且几乎可以获得与微调相同的好处。
提示词缓存可以让您付出1%的努力获得99%的好处。

不过也有人给微调打call,认为微调在塑造响应方面更有效。例如确保JSON格式正确、响应更简洁或使用表情符号等。

眼见OpenAI的竞争对手们相继用上了提示词缓存,还有人好奇了:
想知道OpenAI是否会坚持微调或转向提示词缓存(或两者兼而有之)。
对于这个问题,有其他网友也嗅出了一些蛛丝马迹。
OpenAI在其延迟优化指南中提到了缓存技术。
我们也第一时间找了下指南原文,其中在谈到如何减少输入token时提到:
通过在提示中稍后放置动态部分(例如RAG结果、历史记录等),最大化共享提示前缀。这使得您的请求对KV缓存更加友好,意味着每个请求处理的输入token更少。

不过有网友认为,仅根据这一段内容,无法直接推出OpenAI采用了提示词缓存技术。
BTY,抛开争议不谈,OpenAI的羊毛还是得薅起来~
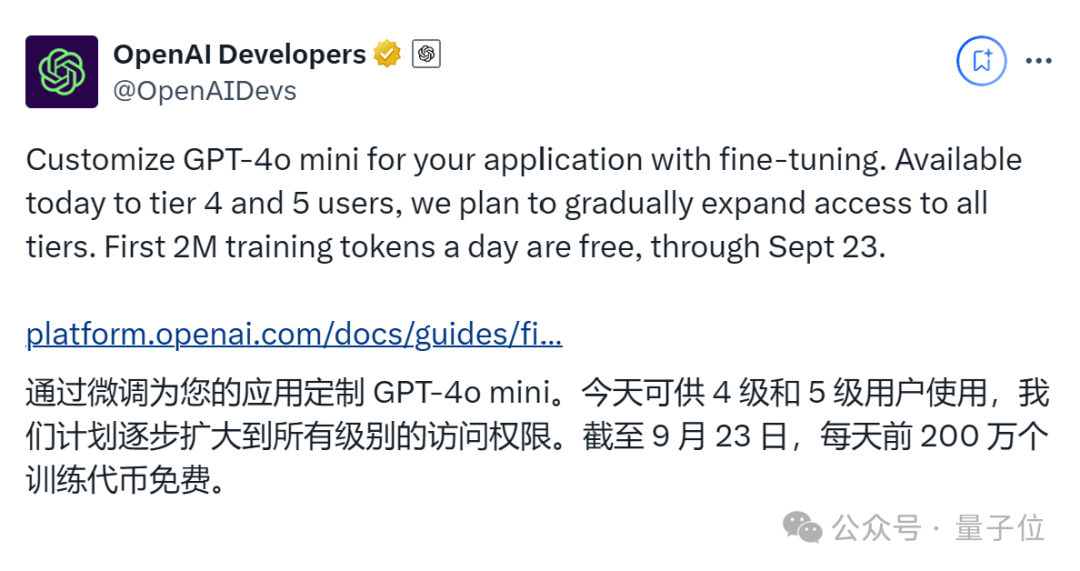
除了GPT-4o,还可以免费微调GPT-4o mini,9月23日之前OpenAI免费提供每天200万个训练token。
- 轻松健康集团高玉石:AI产品和用户走得够近才能挖到新需求丨中国AIGC产业峰会2025-04-23
- AI火花集|10位AI火花先锋揭晓,看AI应用如何“改写”商业世界?2025-04-17
- 中杯o3成OpenAI“性价比之王”?ARC-AGI测试结果出炉:得分翻倍、成本仅1/202025-04-23
- 人形机器人半马冠军,为什么会选择全尺寸?2025-04-20











